







 本文详细介绍了Python的内置数据类型,包括数值类型(如int、float、complex)、迭代器类型、序列类型(如list、tuple、range)以及文本类型str。内容涵盖这些类型的运算、比较、方法以及特殊属性,如位运算、哈希值计算、生成器、序列操作等。此外,还讨论了字典和上下文管理器的使用,以及特殊属性和内置对象。
本文详细介绍了Python的内置数据类型,包括数值类型(如int、float、complex)、迭代器类型、序列类型(如list、tuple、range)以及文本类型str。内容涵盖这些类型的运算、比较、方法以及特殊属性,如位运算、哈希值计算、生成器、序列操作等。此外,还讨论了字典和上下文管理器的使用,以及特殊属性和内置对象。
本章主要说明那些被内建到解释器的标准类型,主要的有数值,序列,映射,类,实例,例外。
一些运算符被多种类型支持,实际上所有的类型都可以被比较,检验真假,转换成字符串(repr(),str()后者会被print隐式调用,str的返回和只有第一个参数的print一样)。
因此下文首先介绍这些被支持的运算,之后介绍内置类型数值,序列,映射,类,实例,例外。
运算
真值检验,布尔值运算,比较
真值检验
默认的一个对象被认为是True,除非这个类定义了返回False的__bool__()方法或者是返回0的__len__()。
class Bealoonfalse():
def __bool__(self):
return False
def __index__(self):
return 2
pass
class Booleantrue:
pass
class Comp:
def __le__(self, other):
return True
class Comp1:
def __init__(self,a):
self.a = a
def __ge__(self, other):
if self.a ==0:
return False
else:return NotImplemented
t = Booleantrue()
f = Bealoonfalse()
c = Comp()
c10 = Comp1(0)
c11 = Comp1(1)
print(bool(t),bool(f),bin(f),hex(f))#True False 0b10 0x2
print(t==f)# false不报错
print(t>f)#报错没有方法__lt__(), __le__(), __gt__(), and __ge__(),无法比大小
print(c<=1)# c定义了__le__(),返回true
print(c10>=c,c11>=c) #首先调用前面操作数的__ge__,返回Notimplemented在调用后面操作数的__le__ 方法。
下面列举大部分false的内置对象:
被认为是false的常量:None False
各种数值类型的0: 0,0.0,Decimal(0)
空的序列和集合:[],(),{}
布尔值运算符–and or not
短路运算
x or y: if x is false,then y,else x 短路运算符,就是说如果x为true就不里y了
x and y :if x is false, then x, else y。短路运算符
not x:if x is false, then True, else False。not的优先运算级比非布尔值运算的运算符低,如not a = = b等价于not(a = = b);而a == not b 是语法错误。
比较
boolean运算符,运算优先级相同,任意相连如a< b >ca< b and b>c and c<z(主要and是短路运算)。
大于啥的不说了
!= 不等于;is id相同;is not id不同。
说明:
1,不同了类型除了(不同数值类型),不会= =;不同类型(内部没有定义order方法的)的比较(大于小于)会报错。
2,不同id的实例不会= =除了其类中定义了__eq__()方法。
3,一个实例不能与本类实例或者是其他类型实例比较大小(不是= =和!=),除非定义了order方法:lt(), le(), gt(), and ge().
