




 本文深入探讨Redis性能问题,包括基准性能测试、慢日志分析、bigkey处理、内存碎片整理等,提供了一系列实用的优化策略。
本文深入探讨Redis性能问题,包括基准性能测试、慢日志分析、bigkey处理、内存碎片整理等,提供了一系列实用的优化策略。
前言
你们是否遇到过以下这些场景:
- 在 Redis 上执行同样的命令,为什么有时响应很快,有时却很慢?
- 为什么 Redis 执行 SET、DEL 命令耗时也很久?
- 为什么我的 Redis 突然慢了一波,之后又恢复正常了?
- 为什么我的 Redis 稳定运行了很久,突然从某个时间点开始变慢了?
ps:我遇到过2,4。
Redis真的变慢了吗?
首先,在开始之前,你需要弄清楚Redis是否真的变慢了?
如果你发现你的业务服务 API 响应延迟变长,首先你需要先排查服务内部,究竟是哪个环节拖慢了整个服务。
比较高效的做法是,在服务内部集成链路追踪(打印日志的方式也可以),也就是在服务访问外部依赖的出入口,记录每次请求外部依赖的响应延时。
如果你发现确实是操作 Redis 的这条链路耗时变长了,那么此刻你需要把焦点关注在业务服务到 Redis 这条链路上。
Redis这条链路变慢的原因可能也有 2 个:
- 业务服务器到 Redis 服务器之间的网络存在问题,例如网络线路质量不佳,网络数据包在传输时存在延迟、丢包等情况;
- Redis 本身存在问题,需要进一步排查是什么原因导致 Redis 变慢。
**天坑的我,两种都遇到了,哈哈哈哈**
第一种情况发生的概率比较小,如果有,找网络运维。我们这篇文章,重点关注的是第二种情况。
什么是基准性能?
排除网络原因,如何确认你的 Redis 是否真的变慢了?首先,你需要对 Redis 进行基准性能测试(什么,你没有做过!!!!),了解你的 Redis 在生产环境服务器上的基准性能。基准性能就是指 Redis 在一台负载正常的机器上,其最大的响应延迟和平均响应延迟分别是怎样的?
- 方式一:redis-cli --intrinsic-latency
- 方式二:redis-benchmark
使用复杂度过高的命令
你需要去查看一下 Redis 的慢日志slowlog(又不会!)。Redis 提供了慢日志命令的统计功能,它记录了有哪些命令在执行时耗时比较久。
redis.config文件:
- 慢日志的阈值:
CONFIG SET slowlog-log-slower-than 5000 - 只保留最近 500 条慢日志 :
CONFIG SET slowlog-max-len 500
127.0.0.1:6379> SLOWLOG get 5
1) 1) (integer) 32693 # 慢日志ID
2) (integer) 1593763337 # 执行时间戳
3) (integer) 5299 # 执行耗时(微秒)
4) 1) "LRANGE" # 具体执行的命令和参数
2) "user_list:2000"
3) "0"
4) "-1"
通过查看慢日志,我们就可以知道在什么时间点,执行了哪些命令比较耗时。
- 经常使用
O(N) 以上复杂度的命令,例如keys、flushdb类命令。 - 使用
O(N)复杂度的命令,但N的值非常大。如:hgetall、lrange、smembers、zrange等并非不能使用,但是需要明确N的值。
第一种情况导致变慢的原因在于,Redis 在操作内存数据时,时间复杂度过高,要花费更多的 CPU资源。
第二种情况导致变慢的原因在于,Redis 一次需要返回给客户端的数据过多,更多时间花费在数据协议的组装和网络传输过程中。
另外,如果你的应用程序操作 Redis 的QPS不是很大,但 Redis 实例的 CPU 使用率却很高,那么很有可能是使用了复杂度过高的命令导致的。Redis 是单线程处理客户端请求的,如果你经常使用以上命令,那么当Redis处理客户端请求时,一旦前面某个命令发生耗时,就会导致后面的请求发生排队,对于客户端来说,响应延迟也会变长。
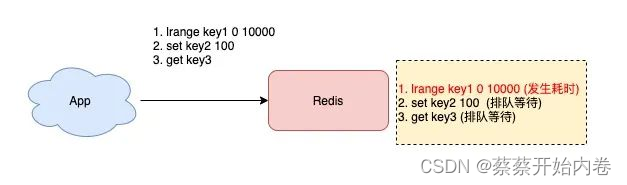
操作bigkey
你查询慢日志发现,并不是复杂度过高的命令导致的,而都是 SET / DEL 这种简单命令出现在慢日志中,那么你就要怀疑你的实例否写入了bigkey。
Redis 在写入数据时,需要为新的数据分配内存,相对应的,当从 Redis 中删除数据时,它会释放对应的内存空间。如果一个 key 写入的 value 非常大,那么 Redis 在分配内存时就会比较耗时。同样的,当删除这个 key 时,释放内存也会比较耗时,这种类型的 key 我们一般称之为 bigkey。
如何扫描出实例中 bigkey 的分布情况呢?
