







关 注 公 众 号,获 取 更 多 技 术 好 文~
摘要:今天分享的内容是Doris在作业帮实时数仓架构中的应用及实践
分享时间:2021年6月05日
内容分享:利敏
摘要整理:皮卡丘
主要内容:
1、作业帮业务与背景
2、基于Doris的实时查询系统
3、未来规划

Apache Doris
支持对海量大数据进行快速分析的MPP数据库
Apache Doris一款基于大规模并行处理技术的交互式SQL分析数据库,仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析Apache Doris由百度于2018年贡献给 Apache 基金会,目前正在孵化

一、业务背景介绍
1、数仓逻辑分层
2、过去的业务支持模式
3、总体架构图
4、成效收益
1.1、数仓逻辑分层:
提到数仓,绕不开的话题就是如何分层,但在这个问题上大家好像有个统一的答案,来,上架构图吧:

注:大数据团队主要负责ODS-DWS的建设,从DWS到ADS一般是数仓系统和业务线系统的边界。在过去,由于缺失统一的查询系统,探索了很多模式来支持各个业务线发展。
PS:虽然架构趋同,但在不同的业务模式和场景下,各个企业都有着自己鲜明的特点,正所谓“君子和而不同”。但殊途同归,最终都是为了给业务赋能~
1.2、过去的业务支持模式:
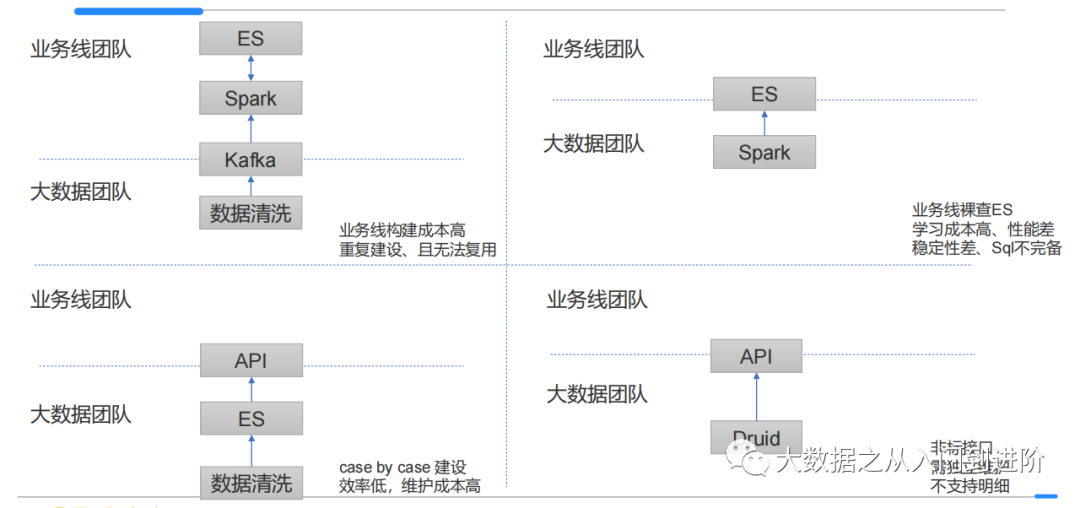
架构拆解:
非流量类:
Kafka:业务线从kafka接数据自己做数据的聚合计算,主要问题在于完全没有数仓的概念,业务线在做大量重复的建设
Spark + ES:每来一个业务需求,就构建一个Spark+ES集群(spark负责计算写入到ES,ES供业务层直接使用)。效率低、ES的接口以及内部原理学习成本高,对于业务线很难有这样的精力去做
ES + 自定义API。大数据将数据写入ES后,并case by case构建api。初步有了数仓的接口,但是接口不具备Sql的能力,只能基于需求case by case的构建,效率太低。
流量类(如pv、uv等):
由于数据量大,往往需要预聚合,引入druid
痛定思痛:
这些烟囱式的系统构建方式,导致系统越来越难以维护,且业务接入效率也逐步降低
统一整个查询引擎,对于数仓建设在提高业务支持效率、降低维护成本上都具有非常重大的意义
PS:如切如磋,如琢如磨,好的架构,总是建立在过去之上的。没有更好,只有更适合时下的业务场景,所以千万不要掉进惯性的陷阱
1.3、总体架构:
经过过去数月的探索与实践,团队确立了以Doris为基础的数仓实时查询系统。同时也对整个数仓的数据计算系统做了一次大的重构,最终整体的架构图如下&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7687
7687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