4,is ,is not不会报错,但也不能自定义
5,还有两种运算符,in和not in支持iterable或者执行__contains__方法的。
内部类型
这些都适用布尔运算。
数值类型们 int,float,complex(不是一种类型)
有三种数值类型整数,浮点型和复数,另外,布尔类作为int的子类。
int无限精确度(二进制数表示整数不会约等于);
而浮点型(1.1转成2进制,就不得不有精确的了),float是用C的double实现的,关于精确度可以在sys.float_info查看,返回一个tuple。
inport sys
sys.float_info[0]
1.7976931348623157e+308
复数的实虚部分都是浮点类型。数字字面值如(1,1.0)后加J或者j,产生一个复数的虚部。
注意在声明复数虚部时字母j或J前必须跟一个数值字面值(int,flaot)。
此外Python支持混合运算如,1+1.0:会把1转成float计算,而1.0+1J:会把1.0转成复数;数值类型的比较也遵循这种规则。(而如后文提到的bytes-like对象的混合运算和set、frozenset的混合运算,返回值的类型与操作符前面的操作数相同)
所有的(除了complex)都支持一下操作符以优先度递增排列、
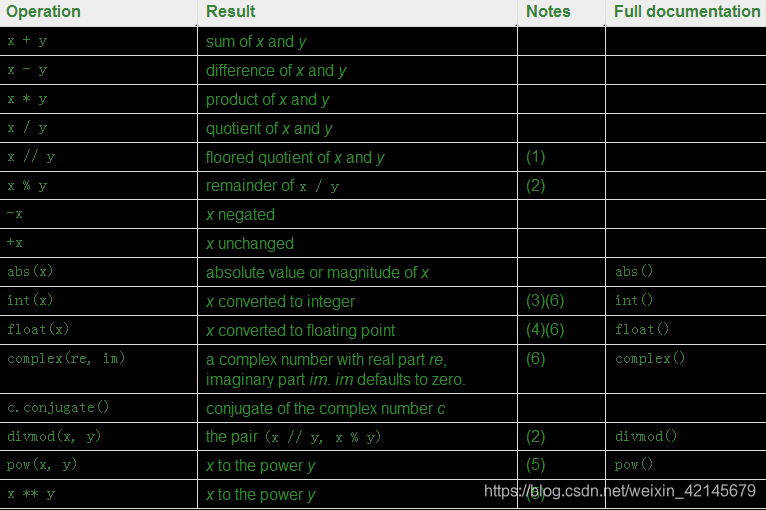
notes:
1.//做除法后,对商取整(以数值最小为标准),如-1//2,商为-0.5,取整-1或者0,-1<0,所以答案为-1.
2,complex不可用,复数不可求余数,其他都支持。
3,round或者直接取整数部分,具体看math.floorhe math.ceil.
4.float接受字符串‘nan’,‘inf’和‘+’,‘-’
5.0**0等于1
6.对于数值类型的构建函数,0-9数字或者相应的unicode值组成的数字字面值都可以接受。int(b’1’)
int和float还支持以下操作:
| 操作 | 结果 |
|---|---|
| math,trunc(x) | 截取整数部分 |
| round(x,[,n]) | 保留n位小数,x会约等于最接近的y*10**(-n),y为整数,结果取y,两个y值,取偶数y |
| math.floor(x) | 取整结果<=x |
| math.ceil | 取整>=x |
对round举个例子。
当然这得看你的python版本,哎我的是3.6
round(1.5),取2
round(0.5)取0
然而round(2.675, 2) 取2.67,为什么呢,因为上文说过(电脑是无法精确表示浮点值的原因上面有),看是2.675,电脑眼里他就比2.675小一点一点,round后取最近的就变成了2.67了。因此建议,用round看场合。
int的位运算
只适用于int,计算优先级比数值计算±之类的低,高于比较与运算;但~和(y+x ,x-y)优先级一样
~1+2
0
(~1)+2
0
~(1+2)
-4
优先级递增。

1,n不可以为负,提起valueerror
2,相当于不检查溢出的x*pow(2,n)
3,相当于不检查溢出的x/pow(2,n)
4,Performing these calculations with at least one extra sign extension bit in a finite two’s complement representation (a working bit-width of 1 + max(x.bit_length(), y.bit_length()) or more) is sufficient to get the same result as if there were an infinite number of sign bits.
