







在智能手机和社交媒体盛行的今天,我们每天都在接触各种各样的图像或视频,我们能感知到它们的色彩差异、清晰度、明暗对比等等,那这些画面是怎么形成并展示出来的呢?内部的机制与原理又是怎样的?今天我们就来一一揭秘。我们将从视频 / 图像的原始数据格式、视频逐行 / 隔行扫描、帧率、图像分辨率、色域等几方面入手,对视频基础知识做一个整体性的了解。
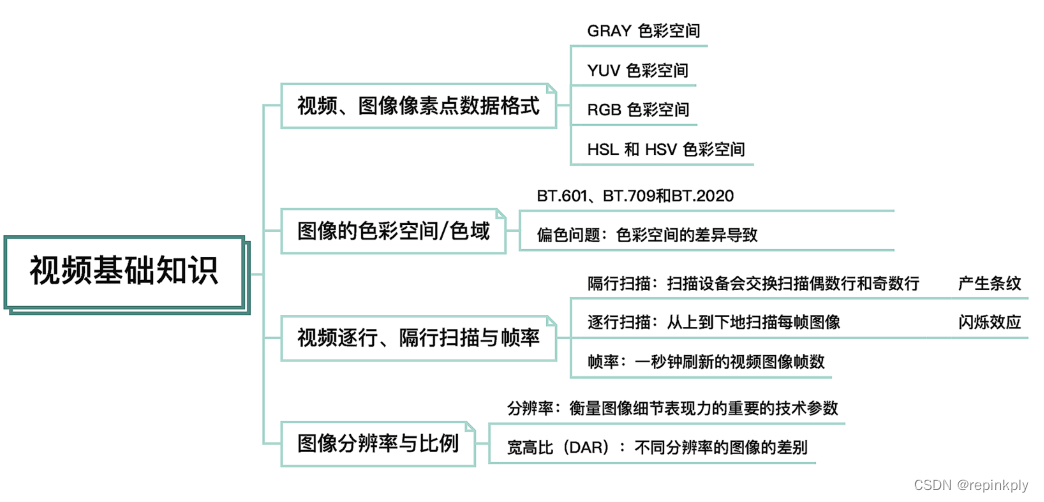
视频、图像像素点数据格式
当我们看视频时会看到很多图像,这些图像的展现形式我们中学学习几何课程的时候就接触过,是由一个个像素点组成的线,又由一条条线组成面,这个面铺在屏幕上展现出来的就是我们看到的图像。
这些图像有黑白的,也有彩色的。这是因为图像输出设备支持的规格不同,所以色彩空间也有所不同,不同的色彩空间能展现的色彩明暗程度,颜色范围等也不同。为了让你对色彩空间有一个基本的认识,这节课我将给你介绍一些常见的色彩格式,分别是:
• GRAY 色彩空间
• YUV 色彩空间
• RGB 色彩空间
• HSL 和 HSV 色彩空间
GRAY 灰度模式表示
在 20 世纪 80、90 年代,国内大多数家庭看的还是黑白电视。那个黑白电视的图像就是以 GRAY 的方式展现的图像,也就是 Gray 灰度模式。这一模式为 8 位展示的灰度,取值 0 至 255,表示明暗程度,0 为最黑暗的模式,255 为最亮的模式,色彩表示范围如图所示:

由于每个像素点是用 8 位深展示的,所以一个像素点等于占用一个字节,一张图像占用的存储空间大小计算方式也比较简单:
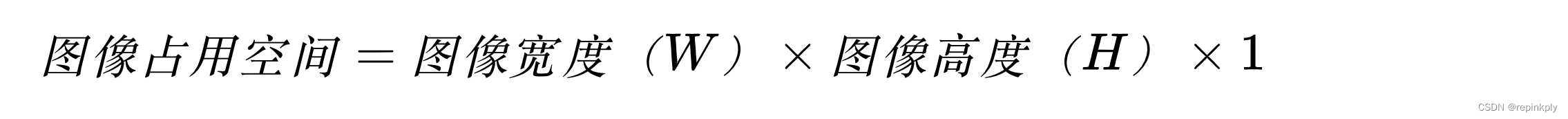
举个例子,如果图像为 352x288 的分辨率,那么一张图像占用的存储空间应该是 352x288,也就是 101376 个字节大小。
YUV 色彩表示
在视频领域,通常以 YUV 的格式来存储和显示图像。其中 Y 表示视频的灰阶值,也可以理解为亮度值,而 UV 表示色彩度,如果忽略 UV 值的话,我们看到的图像与前面提到的 GRAY 相同,为黑白灰阶形式的图像。YUV 最大的优点在于每个像素点的色彩表示值占用的带宽或者存储空间非常少。
你可以看一下这张图片,是原图与 YUV 的 Y 通道、U 通道和 V 通道的图像示例:

YUV图像示例
为节省带宽起见,大多数 YUV 格式平均使用的每像素位数都少于 24 位。主要的色彩采样格式有 YCbCr 4:2:0、YCbCr 4:2:2、YCbCr 4:1:1 和 YCbCr 4:4:4。YUV 的表示法也称为 A:B:C 表示法。
YUV 4:4:4 格式
yuv444 表示 4 比 4 比 4 的 yuv 取样,水平每 1 个像素(即 1x1 的 1 个像素)中 y 取样 1 个,u 取样 1 个,v 取样 1 个,所以每 1x1 个像素 y 占有 1 个字节,u 占有 1 个字节,v 占有 1 个字节,平均 yuv444 每个像素所占位数为:
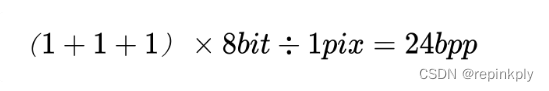
那么 352x288 分辨率的一帧图像占用的存储空间为:
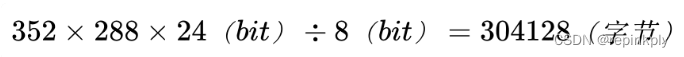
YUV 4:2:2 格式
yuv422 表示 4 比 2 比 2 的 yuv 取样,水平每 2 个像素(即 2x1 的 2 个像素)中 y 取样 2 个,u 取样 1 个,v 取样 1 个,所以每 2x1 个像素 y 占有 2 个字节,u 占有 1 个字节,v 占有 1 个字节,平均 yuv422 每个像素所占位数为:
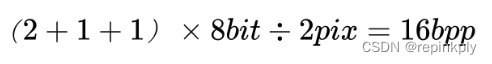
那么 352x288 分辨率的一帧图像占用的存储空间为:
![]()
yuv4:1:1 格式
yuv411 表示 4 比 1 比 1 的 yuv 取样,水平每 4 个像素(即 4x1 的 4 个像素)中 y 取样 4 个,u 取样 1 个,v 取样 1 个,所以每 4x1 个像素 y 占有 4 个字节,u 占有 1 个字节,v 占有 1 个字节,平均 yuv411 每个像素所占位数为:
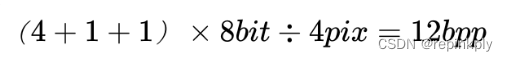
那么 352x288 分辨率的一帧图像占用的存储空间为:
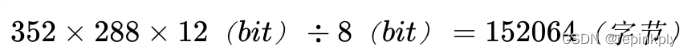
yuv4:2:0 格式