- 第一种:
Redis提供了扫描bigkey的命令,执行以下命令就可以扫描出,一个实例中bigkey的分布情况:
$ redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 0.01
...
-------- summary -------
Sampled 829675 keys in the keyspace!
Total key length in bytes is 10059825 (avg len 12.13)
Biggest string found 'key:291880' has 10 bytes
Biggest list found 'mylist:004' has 40 items
Biggest set found 'myset:2386' has 38 members
Biggest hash found 'myhash:3574' has 37 fields
Biggest zset found 'myzset:2704' has 42 members
36313 strings with 363130 bytes (04.38% of keys, avg size 10.00)
787393 lists with 896540 items (94.90% of keys, avg size 1.14)
1994 sets with 40052 members (00.24% of keys, avg size 20.09)
1990 hashs with 39632 fields (00.24% of keys, avg size 19.92)
1985 zsets with 39750 members (00.24% of keys, avg size 20.03)
每种**数据类型(5个基础类型,不是全部数据)**所占用的最大内存 / 拥有最多元素的 key 是哪一个,以及每种数据类型在整个实例中的占比和平均大小 / 元素数量。使用这个命令的原理,就是 Redis 在内部执行了 SCAN 命令,遍历整个实例中所有的 key,然后针对 key 的类型,分别执行 STRLEN、LLEN、HLEN、SCARD、ZCARD 命令,来获取 String 类型的长度、容器类型(List、Hash、Set、ZSet)的元素个数。
当执行这个命令时,要注意 2 个问题:
- 对线上实例进行 bigkey 扫描时,Redis 的 OPS ( 每秒操作次数)会突增,为了降低扫描过程中对 Redis 的影响,最好控制一下扫描的频率,指定
-i参数即可,它表示扫描过程中每次扫描后休息的时间间隔,单位是秒。 - 扫描结果中,对于容器类型(
List、Hash、Set、ZSet)的 key,只能扫描出元素最多的 key。但一个 key 的元素多,不一定表示占用内存也多,你还需要根据业务情况,进一步评估内存占用情况。 - 第二种:
rdb_bigkeys工具,go写的一款工具,分析rdb文件,找出文件中的大key,直接导出到csv文件,方便查看,个人推荐使用该工具去查找大key。
工具地址: https://github.com/weiyanwei412/rdb_bigkeys
针对 bigkey 导致延迟的问题,有什么好的解决方案呢?
