






实践出真知。
在开篇说这么一句话的意思是,没有绝对的优化之道,所有的优化建议都建立在实践应用上。
在MySQL的逻辑结构中,我们剖析了逻辑结构中各部分的功能,所以,我们给出的优化建议也是按照三部分来提出。
一、开启缓存绝对能提高查询效率吗?
不能。为什么?
缓存中存储的是什么?热点数据(需要经常用到的,并且数据量不大)。在平常的项目开发中,我们使用缓存的方式不外乎是这样子:
执行查询--->去缓存查询是否命中-->命中-->返回。
执行查询--->去缓存查询是否命中-->未命中-->获取底层数据-->返回。
使用缓存的成本在于:
①任何的查询语句,不管是否能命中,都要去缓存中查询一次。缓存的语句中任何一点细微的变动(如注释不一样,多了个空格等)都会导致未命中。
②如果结果可以缓存,在逻辑结构中有一步是将结果缓存,只要是操作,系统都会为其分配相应的资源,包括空间等。
③任何写操作,MySQL都会将相应的表对应的缓存置为无效。
④如果缓存中涉及的表,数据和结构发生了变化,那么和这张表相关的缓存全部失效。
何时我们可以使用缓存?
当我们评估,使用缓存带来的性能提升大于自身的资源消耗时,可以使用。
二、使用索引一定会提高查询效率吗?
答案是不一定。一般我们的建议是创建高性能的索引。什么是高性能的索引?这就要涉及到存储引擎中存储数据的方式说起。我们建立索引的初衷是希望MySQL在做数据检索时,能快速定位到数据。那MySQL中的索引是如何实现的?
这里就要涉及到数据结构了。在选择作为数据存储结构的时候,专家们想的是什么?当然是效率高,查找快(要不然没啥意义)。专家们经过研究,能作为索引的有下面几种存储结构:

在这些可以作为索引的数据结构中,Binary Search Tree(二叉查找树,也叫二叉排序树-Binary Sort Tree)的查找效率已经比较高,学过数据结构的都知道,它查找的时间复杂度是O(logn),查找速度和比较次数已经算优秀的了。为什么还要用B+ Tree去做索引?我们比较一下二叉查找树和B+ Tree的特点。
1、二叉查找树
特点:它是一种经典的数据结构,其左子树的值总是小于根的值,右子树的值总是大于根的值。
只要满足这一特点的都是二叉树。因此同样的数值,可能会构造出两种不同结构的树。
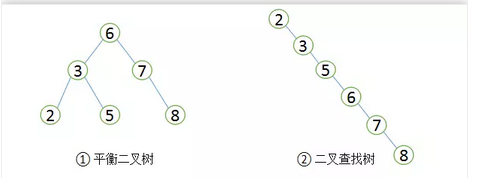
我们比较一下这两种结构的二叉树的查询效率:
以上述数据为例:
第一种是经过旋转平衡的二叉树,查找的平均次数为:(3 + 3 + 3 + 2 + 2 + 1) / 6 = 2.3次。
第二种未经过旋转,查找的平均次数为:(1 + 2 + 3 + 4 + 5 + 6) / 6 = 3.3次。
因此,若想二叉树的查询效率最高,必须经过旋转平衡,也就是构造出AVL 树(是以发表论文的那帮外国人起的Georgy Adelson-Velsky and Evgenii Landis' tree,named after the inventors ,就是平衡二叉查找树)。
AVL树在原二叉树的结构上又增加了自己的特点:
首先需要符合二叉查找树的定义;
其次必须满足任何节点的两个子树的高度差不能大于 1。(这就需要通过不停的旋转来维护树平衡)
