







 Cycle GAN是一种无需配对训练数据的图像到图像转换方法,利用循环一致性损失解决监督不足的问题,适用于风格迁移、对象变形等任务。与pix2pix相比,Cycle GAN具有更强的泛化能力。
Cycle GAN是一种无需配对训练数据的图像到图像转换方法,利用循环一致性损失解决监督不足的问题,适用于风格迁移、对象变形等任务。与pix2pix相比,Cycle GAN具有更强的泛化能力。
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
pix2pix和Cycle GAN都是做风格迁移,出自同一个团队,区别在于pix2pix需要成对数据集,而Cycle GAN引入循环一致性损失之后不需要成对数据了,泛化能力更强。
论文地址:https://arxiv.org/pdf/1703.10593.pdf
代码地址:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
摘要:图像到图像的转换是一类视觉和图形问题,其目标是使用对齐的图像对训练集来学习输入图像和输出图像之间的映射。但是,对于许多任务,配对的训练数据将不可用。我们提出了一种在没有配对示例的情况下学习将图像从源域X转换为目标域Y的方法。我们的目标是学习一个映射G:X→Y,使得来自G(X)的图像分布与D的分布使用对抗损失是无法区分的。由于此映射的约束严重不足,因此我们将其与反映射F:Y→X耦合,并引入循环一致性损失以强制执行F(G(X))≈X(反之亦然)。定性结果在不存在配对训练数据的多个任务上显示,包括集合样式转移,对象变形,季节转移,照片增强等。与几种先前方法的定量比较证明了我们方法的优越性。
1 Introduction
在本文中,我们提出了一种方法,该方法可以学会做同样的事情:在没有任何配对训练示例的情况下,捕获一个图像集合的特殊特征并弄清楚如何将这些特征转化为另一个图像集合。

这个问题可以更广泛地描述为图像到图像的转换[22],将图像从给定场景x的一种表示,转换为另一种y,例如,将灰度转换为颜色,将图像转换为语义标签,将边缘映射转换为照片。 在计算机视觉,图像处理,计算摄影和图形学方面的研究已经在有监督的环境下产生了功能强大的翻译系统,其中示例图像对 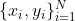 是可用的(图2,左),例如[ 11、19、22、23、28、33、45、56、58、62]。但是,获得配对的训练数据可能既困难又昂贵。例如,仅存在用于语义分割等任务的几个数据集(例如[4]),并且它们相对较小。由于所需的输出非常复杂,通常需要艺术创作,因此要获得图形任务(例如艺术风格)的输入输出对可能会更加困难。对于许多任务,例如对象变形(例如,斑马,图1居中),所需的输出甚至都没有明确定义。
是可用的(图2,左),例如[ 11、19、22、23、28、33、45、56、58、62]。但是,获得配对的训练数据可能既困难又昂贵。例如,仅存在用于语义分割等任务的几个数据集(例如[4]),并且它们相对较小。由于所需的输出非常复杂,通常需要艺术创作,因此要获得图形任务(例如艺术风格)的输入输出对可能会更加困难。对于许多任务,例如对象变形(例如,斑马,图1居中),所需的输出甚至都没有明确定义。
因此,我们寻求一种无需对输入/输出示例进行配对即可学会在域之间进行翻译的算法(图2右)。我们假设域之间存在某种潜在的关系,例如,它们是同一基础场景的两个不同渲染-并试图学习这种关系。尽管我们缺乏成对示例形式的监督,但是我们可以在集合级别利用监督:我们在域X中获得了一组图像,在域Y中获得了一组不同的图像。我们可能会训练映射G:X→Y,这样输出的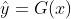 ,x∈X,使得判别器无法区分
,x∈X,使得判别器无法区分  和
和  。从理论上讲,这个目标可以在 上引起一个与经验分布
。从理论上讲,这个目标可以在 上引起一个与经验分布 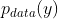 匹配的输出分布(通常,这要求G是随机的)[16]。最优的G从而将域 X 转换成与 Y 相同分布的域
匹配的输出分布(通常,这要求G是随机的)[16]。最优的G从而将域 X 转换成与 Y 相同分布的域  。但是,这样的转换并不能保证单个输入x和输出y以有意义的方式配对:无限多个映射G会在y上产生相同的分布。此外,在实践中,我们发现很难单独优化对抗目标:标准程序通常会导致众所周知的模式崩溃问题,其中所有输入图像都映射到同一输出图像,并且优化无法取得进展[15] 。
。但是,这样的转换并不能保证单个输入x和输出y以有意义的方式配对:无限多个映射G会在y上产生相同的分布。此外,在实践中,我们发现很难单独优化对抗目标:标准程序通常会导致众所周知的模式崩溃问题,其中所有输入图像都映射到同一输出图像,并且优化无法取得进展[15] 。
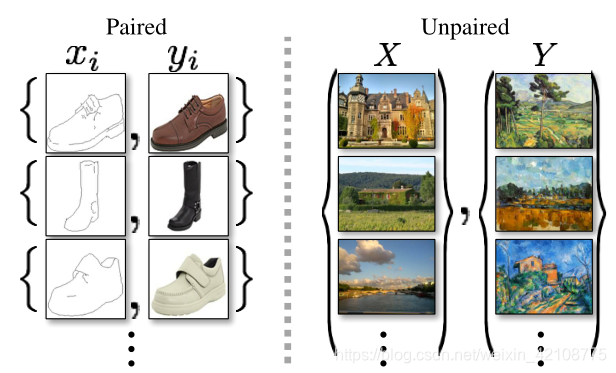
图2:配对的训练数据(左)由训练示例 组成,其中 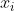 和
和 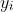 之间存在对应关系[22]。我们改为考虑不成对的训练数据(右),它由源集
之间存在对应关系[22]。我们改为考虑不成对的训练数据(右),它由源集 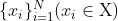 和目标集
和目标集 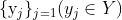 组成,但没有关于哪个
组成,但没有关于哪个 对应哪个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