- 拒绝
bigkey(十分推荐)- 导致redis阻塞
- 网络拥塞
- 过期删除:设置了过期时间,当它过期后,会被删除,如果没有使用Redis 4.0的
过期异步删除(lazyfree-lazy-expire yes),就会存在阻塞Redis的可能性。
Redis是4.0以上版本,用UNLINK命令替代DEL,此命令可以把释放 key 内存的操作,放到后台线程中去执行,从而降低对Redis的影响;Redis是4.0以上版本,可以开启lazy-free机制(lazyfree-lazy-user-del = yes),在执行DEL命令时,释放内存也会放到后台线程中执行。
bigkey 在很多场景下,依旧会产生性能问题。例如,bigkey 在分片集群模式下,对于数据的迁移也会有性能影响,数据过期、数据淘汰、透明大页,都会受到bigkey的影响。
集中过期
如果你发现,平时在操作 Redis 时,并没有延迟很大的情况发生,但在某个时间点突然出现一波延时,其现象表现为:变慢的时间点很有规律,每间隔多久就会发生一波延迟。如果是出现这种情况,那么你需要排查一下,业务代码中是否存在设置大量 key 集中过期的情况。如果有大量的key在某个固定时间点集中过期,在这个时间点访问 Redis 时,就有可能导致延时变大。
Redis对于过期键有三种清除策略:
- 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期
key; - 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以
Redis会定期主动淘汰一批已过期的key,Redis内部维护了一个定时任务,默认每隔100毫秒就会从全局的过期哈希表中随机取出20个key,然后删除其中过期的key,如果过期key的比例超过了25%,则继续重复此过程,直到过期key的比例下降到25%以下,或者这次任务的执行耗时超过了25毫秒,才会退出循环。**这个主动过期 key 的定时任务,是在 Redis 主线程中执行的。** - 当前已用内存超过
maxmemory限定时,触发内存淘汰策略。
也就是说如果在执行主动过期的过程中,出现了需要大量删除过期 key 的情况,那么此时应用程序在访问Redis时,必须要等待这个过期任务执行结束,Redis 才可以服务这个客户端请求。此时需要过期删除的是一个 bigkey,那么这个耗时会更久。而且,这个操作延迟的命令并不会记录在慢日志中。慢日志中没有操作耗时的命令,但我们的应用程序却感知到了延迟变大,其实时间都花费在了删除过期 key 上,这种情况我们需要尤为注意。
解决方法:
- 集中过期
key增加一个随机过期时间,把集中过期的时间打散,降低Redis清理过期key的压力; Redis是4.0以上版本,可以开启lazy-free机制,当删除过期 key时,把释放内存的操作放到后台线程中执行,避免阻塞主线程。
实例内存达到上限
原因在于,当 Redis 内存达到 maxmemory 后,每次写入新的数据之前,Redis 必须先从实例中踢出一部分数据,让整个实例的内存维持在 maxmemory 之下,然后才能把新数据写进来。