yuv420 表示 4 比 2 比 0 的 yuv 取样,水平每 2 个像素与垂直每 2 个像素(即 2x2 的 2 个像素)中 y 取样 4 个,u 取样 1 个,v 取样 1 个,所以每 2x2 个像素 y 占有 4 个字节,u 占有 1 个字节,v 占有 1 个字节,平均 yuv420 每个像素所占位数为:
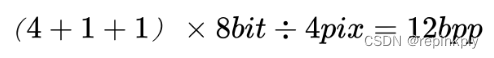
那么 352x288 分辨率的一帧图像占用的存储空间为:
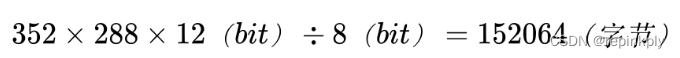
为了方便理解 YUV 在内存中的存储方式,我们以宽度为 6、高度为 4 的 yuv420 格式为例,一帧图像读取和存储在内存中的方式如图:
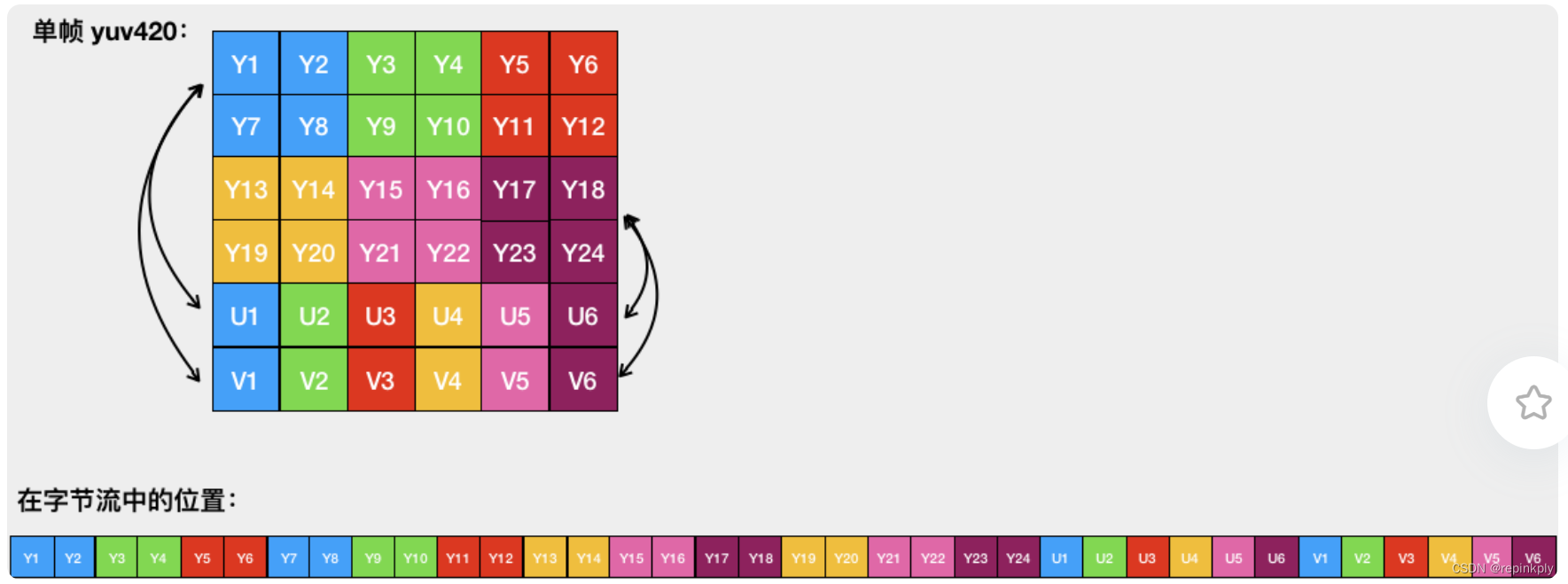
yuv420格式图像的读取和存储方式
RGB 色彩表示
三原色光模式(RGB color model),又称 RGB 颜色模型或红绿蓝颜色模型,是一种加色模型,将红(Red)、绿(Green)、蓝(Blue)三原色的色光按照不同的比例相加,来合成各种色彩光。
每象素 24 位编码的 RGB 值:使用三个 8 位无符号整数(0 到 255)表示红色、绿色和蓝色的强度。这是当前主流的标准表示方法,用于交换真彩色和 JPEG 或者 TIFF 等图像文件格式里的通用颜色。它可以产生一千六百万种颜色组合,对人类的眼睛来说,其中有许多颜色已经无法确切地分辨了。
使用每原色 8 位的全值域,RGB 可以有 256 个级别的白 - 灰 - 黑深浅变化,255 个级别的红色、绿色和蓝色以及它们等量混合的深浅变化,但是其他色相的深浅变化相对要少一些。
典型使用上,数字视频的 RGB 不是全值域的。视频 RGB 有比例和偏移量的约定,即 (16, 16, 16)是黑色,(235, 235, 235)是白色。例如,这种比例和偏移量就用在了 CCIR 601 的数字 RGB 定义中。
RGB 常见的展现方式分为 16 位模式和 32 位模式(32 位模式中主要用其中 24 位来表示 RGB)。16 位模式(RGB565、BGR565、ARGB1555、ABGR1555)分配给每种原色各为 5 位,其中绿色为 6 位,因为人眼对绿色分辨的色调更敏感。但某些情况下每种原色各占 5 位,余下的 1 位不使用或者表示 Alpha 通道透明度。
32 位模式(ARGB8888),实际就是 24 位模式,余下的 8 位不分配到象素中,这种模式是为了提高数据处理的速度。同样在一些特殊情况下,在有些设备中或者图像色彩处理内存中,余下的 8 位用来表示象素的透明度(Alpha 通道透明度)。
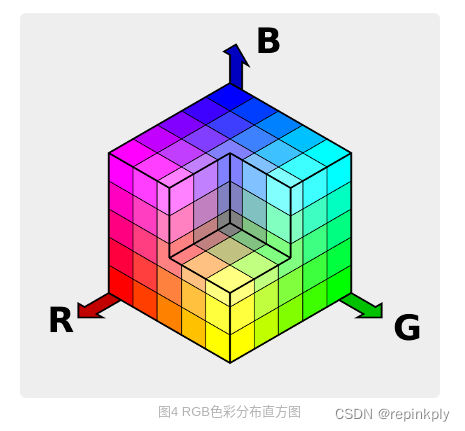
这就是我们所说的 RGB 图像色彩表示,你可以对照着 RGB 色彩分布直方图来理解。
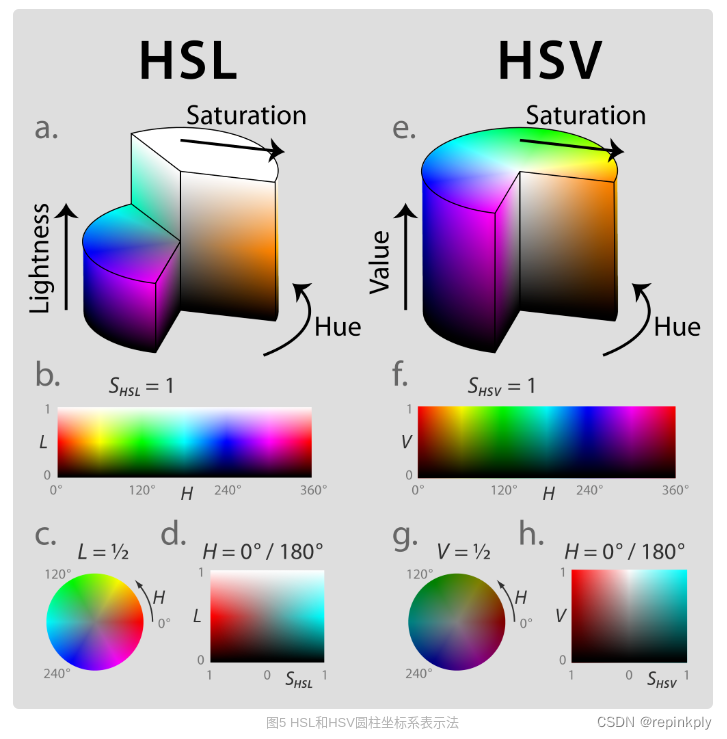
HSL 与 HSV 色彩表示
理解了 RGB 的色彩表示法,相信 HSL 和 HSV 对你来说就比较简单了。因为 HSL 和 HSV 是将 RGB 色彩模型中的点放在圆柱坐标系中的表示法,在视觉上会比 RGB 模型更加直观。
HSL,就是色相(Hue)、饱和度( Saturation)、亮度( Lightness)。HSV 是色相(Hue)、饱和度( Saturation)和明度(Value)。色相(H)是色彩的基本属性,就是平常我们所说的颜色名称,如红色、黄色等;饱和度(S)是指色彩的纯度,越高色彩越纯,低则逐渐变灰,取 0~100% 的数值;明度(V)和亮度(L),同样取 0~100% 的数值。
HSL 和 HSV 二者都把颜色描述在圆柱坐标系里的点内,这个圆柱的中心轴取值为自底部的黑色到顶部的白色,而在它们中间的是灰色,绕这个轴的角度对应于“色相”,到这个轴的距离对应于“饱和度”,而沿着这个轴的高度对应于“亮度”、“色调”或“明度”。如图:
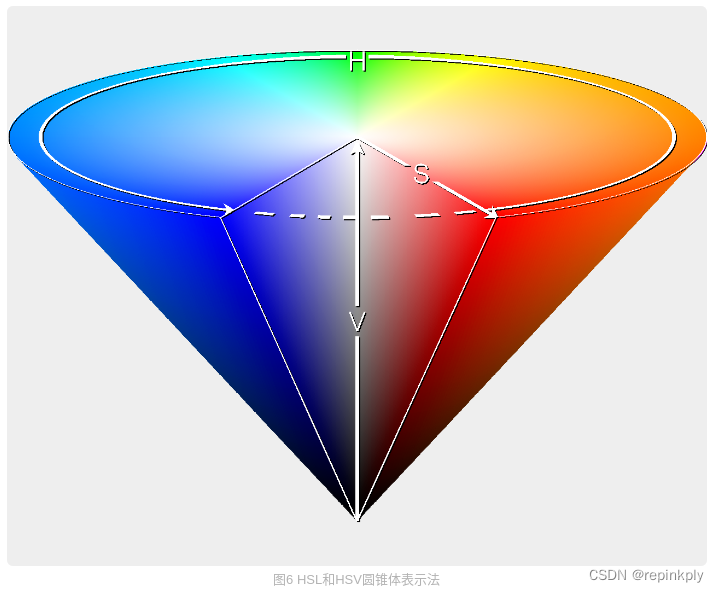
HSV 色彩空间还可以表示为类似于上述圆柱体的圆锥体,色相沿着圆柱体的外圆周变化,饱和度沿着从横截面的圆心的距离变化,明度沿着横截面到底面和顶面的距离而变化。这种用圆锥体来表示 HSV 色彩空间的方式可能更加精确,有些图像在 RGB 或者 YUV 的色彩模型中处理起来并不精准,我们可以将图像转换为 HSV 色彩空间,再进行处理,效果会更好。例如图像的抠像处理,用圆锥体表示在多数情况下更实用、更精准。如图:
图像的色彩空间
了解了视频和图像的集中色彩表示方式,那我们是不是用相同的数据格式就能输出颜色完全一样的图像呢?不一定,你可以观察一下电视中的视频图像、电脑屏幕中的视频图像、打印机打印出来的视频图像,同一张图像会有不同的颜色差异,甚至不同的电脑屏幕看到的视频图像、不同的电视看到的视频图像,有时也会存在颜色差异,比如:

如果仔细观察的话,会发现右图的颜色比左图的颜色更深一些。之所以会出现这样的差异,主要是因为图像受到了色彩空间参数的影响。我们这里说的色彩空间也叫色域,指某种表色模式用所能表达的颜色构成的范围区域。而这个范围,不同的标准支持的范围则不同,下面,我们来看三种范围,分别为基于 CIE 模型表示的 BT.601、BT.709 和 BT.2020 范围。

色彩空间除了 BT.601、BT.709 和 BT.2020 以外,还有很多标准格式,具体的标准我就不在这里一一列举了,在用到的时候,可以使用参考标准(可参考标准:H.273)进行对比。当有人反馈偏色的问题时可以优先考虑是色彩空间的差异导致的,需要调整视频格式(Video Format)、色彩原色(Colour primaries)、转换特性(Transfer characteristics)和矩阵系数(Matrix coefficients)等参数。
现在我们对色彩的相关知识有了一些基本的了解。色彩格式是图像显示的基础,但是视频技术不仅仅需要知道色彩格式,想要理解视频图像的话,还需要弄清楚一些现象,比如有的视频图像运动的时候会有条纹,有的视频图像在运动的时候没有条纹,是什么原因呢?还有,我们在用一些工具导出电影视频的时候,一般会按照 23.97fps 的帧率导出,而很多公众号或者媒体在宣传支持 60 帧帧率,这又是为什么呢?接下来我们通过学习视频逐行、隔行扫描与帧率方面的内容,来一一揭秘。
视频逐行、隔行扫描与帧率
当我们看到一些老电视剧、老电影或者一些 DV 机拍摄的视频时,会发现视频中物体在移动时会出现条纹,这些条纹的存在主要是因为视频采用了隔行扫描的刷新方式。
隔行扫描与逐行扫描
隔行扫描(Interlaced)是一种将图像隔行显示在扫描式显示设备上的方法,例如早期的 CRT 电脑显示器。非隔行扫描的扫描方法,即逐行扫描(Progressive),通常从上到下地扫描每帧图像,这个过程消耗的时间比较长,占用的频宽比较大,所以在频宽不够时,很容易因为阴极射线的荧光衰减在视觉上产生闪烁的效应。而相比逐行扫描,隔行扫描占用带宽比较小。扫描设备会交换扫描偶数行和奇数行,同一张图像要刷两次,所以就产生了我们前面说的条纹。

早期的显示器设备刷新率比较低,所以不太适合使用逐行扫描,一般都使用隔行扫描。在隔行扫描的时候,我们常见的分辨率描述是 720i、1080i,“i”就是 Interlaced。现在我们看视频播放器相关广告和说明时,还经常会看到 720p、1080p 这样的说法,这个“p”又代表什么呢?
在如今这个时代的显示器和电视中,由于逐行扫描显示的刷新率的提高,使用者已经不会感觉到屏幕闪烁了。因此,隔行扫描技术逐渐被取代,逐行扫描越来越常见,也就是我们经常见到的 720p、1080p。
当我们拿到隔行扫描 / 逐行扫描的数据后,总是会看到这样的参数:25fps、30fps、60fps 等等。里面的 fps 是什么呢?
帧率
就是我们平时提到的帧率(FrameRate),指一秒钟刷新的视频图像帧数(Frames Per Second),视频一秒钟可以刷新多少帧,取决于显示设备的刷新能力。不同时代的设备,不同场景的视频显示设备,刷新的能力也不同,所以针对不同的场景也出现了很多种标准,例如:
NTSC 标准的帧率是 30000/1001,大约为 29.97 fps;
PAL 标准的帧率是 25/1,为 25 fps;
QNTSC 标准的帧率是 30000/1001,大约为 29.97 fps;
QPAL 标准的帧率是 25/1,为 25 fps;
SNTSC 标准的帧率是 30000/1001,大约为 29.97 fps;
SPAL 标准的帧率是 25/1,为 25 fps;
FILM 标准的帧率是 24/1,为 24 fps;
NTSC-FILM 标准的帧率是 24000/1001,大约为 23.976 fps。
如果用心观察的话,你会发现 NTSC 标准的分辨率都不是整除的帧率,分母都是 1001,为什么会这样呢?