溢出错误:
当计算结果过大时,会提出这个错误,int一般不会提出溢出错误而胡思memoryerror,因为历史原因,溢出错误会被在需求之外的int提起;因为c缺少标准的福地安置错误处理,大多数float计算不会被检查。
int的其他方法
int执行抽象类number.Integral,除外提供其他方法。
int.bit_length()
返回int二进制除了符号和前缀的的长度。
n = -37
bin(n)
n.bit_length()#6
*int.to_bytes(length, byteorder, , signed=False)
返回代表int的字节列
length:有几个字节表示,长度不够表示的溢出错误
byteorder:‘big’正常顺序,‘‘small’’反过来
signed:当int为负数,只应该声明为True,数值是正数的byte的每一位被15(f)减。
>>> (1024).to_bytes(2, byteorder='big')
b'\x04\x00'
>>> (1024).to_bytes(10, byteorder='big')
b'\x00\x00\x00\x00\x00\x00\x00\x00\x04\x00'
>>> (-1024).to_bytes(10, byteorder='big', signed=True)
b'\xff\xff\xff\xff\xff\xff\xff\xff\xfc\x00'
>>> x = 1000
>>> x.to_bytes((x.bit_length() + 7) // 8, byteorder='little')
b'\xe8\x03'
*classmethod int.from_bytes(bytes, byteorder, , signed=False)
>>> int.from_bytes(b'\x00\x10', byteorder='big')
16
>>> int.from_bytes(b'\x00\x10', byteorder='little')
4096
>>> int.from_bytes(b'\xfc\x00', byteorder='big', signed=True)
-1024
>>> int.from_bytes(b'\xfc\x00', byteorder='big', signed=False)
64512
>>> int.from_bytes([255, 0, 0], byteorder='big')
16711680
float的其他方法
float类执行抽象类numbers.Real,float还定义了如下方法:
float.as_integer_ratio():
返回(int1,int2),int1/int2==float,符号一直在int1上。有无限大提出overflowerror,NaNs,valueerror。
**float.is_integer():**例如
>>> (-2.0).is_integer()
True
>>> (3.2).is_integer()
False
python数值内部用二进制储存,所以转换成浮点型或是从一个小数字符串常常有小的约等于的错误,而16进制的字符串可以精密的表示浮点数,这个可以用来debug和做数值工作。下面两个方法,
float.hex()
注意和内置方法hex()比较,int的hex形式用hex(int)获取。
返回的字符串0x开头,p和指数结尾。
形式如下
[sign] ['0x'] integer ['.' fraction] ['p' exponent]
,
>>> float.fromhex('0x3.a7p10')
3740.0
(3 + 10./16 + 7./162) * 2.010, or 3740.0:a就是10
classmethod float.fromhex(s)
>>> float.hex(3740.0)
'0x1.d380000000000p+11'
数值类型们的哈希值hash()是如何计算的
(int,fraction.Fraction;和有限的float,有限的decimal.Decimal)类型的x,y在比较时,其实都是hash(x)和hash(y)比较。
P = sys.hash_info.modulus,机器位数62,32;P=2*(62[32]-1)-1,上面还提到过sys.float_info)*
hash(x)的规则如
import sys, math
def hash_fraction(m, n):
"""Compute the hash of a rational number m / n.
Assumes m and n are integers, with n positive.
Equivalent to hash(fractions.Fraction(m, n)).
"""
P = sys.hash_info.modulus#P值
# Remove common factors of P. (Unnecessary if m and n already coprime.)
while m % P == n % P == 0:
m, n = m // P, n // P
if n % P == 0:
hash_value = sys.hash_info.inf
else:
# Fermat's Little Theorem: pow(n, P-1, P) is 1, so
# pow(n, P-2, P) gives the inverse of n modulo P.
hash_value = (abs(m) % P) * pow(n, P - 2, P) % P
if m < 0:
hash_value = -hash_value
if hash_value == -1:
hash_value = -2
return hash_value
def hash_float(x):
"""Compute the hash of a float x."""
if math.isnan(x):
return sys.hash_info.nan
elif math.isinf(x):
return sys.hash_info.inf if x > 0 else -sys.hash_info.inf
else:
return hash_fraction(*x.as_integer_ratio())
def hash_complex(z):
"""Compute the hash of a complex number z."""