allkeys-lru:不管 key 是否设置了过期,淘汰最近最少访问的 keyvolatile-lru:只淘汰最近最少访问、并设置了过期时间的 keyallkeys-random:不管 key 是否设置了过期,随机淘汰 keyvolatile-random:只随机淘汰设置了过期时间的 keyallkeys-ttl:不管 key 是否设置了过期,淘汰即将过期的 keynoeviction:不淘汰任何 key,实例内存达到 maxmeory 后,再写入新数据直接返回错allkeys-lfu:不管 - key 是否设置了过期,淘汰访问频率最低的 key(4.0+版本支持)volatile-lfu:只淘汰访问频率最低、并设置了过期时间 key(4.0+版本支持)
Redis 的淘汰数据的逻辑与删除过期 key 的一样,也是在命令真正执行之前执行的,也就是说它也会增加我们操作 Redis 的延迟,而且,写 OPS 越高,延迟也会越明显。Redis 实例中还存储了 bigkey,那么在淘汰删除 bigkey 释放内存时,也会耗时比较久。
优化建议:
- 避免存储
bigkey,降低释放内存的耗时; - 淘汰策略改为随机淘汰,随机淘汰比
LRU要快很多(视业务情况调整); - 拆分实例,把淘汰
key的压力分摊到多个实例上; - 如果使用的是 Redis 4.0 以上版本,开启 layz-free 机制,把淘汰 key 释放内存的操作放到后台线程中执行(配置 lazyfree-lazy-eviction = yes);
持久化/同步影响
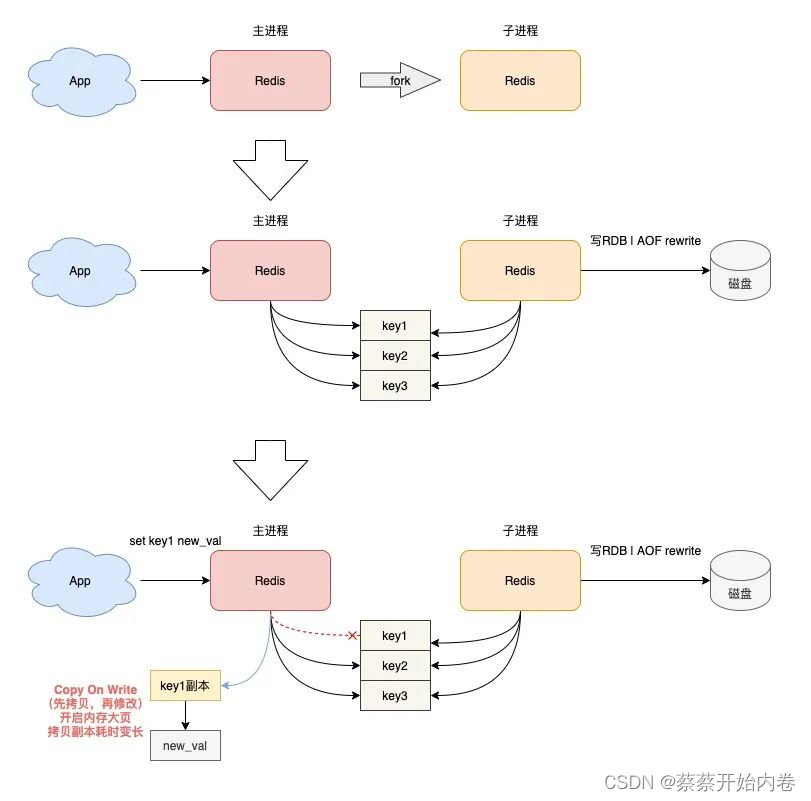
fork耗时严重
操作 Redis 延迟变大,都发生在 Redis 后台 RDB 和AOF rewrite 期间,那你就需要排查,在这期间有可能导致变慢的情况。当 Redis 开启了后台 RDB 和 AOF rewrite 后,在执行时,它们都需要主进程创建出一个子进程进行数据的持久化。主进程创建子进程,会调用操作系统提供的fork函数。而 fork 在执行过程中,主进程需要拷贝自己的内存页表给子进程,如果这个实例很大,那么这个拷贝的过程也会比较耗时。而且这个 fork 过程会消耗大量的CPU资源,在完成fork之前,整个 Redis 实例会被阻塞住,无法处理任何客户端请求。如果此时你的 CPU 资源本来就很紧张,那么 fork 的耗时会更长,甚至达到秒级,这会严重影响 Redis 的性能。
你可以在 Redis 上执行 INFO 命令,查看 latest_fork_usec 项,单位微秒。
数据持久化会生成 RDB 之外,当主从节点第一次建立数据同步时,主节点也创建子进程生成 RDB,然后发给从节点进行一次全量同步,所以,这个过程也会对 Redis 产生性能影响。
优化:
- 控制
Redis实例的内存:尽量在10G以下,执行fork的耗时与实例大小有关,实例越大,耗时越久 - 合理配置数据持久化策略:在
slave节点执行RDB备份,推荐在低峰期执行,而对于丢失数据不敏感的业务(例如把 Redis 当做纯缓存使用),可以关闭AOF 和 AOF rewrite。 Redis实例不要部署在虚拟机上:fork的耗时也与系统也有关,虚拟机比物理机耗时更久。- 降低主从库全量同步的概率:适当调大· repl-backlog-size· 参数,避免主从全量同步。
开启内存大页
什么是内存大页?