NTSC 制式的标准为了解决因为色度和亮度频率不同引起失真色差的问题,将频率降低千分之一,于是就看到了有零有整的帧率。我们在电影院看的电影的帧率,实际上标准的是 23.97 fps,所以我们可以看到给院线做视频后期制作的剪辑师们最终渲染视频的时候,大多数会选择 23.97 fps 的帧率导出。关于视频刷新帧率背后更详细的知识,如果感兴趣的话,你可以继续阅读一下《The Black Art of Video Game Console Design》。
说到这里,我们再来解答一下前面的问题,为什么有些公众号宣传自己的编码和设备支持 60 帧帧率呢?这是因为科技在进步,有些显示设备的刷新率更高了,为了让我们的眼球看着屏幕上的物体运动更流畅,所以定制了 60 帧,这也是为了宣传自己设备的功能更加先进、强大。但是在院线标准中,60fps 刷新率的设备并没有大范围升级完毕,当前我们看的依然还是以 film、ntsc-film 标准居多。
图像分辨率与比例
最后我们来看一下另一个与图像相关的重要概念——分辨率。当人们在谈论流畅、标清、高清、超高清等清晰度的时候,其实主要想表达的是分辨率。它是衡量图像细节表现力的重要的技术参数。
除了分辨率之外,我们还需要结合视频的类型、场景等设置适合的码率(单位时间内传递的数据量)。随着视频平台竞争越来越激烈,网络与存储的开销越来越高,有了各种定制的参数设置与算法,在分辨率相同的情况下做了更深层的优化,比如极速高清、极致高清、窄带高清等。但是目前人们对流畅、标清、高清、超高清等清晰度的理解,其实普遍还是指分辨率。
一般,分辨率越高代表图像质量越好,越能看到图像的更多细节,文件也就会越大。分辨率通常由宽、高与像素点占用的位数组成,计算方式为图像的宽乘以高。在提到显示分辨率的时候,人们还常常会提到宽高比,即 DAR。DAR 是显示宽高比率(display aspect ratio),表示不同分辨率的图像的差别。

而分辨率在我们日常的应用中各家的档位定义均有不同,但是在国际的标准中还是有一个参考定义的,并且分辨率都有定义名称。为了方便理解,我们来看一下分辨率的示意图,如图:

我们经常听到人们提到 1080p、4K,其实它们还有更标准的称呼或者叫法,例如 1080p 我们又叫 Full-HD,通常接近 4K 的分辨率我们叫 4K 也没太大问题,像有更标准的叫法,比如 3840x2160 的分辨率应该是 UHD-1。但是如果直接按标准叫法来叫的话,国内很多人可能不太习惯,为了便于区分,通常就直接说分辨率的宽乘以高的数值。因为 4k 的表述比较简洁,所以就可以模糊地说是 4K 了。
小结
想要做好视频工作,就必然绕不开这些基础知识,我分别从视频图像像素点数据格式、视频逐行 / 隔行扫描、帧率、分辨率与比例、色域几个方面带你做了一个概览,这几个方面是组成视频基础最重要的几块基石。
音视频技术与计算机图形学在图像处理方面略有相似,在做视频技术的时候,会频繁地用到图像色彩相关的知识。所以这节课我详细地介绍了 GARY、YUV、RGB、HSL/HSV 四种色彩表示模式。但如果想要做好视频技术,仅仅知道一些图像色彩知识是万万不行的。因为视频是连续的图像序列,所以关于视频逐行 / 隔行扫描、帧的刷新频率等相关知识也必不可少。
图像序列裸数据占用的存储和带宽极高,为了降低存储和传输带宽,我们就需要做图像的数据压缩,图像压缩以有损压缩为主,加上图像本身色彩格式多样,所以难免会有偏色等问题,学完今天的课程你应该能想到这主要是色彩空间的差异导致的,这时候我们需要调整各项参数来解决问题。用户观看视频的时候还需要解码视频数据包,为图像色彩的像素点表示数据,所以我们就又需要用到图像与色彩技术了。
思考
最后我们来思考一个问题:我们常说的 YUV 与 MP4、H.264、RTMP 之间是什么样的关系呢?
音频从采集到输出涉及哪些关键参数?
上面我们学习了视频与图像相关的基础知识,相信你对视频 / 图像中的色彩表示方式、色域、帧率等相关概念已经有了一定的了解。在音视频技术开发与应用领域,除了视频与图像的知识外,我们还会接触到一些音频相关的知识,所以下面我们会聚焦音频基础知识,为之后 FFmpeg 音频相关内容的学习做好铺垫。
我们平常听到的自然界的声音,比如说鸟鸣、水流,其实是一种模拟信号,声音是振动产生的一种声波,通过气态、液态、固态的物理介质传播并能被人或动物感知的波动现象。声音的频率一般会以赫兹(Hz)表示,指每秒钟周期性振动的次数。而声音的强度单位则用分贝(dB)来表示。现如今我们在电脑上、Pad 上、手机上听到的音乐、声音等音频信号,均为数字信号。
音频采样数据格式
介绍音频采样数据格式之前,我们需要先了解音频从采集一直到我们耳朵听到声音这个过程中都发生了什么,我们先看一下下面这张流程图:

首先我们说的话或者在自然界中听到的一些声音,比如鸟鸣,水流等,都是通过空气振动来传输的模拟信号,我们可以通过麦克风或者拾音器采集到声音的模拟信号,然后将模拟信号转换成数字信号,这个过程可以通过麦克风来做,也可以通过音频的转换器来做,转换成数字信号之后将数字信息存储起来,或者输出到扬声器,扬声器会根据数字信号产生一定频率的振动,然后通过空气传播模拟信号到我们的耳朵里面,我们就听到了对应的声音。
在这个流程里我们需要了解一个基本的操作,就是先采集到模拟信号,然后通过 ADC(模数转换)将模拟信号转换成数字信号以后,再通过 PCM(Pulse Code Modulation)脉冲编码调制对连续变化的模拟信号进行采样、量化和编码转换成离散的数字信号,从而实现音频信号的采集。另外,也可以将采集的音频信号输出到扬声器、耳机之类的设备。
我们上面说的 PCM 文件就是未经封装的音频原始文件,或者叫做音频“裸数据”。不同的扬声器、耳机设备,甚至是声卡输出设备,对音频的裸数据支持的情况不一样,有的设备支持单精度浮点型数据、有的设备支持双精度浮点型数据、有的设备支持无符号型数据、有的设备支持有符号型数据。因为输出的数据类型的支持不同,所以 PCM 采样数据的格式在输出之前,需要转换一下。这些数据的格式我们通常称之为采样数据格式。
音频采样频率
音频 PCM 数据的输入和输出是需要有一个频率的,频率通常在我们听觉可接受的范围内,太高或者太低我们都听不见,通常我们人耳能够听到的频率范围是在 20Hz~20kHz 之间,为了保证音频不失真,音频的采样频率通常应该在 40kHz 以上,而理论上采样率大于 40kHz 的音频格式都可以称之为无损格式。现在一般的专业设备的采样频率为 44100Hz(也称之为 44.1kHz)。并且 44.1kHz 是专业音频中的最低采样率。当然要听到更高采样率,比如 96kHz、192kHz 采样频率中的细节的话,就取决于耳朵和对应的设备了。