如上图中①,就是一个平衡二叉树。
从上分析,我们可以看到,平衡二叉树的构造也比较简单,维护成本还可接受(除了插入数据需要旋转平衡外),性能也比较好,但是为什么MySQL没有选择它作为索引呢?
这里主要考虑的是磁盘的IO次数(磁盘读取依靠的是机械运动,分为寻道时间、旋转延迟、传输时间三个部分,这三个部分耗时相加就是一次磁盘IO的时间,大概9ms左右。这个成本是访问内存的十万倍左右)。我们知道不管是数据库的索引还是数据,当数据量很大的时候,索引的大小也随着增加,不可能全部放在内存中,因此索引都是以索引文件的形式保存在磁盘中。当我们利用索引进行数据查询时,不可能把所有的索引一次性都读取到内存中,只能一次读取一个磁盘页。
我们可以想象一下,当数据量很庞大的时候,树的深度会大到无可想象,磁盘IO的耗时不可想象,根本慢到无法接受。那如何减少磁盘IO呢?人总是聪明的,你二叉不是只能两个叉吗,我多加几个叉,树的深度是不是会小很多。B树和B+树正是基于这个理念,将二叉树变为了m叉树,这样从二叉查找树就变成了m叉查找树。
2、B+ Tree和B Tree
要想知道为什么最后选择了B+Tree作为索引的数据结构,我们就得明白这B树和B+树有什么不同。
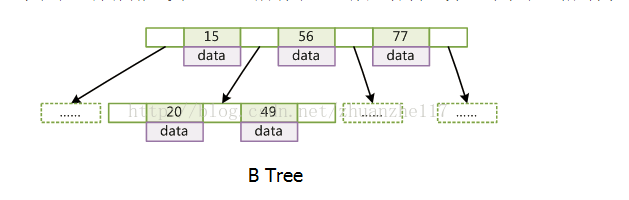
B树:
特点:每个节点(注意是每个节点)都存储key和data,所有节点组成这棵树,但是叶子节点是没有指针的。
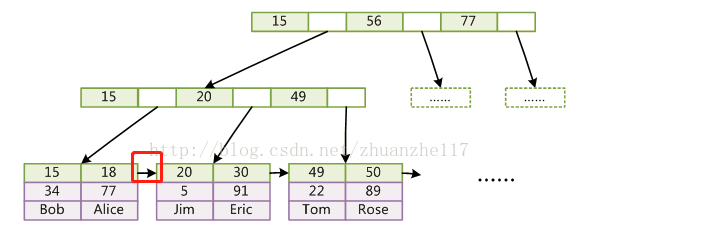
B+树:
特点:只有叶子节点存储data,叶子节点包含了这棵树的所有key值,叶子节点之间增加顺序访问指针(也就是每个叶子节点增加一个指向相邻叶子节点的指针)。
为什么最后选择了B+树作为索引的数据结构呢?我们这里就可以给出答案。
B+树的内节点不再存储数据,所有的数据节点都放在了叶子节点处,这样就有一个好处,在空间一定的情况下,原来的非叶子节点可以存储更多的内节点(把原来的数据节点也存储了内节点)。最巧妙的是,MySQL将节点大小设计为跟磁盘页大小一致。结合磁盘预读原理,我们可以一次性读取出更多的内节点,在进行搜索比较时候,是不是就节省了磁盘IO的开销。
那什么是磁盘预读原理?
页是计算机管理存储器的逻辑块,硬件及 OS 往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(许多操作系统 中,页的大小通常为 4K)。主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,在读取的起始地址连续读取多个页面(现在不需要的页面也读取了,这样以后用时就不用再读取,当一个页面用到时,大多数情况下,它周围的页面也会被用到)。
在MySQL中,最常用的两个存储引擎是MySIAM和InnoDB,它们对索引的实现方式是不同的。
MySIAM:在使用MySIAM存储引擎时,表数据文件和表索引文件是分开存储的。每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。*.frm文件存储表定义, 数据文件的扩展名为*.MYD (MYData),索引文件的扩展名是*.MYI (MYIndex)