我们都知道,应用程序向操作系统申请内存时,是按内存页进行申请的,而常规的内存页大小是 4KB。
Linux 内核从2.6.38开始,支持了内存大页机制,该机制允许应用程序以2MB大小为单位,向操作系统申请内存。应用程序每次向操作系统申请的内存单位变大了,但这也意味着申请内存的耗时变长。主进程fork子进程后,此时的主进程依旧是可以接收写请求的,而进来的写请求,会采用 Copy On Write(写时复制)的方式操作内存数据。主进程一旦有数据需要修改,Redis 并不会直接修改现有内存中的数据,而是先将这块内存数据拷贝出来,再修改这块新内存的数据。写时复制你也可以理解成,谁需要发生写操作,谁就需要先拷贝,再修改。
注意,主进程在拷贝内存数据时,这个阶段就涉及到新内存的申请,如果此时操作系统开启了内存大页,那么在此期间,客户端即便只修改 10B 的数据,Redis 在申请内存时也会以 2MB 为单位向操作系统申请,申请内存的耗时变长,进而导致每个写请求的延迟增加,影响到 Redis 性能。如果这个写请求操作的是一个 bigkey,那主进程在拷贝这个 bigkey 内存块时,一次申请的内存会更大,时间也会更久。可见,bigkey 在这里又一次影响到了性能。
开启AOF
-
AOF配置为appendfsync always,那么Redis每处理一次写操作,都会把这个命令写入到磁盘中才返回,整个过程都是在主线程执行的,这个过程必然会加重Redis写负担。 -
AOF配置为appendfsync no,Redis每次写操作只写内存,什么时候把内存中的数据刷到磁盘,交给操作系统决定,对Redis的性能影响最小,但当Redis宕机时,会丢失一部分数据,为了数据的安全性。 -
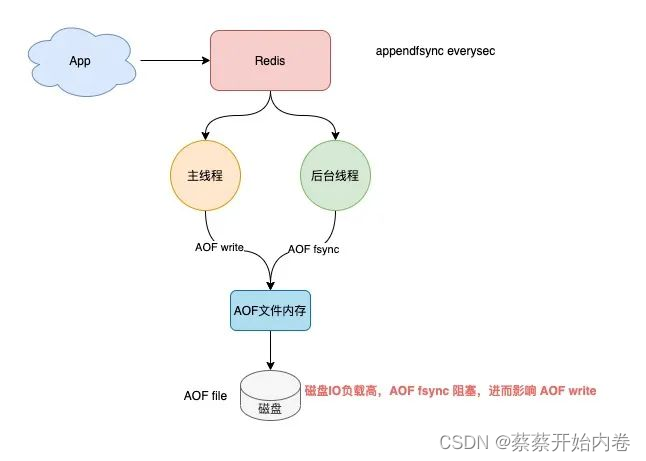
AOF配置为appendfsync everysec,当Redis 后台线程在执行AOF文件刷盘时,如果此时磁盘的IO负载很高,那这个后台线程在执行刷盘操作(fsync系统调用)时就会被阻塞住。此时的主线程依旧会接收写请求,紧接着,主线程又需要把数据写到文件内存中(write 系统调用),但此时的后台子线程由于磁盘负载过高,导致 fsync 发生阻塞,迟迟不能返回,那主线程在执行 write 系统调用时,也会被阻塞住,直到后台线程fsync执行完成后,主线程执行write才能成功返回。
我总结了以下几种情况,你可以参考进行问题排查: -
子进程正在执行 AOF rewrite,这个过程会占用大量的磁盘 IO 资源;
-
有其他应用程序在执行大量的写文件操作,也会占用磁盘 IO 资源;
Redis 的 AOF 后台子线程刷盘操作,撞上了子进程 AOF rewrite!Redis 提供了一个配置项,当子进程在 AOF rewrite 期间,可以让后台子线程不执行刷盘(不触发 fsync 系统调用)操作。
这相当于在 AOF rewrite期间,临时把 appendfsync 设置为了 none,配置如下:
# AOF rewrite 期间,AOF 后台子线程不进行刷盘操作
# 相当于在这期间,临时把 appendfsync 设置为了 none
no-appendfsync-on-rewrite yes
开启这个配置项,在 AOF rewrite 期间,如果实例发生宕机,那么此时会丢失更多的数据,性能和数据安全性,你需要权衡后进行选择。
碎片整理
Redis 的数据都存储在内存中,当我们的应用程序频繁修改Redis中的数据时,就有可能会导致 Redis产生内存碎片。内存碎片会降低 Redis 的内存使用率,我们可以通过执行INFO命令,得到这个实例的内存碎片率:

used_memory 表示 Redis 存储数据的内存大小,