下面我简单地介绍一下,在数字音频领域常用的采样率与对应的使用场景:
- 8000 Hz 主要是电话通信时用的采样率,对于传达人们说话时的声音已经足够了;
- 11025 Hz、22050 Hz 主要是无线电广播用的采样率;
- 44100 Hz 常用于音频 CD,MP3 音乐播放等场景;
- 48000 Hz 常用于 miniDV、数字电视、DVD、电影和专业音频等设备中。
音频声道及其布局
当我们戴着耳机看电视剧、电影、听音乐、开会的时候,会发现左右耳朵听到的声音有时候会有一些差别,尤其是当我们看 TVB 港剧的时候,一只耳朵听到的是粤语,另一只耳朵听到的是普通话。因为视频里面的音频支持左声道右声道内容不同,所以有些时候我们看电影可以切换左声道右声道模式。
采集不同方位的声源,然后通过不同方位的扬声器播放出来就产生了不同的声道。其实我们常见的声道内容除了左声道、右声道,还有立体声等,当我们听到的音频声道比较多,比如听交响乐的时候,立体感会尤为明显,示意图如下:
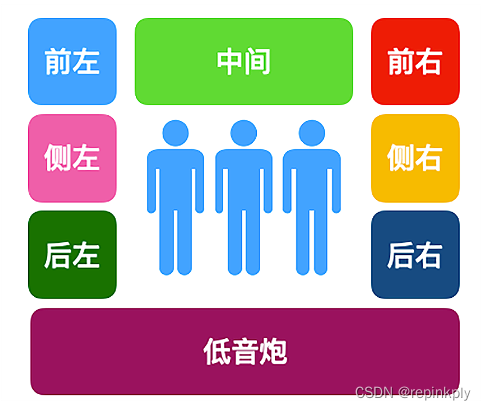
实际上,音频的声道布局不仅仅是上图这么简单。音频技术发展至今,声道布局远比图片显示的复杂得多,在后面我们会看到更多、更复杂的声道布局。
音频采样位深度
采样的位深度,也叫采样位深,它决定了声音的动态范围。平时,我们常见的 16 位(16bit)可以记录大概 96 分贝(96dB)的动态范围。也可以理解为每一个比特大约可以记录 6dB 的声音。同理,20bit 可记录的动态范围大概是 120dB,24bit 就大概是 144dB。
计算公式如下:
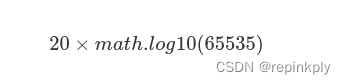
举个例子,我们假定 0dB 为峰值,那么音频的振动幅度就需要以向下延伸计算,所以音频可记录的动态范围就是“-96dB~0dB”。而 24bit 的高清音频的动态范围就是“-144dB~0dB”。由此可见,位深度较高时,有更大的动态范围可利用,可以记录更低电平的细节。
但位深度并不是越大越好,也不是越小越好,不同的场景有不同的应用。
44dB 属于人类可以接受的程度,55dB 会使人感觉到烦躁,60dB 会让人没有睡意,70dB 会令人精神紧张,85dB 长时间听会让人感觉刺耳,100dB 会使人暂时失去听觉,120dB 可以瞬间刺穿你的耳膜,160dB 会通过空气振波震碎玻璃,200dB 可以使人死亡。也就是说,其实如果真的能够让自己的声音达到一定分贝的话,武侠片里面的狮吼功是有可能成为现实的。
通常为了高保真,我们会选择使用 32bit,甚至 64bit 来表示音频。而常规音频通话使用 16bit 来表示即可,当然条件有限的话,8bit 也可以,但它是底线。因为 8bit 的音频表示,听起来有时候会比较模糊。
音频的码率
接下来我们看一下音频的码率。所谓码率,我们通常可以理解为按照某种频率计算一定数据量的单位,重点体现在“率”上面,我们常用的码率统计时间单位为秒,所以码率也就是一秒钟的数据量,通常我们用 bps(bits per second)来表示,也就是每秒钟有多少位数据。而我们平时所说的码率,可以简单理解为每秒钟存储或传输的编码压缩后的数据量。
我们在很多音乐播放器软件中能看到音乐的格式,比如腾讯音乐里面的 SQ、HQ、无损等,这些音乐的音频码率、采样率都是很高的。
那这个音频码率是怎么算出来的呢?其实这里有一个公式,可以帮助我们算出音频的码率。例如我们有一个双声道立体声、采样率是 48000、采样位深是 16 位、时长为 1 分钟的音频,它的存储空间占用计算应该是:
声道数×采样率×采样位深×时长=2×48000×16×60=92160000b=11520000B=11.52MB
码率应该是 :
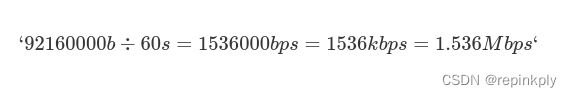
音频的码率可以间接地表示音频的质量,一般高清格式的码率更高。
音频的编解码
我们在传输音频文件的时候经常会看到文件名后面有 MP3、AAC 这样的后缀,其实这些都是音频编码的格式。因为音频在传输和存储时,如果直接存储 PCM 音频数据的话,消耗的带宽或者存储空间会比较多,所以我们为了节省传输带宽或者存储,通常会选择对音频数据做编码压缩处理。
我们在互联网上常见的音频编码有 AAC、MP3、AC-3、OPUS,个别地方还可能会使用 WMA,但是从兼容性来看,AAC 和 OPUS 更出众一些。目前 AAC 应用于众多音乐播放器和音乐格式封装中,OPUS 常见于语音通信中。当然还有很多其他的音频编码压缩的方法,这里我就不一一列举了。在后面我们会接触到更多的音频压缩技术与方法。
不知道你有没有发现,现在使用 AAC 编码格式的次数越来越多了,为什么大家突然都开始用 AAC 做音频编码了,以前很火的 MP3 呢?其实 MP3 也还在用,只不过 MP3 的音频编码压缩方式相对于 AAC 来说,性价比低了一些。对比二者的高音质,AAC HEv2 无论是从码率、清晰度还是音频的还原度来说,都比 MP3 更优秀。详细的对比数据,我们会在后面讲 FFmpeg 具体操作音频编码与解码的时候介绍到,这里你稍加了解即可。
小结
到这里,音频基础内容就讲完了,我们了解了音频的采样格式、音频采样率、音频声道及其布局、采样位深度,最后学会了计算音频码率,这些内容在后面我们都会频繁地用到,尤其是当我们做音频编码与解码的时候,需要考虑到这些参数的兼容情况。

而在我们做音频压缩的时候,也需要考虑自己的音频用于哪些场景,比如做音频通话的话可以考虑使用 OPUS,因为基于 OPUS 的音频,处理语音更方便一些,例如回声消除,降噪等。如果是做音乐压缩,我们可以考虑 AAC,因为 AAC 支持的音质与硬件兼容性更好一些。如果还要效果更好,但不太要求兼容性的话,AC-3 是一个不错的选择,因为杜比之类的音频,尤其是在全景声音乐压缩的场景下,使用 AC-3 做音频压缩效果更好,能够听到的细节会比 AAC 压缩的音频更多一些。
思考
当我们播放一段 PCM 音频的时候,声音听上去比正常声音显得更尖更细,但是速度是正常的,是什么原因呢?
如何做音视频的封装与转码?
