







需求
最近在做一个批量数据导入到MySQL数据库的功能,从批量导入就可以知道,这样的数据在插入数据库之前是不会进行重复判断的,因此只有在全部数据导入进去以后在执行一条语句进行删除,保证数据唯一性。
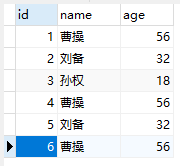
表结构
实现SQL
通过分组统计出数据库中不重复的最小数据id编号,让后通过 not in 去删除其他重复多余的数据
delete from `user`
where id not in (select id from (select min(id) as id from `user` group by `name`) t)
表结构及数据SQL
-- ----------------------------
-- Table structure for user
-- ----------------------------
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`age` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES (1, '曹操', 56);
INSERT INTO `user` VALUES (2, '刘备', 32);
INSERT INTO `user` VALUES (3, '孙权', 18);
INSERT INTO `user` VALUES (4, '曹操', 56);
INSERT INTO `user` VALUES (5, '刘备', 32);
INSERT INTO `user` VALUES (6, '曹操', 56);















 1307
1307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