used_memory_rss 表示操作系统实际分配给 Redis 进程的大小。
mem_fragmentation_ratio> 1.5,说明内存碎片率已经超过了 **50%**,这时我们就需要采取一些措施来降低内存碎片了。
解决的方案一般如下:
- 如果你使用的是
Redis 4.0以下版本,只能通过重启实例来解决 - 如果你使用的是
Redis 4.0版本,它正好提供了自动碎片整理的功能,可以通过配置开启碎片自动整理但是,开启内存碎片整理,它也有可能会导致Redis性能下降。
原因在于,Redis 的碎片整理工作是也在主线程中执行的,当其进行碎片整理时,必然会消耗CPU资源,产生更多的耗时,从而影响到客户端的请求。
其他原因
- 频繁短连接:你的业务应用,应该使用长连接操作 Redis,避免频繁的短连接。
- 其它程序争抢资源:其它程序占用 CPU、内存、磁盘资源,导致分配给 Redis 的资源不足而受到影响。
总结:
你应该也发现了,Redis 的性能问题,涉及到的知识点非常广,几乎涵盖了 CPU、内存、网络、甚至磁盘的方方面面,同时,你还需要了解计算机的体系结构,以及操作系统的各种机制。
从资源使用角度来看,包含的知识点如下:
- CPU 相关:使用复杂度过高命令、数据的持久化,都与耗费过多的 CPU 资源有关
- 内存相关:bigkey 内存的申请和释放、数据过期、数据淘汰、碎片整理、内存大页、内存写时复制都与内存息息相关
- 磁盘相关:数据持久化、AOF 刷盘策略,也会受到磁盘的影响
- 网络相关:短连接、实例流量过载、网络流量过载,也会降低 Redis 性能
- 计算机系统:CPU 结构、内存分配,都属于最基础的计算机系统知识
- 操作系统:写时复制、内存大页、Swap、CPU 绑定,都属于操作系统层面的知识
扩展
什么是大key?
通常以key的大小和key中成员的数量来综合判定,例如:
- key本身的数据量过大:一个String类型的Key,它的值为
5MB。 - key中的成员数过多:一个ZSET类型的Key,它的成员数量为
10,000个。 - key中成员的数据量过大:一个Hash类型的Key,它的成员数量虽然只有
1,000个但这些成员的Value(值)总大小为100MB。
大Key产生的原因
未正确使用Redis、业务规划不足、无效数据的堆积等都会产生大key,如:
- 在不适用的场景下使用
Redis,易造成key的value过大,如使用String类型的key存放大体积二进制文件型数据; - 业务上线前规划设计不足,没有对key中的成员进行合理的拆分,造成个别key中的成员数量过多;
- 未定期清理无效数据,造成如
HASH类型key中的成员持续不断地增加; - 使用
LIST类型key的业务消费侧发生代码故障,造成对应key的成员只增不减。
优化大key
- 对大key进行拆分:例如将含有数万成员的一个
HASH key拆分为多个HASH key。 - 对大Key进行清理:将不适用Redis能力的数据存至其它存储,并在Redis中删除此类数据。
- 监控Redis的内存水位:您可以通过监控系统设置合理的Redis内存报警阈值进行提醒,例如Redis内存使用率超过70%、Redis的内存在1小时内增长率超过20%等。
- 对过期数据进行定期清理:堆积大量过期数据会造成大`key``的产生,例如在HASH数据类型中以增量的形式不断写入大量数据而忽略了数据的时效性。可以通过定时任务的方式对失效数据进行清理。

















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