我们平时看视频、拍视频,还有传输视频的时候,经常出现播放不了,报错的情况。这主要是因为我们拿到的文件格式有很多不同的种类,比如 RMVB、AVI、WMV、MP4、FLV 等,而里面的视频编码格式也有很多种,比如 Mpeg-4,所以播放器既要能够解析出对应的文件格式,又要能够对文件中的音视频流进行解码,只要有一个不支持就会导致视频播放出错。这个时候我们就需要给视频做一下转码。
视频转码主要涉及编码压缩算法(Encoding)、格式封装操作 (Muxing)、数据传输 (例如 RTMP、RTP)、格式解封装(Demuxing)、解码解压缩算法(Decoding)几方面的操作。这些操作需要一个共识的协定,所以通常音视频技术都会有固定的参考标准,如封装格式标准、编解码操作标准、传输协议标准等等。
标准中没有写明的,通常兼容性不会太好。例如 FLV 参考标准协议中没有定义可以存储 H.265 视频压缩数据,如果我们自己将 H.265 的视频数据存储到 FLV 容器中,其他播放器不一定能够很好地播放这个视频。所以在我们将视频流、音频流写入到一个封装容器中之前,需要先弄清楚这个容器是否支持我们当前的视频流、音频流数据。
如果你对音视频编解码、视频封装、MP4 格式几方面的知识比较了解的话,那么解决这些问题就会游刃有余了。
音视频编解码
我们先来看音视频编码方面的基础知识。就像前面两节课介绍的,音频的 PCM 数据、视频的 YUV 和 RGB 的图像数据直接存储或者通过带宽传输会比较消耗空间,那么为了节省存储,或者确保占用的带宽更少一些,就需要把音频、视频的数据压缩一下。
音频是连续的采样序列,而视频则是连续的图像序列,这些序列是有前后关系的,为了方便理解,我们用图像来举例,看上去会更直观一些。
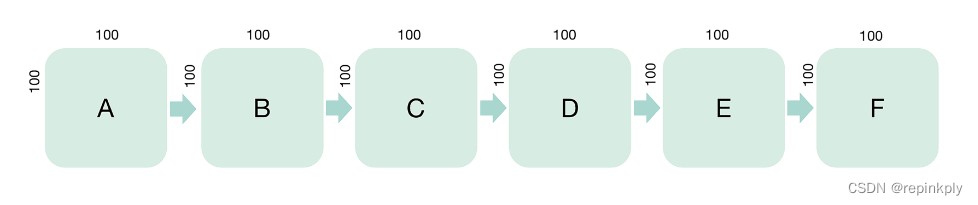
图1 连续的视频图像
我们有一个 6 帧的连续视频图像,每一帧都是宽 100、高 100 的画幅,在每一帧的正中央都有一个字母在变化。遇到这种情况时,如果我们每一帧图像全都做传输或存储操作的话,占用的带宽或空间都会很大。
为了节省空间,我们可以来分析一下图像的规律。因为这 6 帧图像大范围是相同的,只有正中心的一小部分内容是变化的,所以我们分析后可以得到结论,刷新第一帧图像后,从第二帧开始,我们只要刷新正中心字母区域的内容即可。这个叫局部更新,只需要逐步更新 A、B、C、D、E、F 的区域就可以了,这样在传输内容的时候既节省带宽,又能在存储内容的时候节省画幅的数据存储空间。
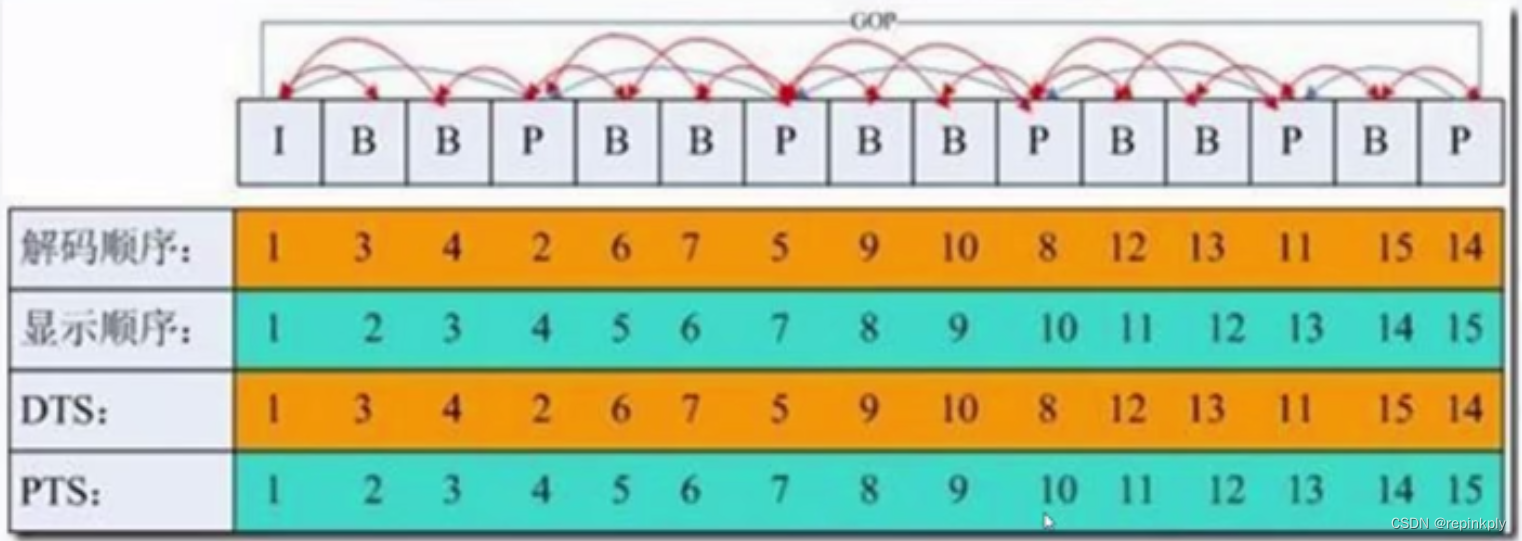
而我们在看视频的时候可不仅仅是内容的更新,还涉及内容位置的运动等变化,所以视频内容更新的算法会更复杂一些。在做视频压缩的时候,就拿前面的这个例子来说,需要有一个参考帧,这里参考的是第一帧,后面每一帧都参考前面一帧做了局部更新。而我们的视频图像序列不能只做局部更新,因为里面的目标对象还会运动,所以我们不仅可以前向做参考,还有可以做双向参考的技术。在这个过程中就涉及了图像的类型,通常我们遇到的是这三类帧:I 帧、P 帧和 B 帧。
其中 I 帧作为关键帧,仅由帧内预测的宏块组成。而 P 帧代表预测帧,通过使用已经编码的帧进行运动估计,B 帧则可以参考自己前后出现的帧。如果比较 IBP 帧包所占空间大小的话,通常是 I 帧>P 帧>B 帧,所以适当地增加 B 帧可以减少视频流占用的带宽或者存储空间。我们可以看一下,I、P、B 帧在视频解码显示时的顺序。
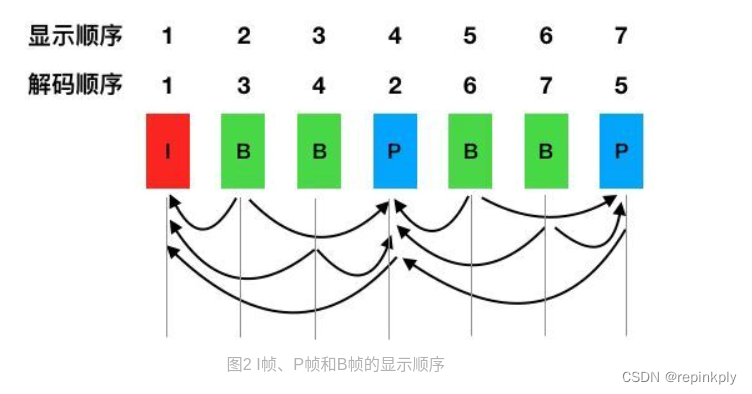
从这个示意图里,我们可以看出,解码顺序是 1423756,但是显示顺序却是 1234。当编码中存在 B 帧的时候,因为解码需要双向参考帧,所以需要多缓存几帧作为参考数据,从而也就带来了一定的显示延迟。所以在实时直播场景下,参考标准中推荐的做法通常是不带 B 帧。
在视频编码时,因为图像的画面以及图像中对象运动的复杂程度比较高,为了保证清晰度,运动的图像组中通常也会包含更多的图像运动参考信息,所以压缩难度也提升了很多,压缩后的视频码率也就变得比常规图像更高一些,这个码率的波动通常时高时低,具有可变性,我们一般称之为可变码率(VBR)。
而在有些直播场景下,因为一个传输信号通道中会携带多条流,为了确保多条流在同一个信号通道中互不干扰,一般会要求编码时采用恒定码率的方式(CBR)。但是如果采用 CBR 的话,画质往往会有一些损耗,这也就是为什么我们现在在一些老式的电视直播场景中看到的画质偶尔会变得很差,比如交通广播电视场景。
视频封装
我们平时经常会听到有人说自己的视频是 MP4 格式的,有些人也会说自己的音乐格式是 M4A,这些都是什么意思呢?