从下图中我们就可以看出,在存储data的叶子节点中,存储的是指向数据节点的索引地址。
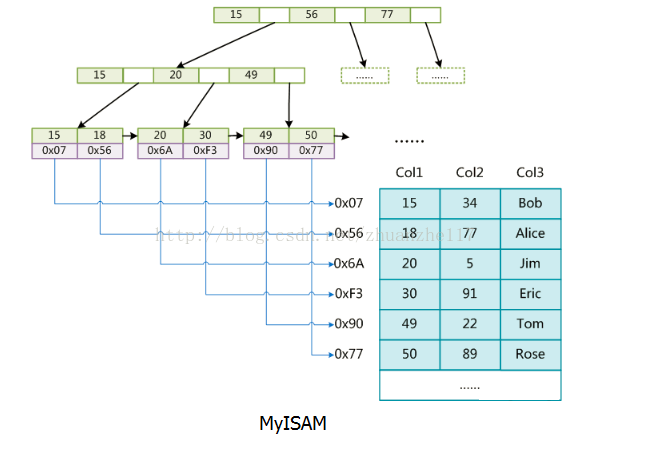
InnoDB:数据和索引是合并存储在data叶子节点中的。frm是表结构文件,idb是表数据文件。

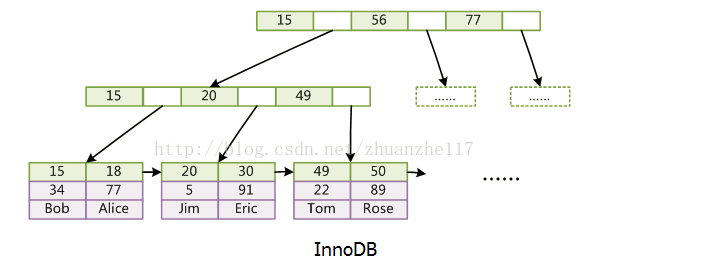
说完MySQL存储引擎的数据结构,就必须说说如何建立索引才是高效的。可能大家会想我建立多个索引,然后让它哪个快走哪个,事实是不是这样子?不是。为什么?因为MySQL根本不知道哪个索引的查询效率更好。在MySQL 5.0 之前,MySQL会随便选择一个列的索引,而新的版本会采用合并索引的策略。
索引合并策略
当出现多个索引做相交操作时(多个 AND 条件),通常来说一个包含所有相关列的索引要优于多个独立索引。
当出现多个索引做联合操作时(多个 OR 条件),对结果集的合并、排序等操作需要耗费大量的 CPU 和内存资源,特别是当其中的某些索引的选择性不高,需要返回合并大量数据时,查询成本更高。所以这种情况下还不如走全表扫描。
因此 explain 时如果发现有索引合并(Extra 字段出现 Using union),应该好好检查一下查询和表结构是不是已经是最优的。如果查询和表都没有问题,那只能说明索引建的非常糟糕,应当慎重考虑索引是否合适,有可能一个包含所有相关列的多列索引更适合。前面我们提到过索引如何组织数据存储的,从图中可以看到多列索引时,索引的顺序对于查询是至关重要的。很明显应该把选择性更高的字段放到索引的前面,这样通过第一个字段就可以过滤掉大多数不符合条件的数据。
那我们如何选择索引呢?这里涉及到一个计算方法:索引选择性。
索引选择性是指不重复的索引值和数据表的总记录数的比值,选择性越高查询效率越高,因为选择性越高的索引可以让 MySQL 在查询时过滤掉更多的行。唯一索引的选择性是 1,这是最好的索引选择性,性能也是最好的。
比如:
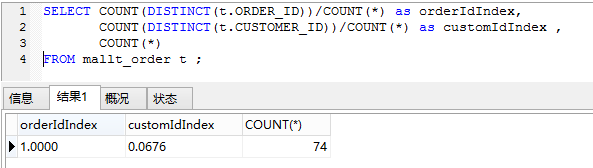
SELECT customId,orderId FROM mallt_order WHERE customId = '12' and orderId = '0836748478484'。
我们是选择customId作为索引还是使用orderId作为索引?根据索引选择算法,我们可以执行一条语句,选择性越接近1的就是适合作为索引的。从下图我们就知道,选择orderId作为索引是最好的。
常见的索引优化手段:
①避免多个范围条件
②删除长期未使用的索引
③删除冗余重复索引:比如有一个索引(A,B),再创建索引(A)就是冗余索引。
三、MySQL常用的优化手段
1、优化关联查询
要理解优化关联查询的第一个技巧,就需要理解 MySQL 是如何执行关联查询的。
当前 MySQL 关联执行的策略非常简单,它对任何的关联都执行嵌套循环关联操作,即先在一个表中循环取出单条数据,然后在嵌套循环到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为为止。然后根据各个表匹配的行,返回查询中需要的各个列。
比如,

假设 MySQL 按照查询中的关联顺序 A、B 来进行关联操作,那么可以用下面的伪代码表示 MySQL 如何完成这个查询:
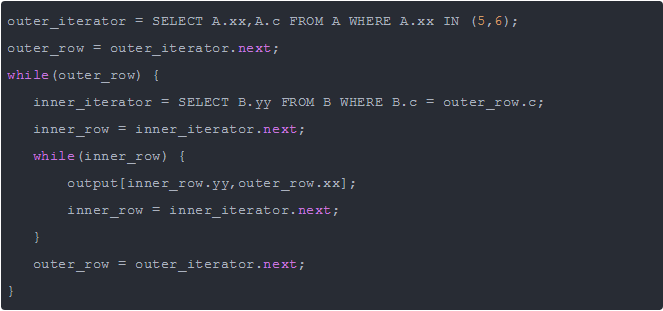
可以看到,最外层的查询是根据 A.xx 列来查询的,A.c 上如果有索引的话,整个关联查询也不会使用。
再看内层的查询,很明显 B.c 上如果有索引的话,能够加速查询,因此只需要在关联顺序中的第二张表的相应列上创建索引即可。
2、优化limit分页
当需要分页操作时,通常会使用 LIMIT 加上偏移量的办法实现,同时加上合适的 ORDER BY 字句。
如果有对应的索引,通常效率会不错,否则,MySQL 需要做大量的文件排序操作。
一个常见的问题是当偏移量非常大的时候,比如:LIMIT 10000 20 这样的查询,MySQL 需要查询 10020 条记录然后只返回 20 条记录,前面的 10000 条都将被抛弃,这样的代价非常高。
优化这种查询一个最简单的办法就是尽可能的使用覆盖索引扫描,而不是查询所有的列,然后根据需要做一次关联查询再返回所有的列。对于偏移量很大时,这样做的效率会提升非常大。考虑下面的查询:

如果这张表非常大,那么这个查询最好改成下面的样子:

这里的延迟关联将大大提升查询效率,让 MySQL 扫描尽可能少的页面,获取需要访问的记录后在根据关联列回原表查询所需要的列。















 649
649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