hash_value = hash_float(z.real) + sys.hash_info.imag * hash_float(z.imag)
# do a signed reduction modulo 2**sys.hash_info.width
M = 2**(sys.hash_info.width - 1)
hash_value = (hash_value & (M - 1)) - (hash_value & M)
if hash_value == -1:
hash_value = -2
return hash_value
迭代器类型
container._ iter _():返回一个iterator
iterator必须有以下方法:
iterator._ iter ():
返回iterator自身
iterator. next _():他被要求准许容器和迭代器可以和for,in语句一起使用。
返回容器中下一个的元素,如果没有了提出stopiterator exceptions。
Once an iterator’s next() method raises StopIteration, it must continue to do so on subsequent calls. Implementations that do not obey this property are deemed broken.
生成器
生成器更加便利的执行interator协议,container._ iter ()作为生成器,会自动返回一个iterator对象(应该说是生成器,他提供了 iter ()和 next _)
序列类型-list tuple range
常见序列操作
优先度递增排序,之后优先级会进行整理这里不再赘述
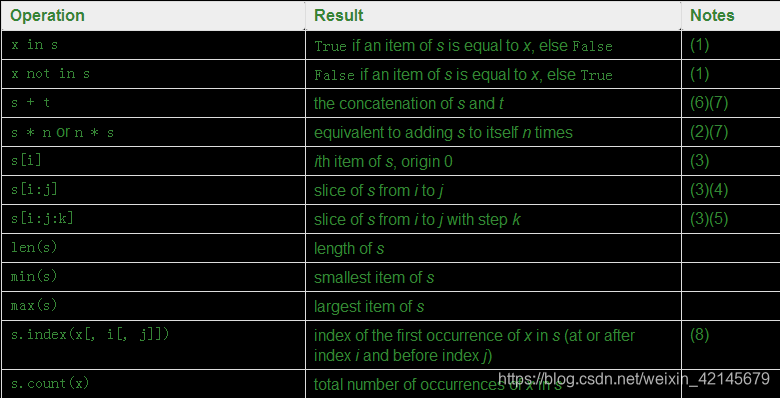
notes:
1,in和not in在 str, bytes and bytearray也有使用:
"gg" in "eggs"#true
2,注意看 a = [[]]*3和a = [[], [], []]的区别。前者使用的是引用。[详见](https://docs.python.org/3.6/faq/programming.html#faq-multidimensional-list)
>>> lists = [[]] * 3
>>> lists
[[], [], []]
>>> lists[0].append(3)
>>> lists
[[3], [3], [3]]
>>> a =[[], [], []]
a[0].append(3)
>>>a
[[3], [], []]
>>>b = [[]]
a = b*3
a[0].append(3)
>>>a
[[3], [3], [3]]
>>>b
[[3]]
3, s[-i]就是指倒数第一个或者是len(z)-i
4,对于s[i:j],j省略或者大于len(s),则被认为为len(s);如果i省略,被认为0
>>>a = [1,2]
>>>a[:100]
[1, 2]
5,s[i:j:k]:返回index为 i + n*k,index一定不可以超过j。k可以为负值。注意下面第一个例子
a =range(20)
a[::-2]
range(19, -1, -2)
list(a[::-2])
[19, 17, 15, 13, 11, 9, 7, 5, 3, 1]#默认倒序
上例第三个参数为负,默认倒序
>>>list(a[18:2:-2])
[18, 16, 14, 12, 10, 8, 6, 4]
>>>list(a[2:18:2])
[2, 4, 6, 8, 10, 12, 14, 16]
6,s+t,链接不可变序列会得到一个新的对象,通过重复+构建序列,会造成在运行时会占用额外空间,可以采取以下方式避免这个问题。注意是不可变的序列(之后在bytes中会提到memoryview)
联系str对象,建立一个list后用str.jion,或者不断写入io.StringIO对象后再取出