其实我们可以粗略地认为他们说的是封装格式,也就是常说的容器格式。在容器格式的内部会存储音频、视频的数据,这些数据我们可以称之为视频流、音频流。音视频流在容器中的存储形式有两种,既可以交错式存储,也可以是不同类型的流单独存储在自己的连续区域。
我们用两张图来说明一下问题。
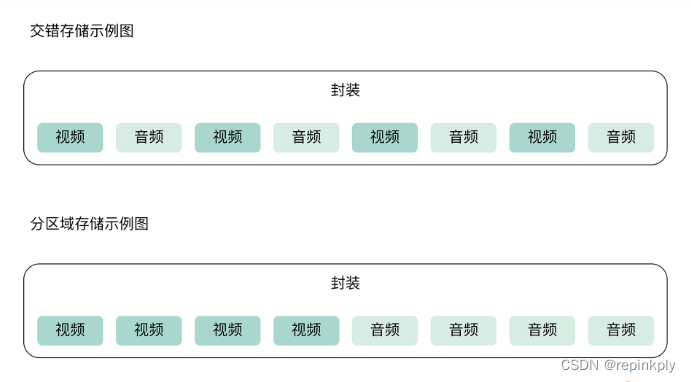
音视频流的两种存储方式
这两种方式都比较常见,也都各有利弊,后面我们介绍具体的封装容器格式时会做详细地说明。
音视频编码后的数据流与封装的关系如果根据上面两张图来理解可能会略微抽象,我们如果以生活中的例子来说明的话,可以这么理解音视频编码数据流与封装的关系:我们有一碗稻米,可以理解为每一粒米都是一帧视频数据,例如 H.264。我们还有一碗小米,可以理解为每一粒小米都是一个音频采样,例如 AAC。我们把稻米和小米装到一个袋子里,这一袋装有稻米和小米的整体叫做音视频封装容器格式,例如 MP4、FLV。
接下来,为了方便你理解,我们以互联网中最常见的封装格式——MP4 为例,来详细地讲一讲音视频封装容器格式
封装容器格式:MP4
在互联网常见的格式中,跨平台最好用的应该是 MP4 文件,因为 MP4 文件既可以在 PC 平台的 Flashplayer 中播放,又可以在移动平台的 Android、iOS 等平台中播放,而且使用系统默认的播放器就能播放,因此我们说 MP4 格式是最常见的多媒体文件格式,接下来我们就来详细地看一下 MP4 这种文件格式。
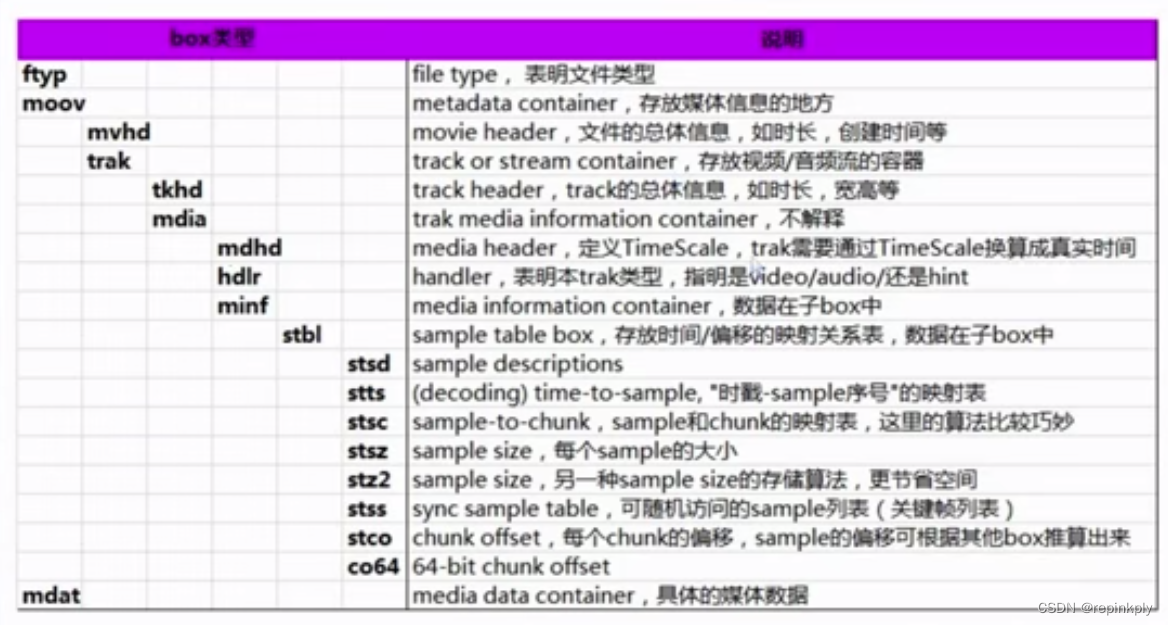
MP4 格式标准为 ISO-14496 Part 12、ISO-14496 Part 14,标准内容并不是特别多,如果要了解 MP4 的格式信息,我们首先要清楚几个概念:
MP4 文件由许多个 Box 与 FullBox 组成;
每个 Box 由 Header 和 Data 两部分组成;
FullBox 则是 Box 的扩展,在 Box 结构的基础上,在 Header 中增加 8bit 位 version 标志和 24bit 位的 flags 标志;
Header 包含了整个 Box 的长度的大小(Size)和类型(Type),当 Size 等于 0 时,代表这个 Box 是文件中的最后一个 Box;当 Size 等于 1 时说明 Box 长度需要更多的 bits 位来描述,在后面会定义一个 64bits 位的 largesize 用来描述 Box 的长度;当 Type 为 uuid 时,说明这个 Box 中的数据是用户自定义扩展类型;
Data 为 Box 的实际数据,可以是纯数据,也可以是更多的子 Box;
当一个 Box 中 Data 是一系列的子 Box 时,这个 Box 又可以称为 Container Box。
而 MP4 文件中 Box 的组成,你可以仔细阅读一下参考标准 ISO-14496 Part 12,我们这里就不再逐字解读了。但是有几个关键的 Box 我们需要知道。
MP4 封装格式文件中,我们经常会遇到 moov box 与 mdat box。我们存储音频与视频数据的索引信息,就是存在 moov box 中,音频和视频的索引信息在 moov 中分别存储在不同的 trak 里面,trak 里面会保存对应的数据采样相关的索引信息,通过获得 moov 中的索引信息之后,根据索引信息我们才能从 mdat 中读取音视频数据,所以 MP4 文件中必不可少的是 moov 信息,如果缺少 moov 信息的话,这个点播文件将无法被成功打开。
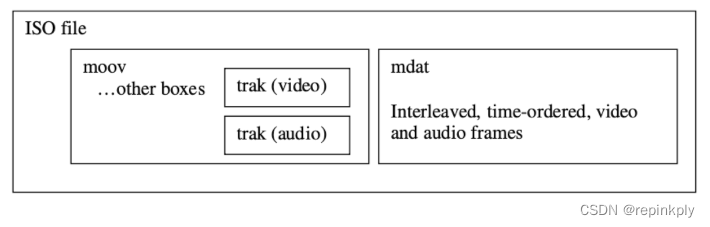
关于 MP4 封装里面能否存放我们当前想存的 codec,还需要查找一下参考标准或者公共约定的标准,看看是否允许存放,你可以参考MP4 网站里面的表格。
