




 本文详细介绍了几种常见的排序算法,包括直接插入排序、二分插入排序、快速排序等,并提供了具体的实现代码。此外,还讨论了这些算法的时间复杂度及适用场景。
本文详细介绍了几种常见的排序算法,包括直接插入排序、二分插入排序、快速排序等,并提供了具体的实现代码。此外,还讨论了这些算法的时间复杂度及适用场景。
知识点
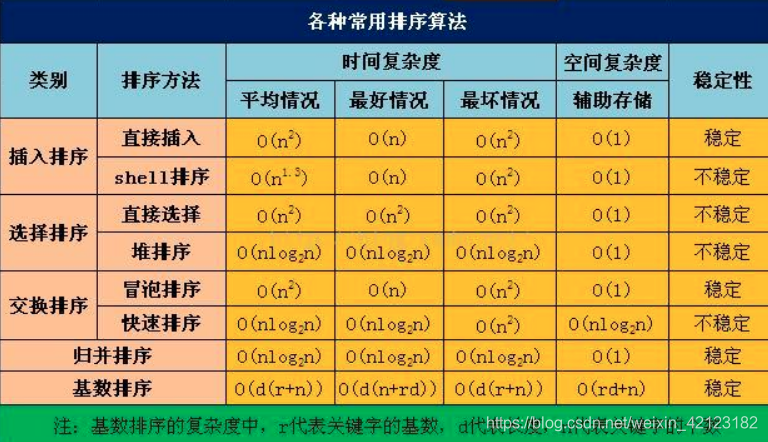
- 直接插入排序

public static void insertSort(int[] arr){
if(arr == null || arr.length <= 1) return;
for(int i=1;i<arr.length ;i++){
int p=i;
int temp=arr[p];
while(p>0&&arr[p-1]>temp){
arr[p]=arr[p-1];
p--;
}
arr[p]=temp;
}
}
-
二分插入
-
快速排序
1.设置两个变量 low、high,排序开始时:low=0,high=size-1。每一轮找一个基准元素,arr[low](这一轮会让这个基准元素有序,即左边都小于,右边都大于)
2.high-- 如果找到比基准小的 则把这个小的移动到arr[low],然后low++,如果找到比基准大的 则把这个大的移动到arr[high]的位置
3.如果low和High相遇时,就把基准元素移动到相遇位置,然后选择第二个基准重复上述动作。最优和平均复杂度都是O(nlogn)
最糟糕为O(n^2)。当待排序的序列为正序或逆序排列时,且每次划分只得到一个比上一次划分少一个记录的子序列,注意另一个为空
func quickSort(arr []int,left,right int)[]int{
var temp int
i:=left
j:=right
if (left<right){
temp=arr[left]
for i<j{
for i<j&&arr[j]>=temp{
j--
}
if i<j{
arr[i]=arr[j]
i++
}
for i<j&&arr[i]<=temp{
i++
}
if i<j{
arr[j]=arr[i]
j--
}
}
arr[i]=temp
quickSort(arr,left,j-1)
quickSort(arr,i+1,right)
}
- 二分查找
1.该序列必须是有序的
2.该序列必须是顺序存储的,如果是链表就不可以
3.折半查找,如果中间值大于目标,则从左半边找,如果中间值小于,则从右半边找
package main
func main() {
println(search([]int{1,2,4,8,9},8))
}
func search(arr []int,num int)int{
low :=0
high:=len(arr)-1
mid:=low+high/2
for low<high{
if arr[mid]==num{
return arr[mid]
}else if arr[mid]<num{
low=mid+1
}else{
high=mid-1
}
}
return -1
}
-
单链表排序
-
怎么把一组随机数 随机分成两组 要求和尽量一致,数量尽量一致
-
堆排序
-
怎么判断一棵树是不是二叉搜索树。我没联想到中序和二叉搜索树的关系,很遗憾的就惨败了
-
从前后两边查找指定字符出现的个数
-
有哪些稳定或者不稳定排序
稳定排序算法 1、冒泡排序 2、鸡尾酒排序 3、插入排序 4、桶排序 5、计数排序 6、合并排序 7、基数排序 8、二叉排序树排序
不稳定排序算法 1、选择排序 2、希尔排序 3、组合排序 4、堆排序 -
1亿的的数字中找到最大的10个
-
堆排序,堆排序的思路
-
大数相加 两个1000位的相加
定义三个数组,两个分别存储每一位大数,第三个存储相加的和,如果该位和>10,则向前进一位。for(int i=0; i<result.length; i++){ int temp = result[i]; //加上前一位的进位 temp += arrayA[i]; temp += arrayB[i]; //判断是否进位 if(temp >= 10){ temp = temp-10; //有进位的话将temp化为一位数 result[i+1] = 1; //将进位1存储到结果数组的下一位 } result[i] = temp; //将1位数存储到结果数组对应位 } -
从一千万的数中快速找出十个不同的用户
经典的TOP K问题,就说从 海量数据中找某些特定条件的数据
1.从海量n个数据中找前k个最大/最小的树
a.冒泡法,每一轮找最大/最小的,共冒泡k轮
b.堆排序,先用前k个元素生成一个小顶堆,这个小顶堆用于存储当前最大的k个元素。接着,从第k+1个元素开始扫描,和堆顶(堆中最小的元素)比较,如果被扫描的元素大于堆顶,则替换堆顶的元素,并调整堆,以保证堆内的k个元素,总是当前最大的k个元素。 -
提取某网站某日访问量前十的Ip

-
如何快速的比较两个文件的内容是否一样?不一样的并把它找出来
1.利用分治法和哈希法1.值一样的两个对象hash code必一样 2.hash code一样的两个对象值不一定一样;所以hash并不可靠文件是按行储存的,一行一行的读取文件,每读取到一行,取它的hashcode确定一个Hash函数,比如:hashcode%2000,通过这个Hash函数可以把每行根据模数值划分到2000个小文件中去(a1,a2,a3……,a2000),如果划分后的小文件比较小了,就可以把小文件直接装载到内存中去,进行遍历就可以查找到相同的两行。如果划分后的小文件还是很大,就说明还可以继续调优,根据实际可用内存情况比如把2000调整为20000,这样就把整个文件分成了20000个小文件,对每个小文件遍历,就可以查找出相同的两行。
-
求二叉树的高度
-
单链表循环的问题


















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