我们刚才介绍视频封装的时候有提到过,音视频数据存储的时候有交错存储的方式也有音频存在一个区域,视频存在一个区域的方式。其实两种方式都比较常见,但是需要注意一个问题,我们在存储音视频数据的时候,如果是顺序读取音视频数据的话,当然就是音视频数据交错存储比较好,这样会给内存、硬盘或者网络节省很多开销。
如果音视频分开,单独存放在各自的区域的话,为了更好地做音视频同步,通常会读取一段视频帧数据,再读取一段音频采样数据,这样势必会不断跳跃式地读取硬盘中的数据,或者不断地发起网络请求,如果是 http 请求的话,我们会看到大量的 http range 请求,给网络开销与服务器并发造成很大的压力。
当我们基于网络请求播放 MP4 点播文件时,如果 moov box 存储在 mdat box 后面的话,播放器需要先读取到 MP4 文件的 moov 以后,才能够开始播放 MP4 文件,而这个读取的动作,有些播放器是选择先下载全部 MP4 文件,有些则是需要先解析一下 mdat,跳过 mdat 以后再读取 moov,所以为了节省播放器操作,兼容性更好,通常我们需要将 moov 移到 MP4 文件的头部,节省播放 MP4 文件开始时间段的开销。
这里我们需要注意的是,这个 moov 的生成,一般需要先写入 mdat 中的音视频数据,这样我们就知道数据采样存储的位置和大小,然后才能写入到 moov 中,所以是先写入 mdat 后写入 moov 这样一个顺序。解决办法是生成文件之后做一个后处理,也就是将 moov 移动到 mdat 前面。
小结
我们对音视频编码的基础操作方式,视频封装的基本原理有了一个大致的了解,对于常见的点播视频文件 MP4 也有了一个基础的认识,并且了解了一些常见的 MP4 视频点播问题。其实,我们这节课在视频点播文件中选择去介绍 MP4,主要还是因为 MP4 是最常用的一个,你理解起来也会更容易。当然也有一些其他的视频点播格式,在之后的课程还会涉及,例如 MKV、FLV、MPEGTS 等。
这里,我们只要记住一个重要的信息,在音视频技术领域,编解码、封装格式都有对应的参考标准,并且都是开放标准,我们要善于借助网上搜到的参考标准文档和详细的解析资料,如果你希望对音视频技术有更深的了解,除了学习的基础知识外,还是需要自己动手实操,照着参考标准写一下对应的实现代码。
思考
我们讲解了 MP4 文件可以作为视频点播文件,那么 MP4 是否能够应用于直播场景中呢?怎么处理才能够支持直播?
MPEG-4
- 音视频基础知识,主要包含:封装、解码、重采样、像素格式等等。写一篇文章简单的介绍一下这些基础知识。对于音视频的封装和编码是由一个国际组织提出来的一个标准 MPEG-4。
- MPEG-4 是一套用于音频、视频信息的压缩编码标准。MPE-4 Part 14 MPEG-4文件格式 Part 15 AVC文件格式。
- H264 (AVC)
常用封装格式
- AVI 压缩标准可任意选择。
- FLV ts 流媒体格式
- ASF
- mp4
常用编码格式
- 视频H264 (AVC) ,wmv , XviD ,mjpeg
- 音频 acc MP3 ape flac
封装格式和编码格式
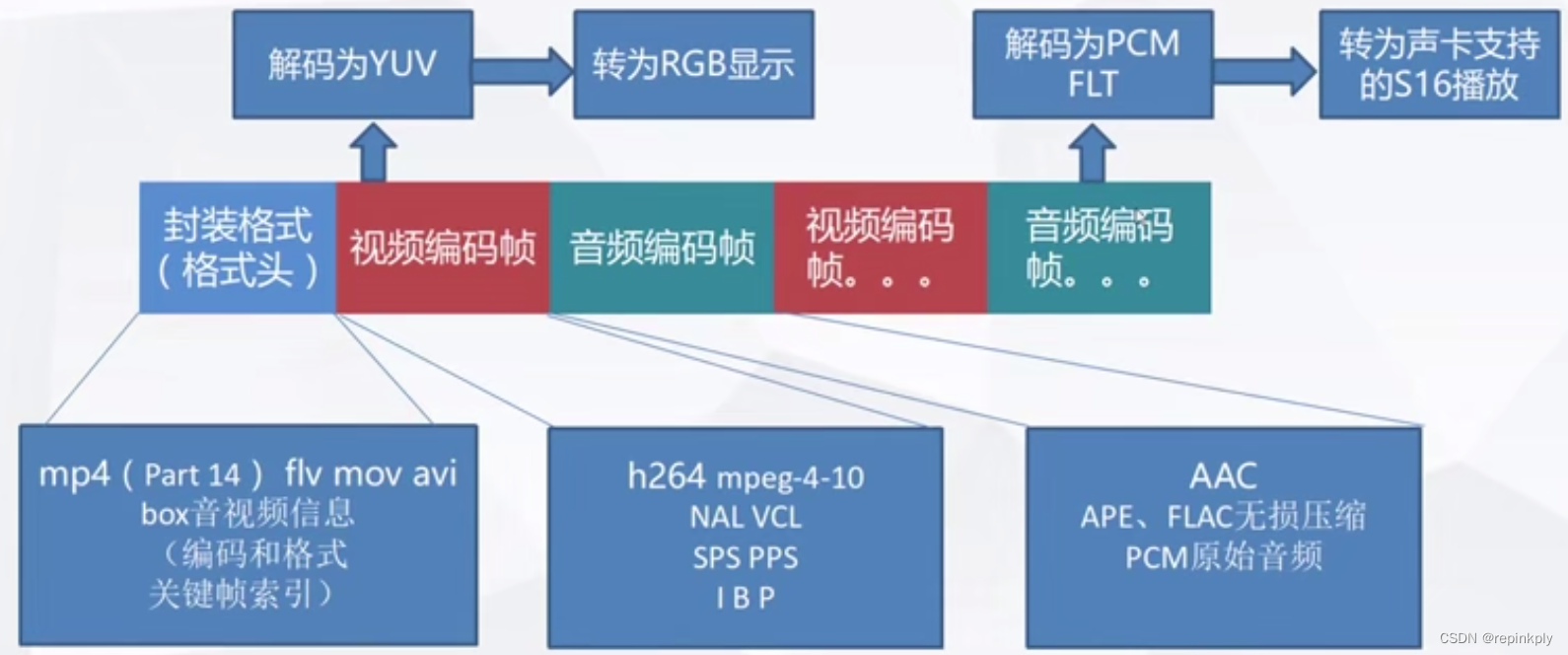
像素格式

3X3RGB图像存放方式(连续)
YUV
- "Y" 表示明亮度,也就是灰度值。
- 而 "U" 和 "V" 表示的则是色度。

MP4 格式分析
H.264/AVC 视频编码标准
视频编码层面(VCL)
-视频数据的内容
网络抽象层面(NAL)
-格式化数据并提供头信息
NAL单元
因此,我们平时的每帧数据就是一个NAL单元(SPS与PPS除外)。在实际的H264数据帧中,往往帧前面带有00 00 00 01 或 00 00 01 分隔符,一般来说编码器编出的首帧数据为 PSS与SPS,接着为 1 帧。
GOP



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