联系bytes,bytes.join() 或者 io.BytesIO
联系tuple,extend一个list就可以了。
联系其他:查找相关类文献
不可变序列
唯一的不可变支持而可变的不支持的是内置函数hash()。
可变序列
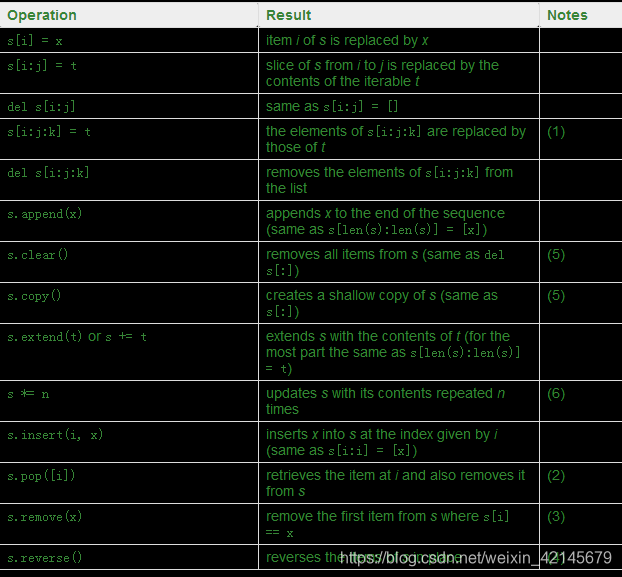
1,t一定要和被替换的slice长度相同
2,s.pop(i)默认pop最后一个,即i = -1或者len(s)-i
3,s.remove(x),当找不到x,突出valueerroe
4,s.reverse(),改变s不创建新对象。
5,dict和set也支持a.copy
6,n是一个int或者是有返回int的_ index _方法的对象,n非正数,clear,*和上面一样是引用没有复制。
list
list 一般构建方式:
a =[],[1,2]
[x for x in iterable] 很常用,简化for代码,[x+y for x in iter1 for y in iter2 也可以
list()
当然还有许多函数返回list
class list([iterable])
构建一个和iterable的items元素都一样且顺序一样额的list,不参数输出[]
list执行所有的常用和-可变计算(如上面提到的),还有以下方法
sort(*, key=None, reverse=False)
与sorted不同的是,sorted返回一个新list,而sort改变自己
tuples
a = (1,2)
b = [1,2]
sys.getsizeof(a)
64
sys.getsizeof(b)
80
相同items顺序的list和tuple占用的内存就差16,tuple之所以用来储存,应该不是内存占用的原意,是不可改变吧,保险。
构建tuple
(),(1,),(2,3,4)
a =1, a = 1,2,3
tuple()和其他函数构造
class tuple([iterable])
类比list
ranges
不可变序列
class range(stop)
class range(start, stop[, step])
参数是一个int或者是有返回int的_ index _方法的对象,list的里也适用如list[a],a对象又反悔int的__index__方法。,step默认1;Ranges containing absolute values larger than sys.maxsize are permitted but some features (such as len()) may raise OverflowError。
range执行 collections.abc.Sequence ABC,in,not in,index查找,切割slice,负index。
>>> r = range(0, 20, 2)
>>> r
range(0, 20, 2)
>>> 11 in r
False
>>> 10 in r
True
>>> r.index(10)
5
>>> r[5]
10
>>> r[:5]
range(0, 10, 2)
>>> r[-1]
range(0) = = range(2, 1, 3),range相同只要内容顺序一样就行。
Changed in version 3.3: Define ‘==’ and ‘!=’ to compare range objects based on the sequence of values they define (instead of comparing based on object identity).
Text Sequence Type — str
文本序列类型,str’unicode码点的序列。
单引号
双引号
三引号,多行,常用于注释,可见内置函数help()
字面值作为表达式的一部分,两个字面值之间只有0到多个空格隔开时,会把他们连成一个str的字面值
('b' 'd') =='bd'#True
字面值1,‘sd’,1.0这些都是字面值,
当时用open(r’C:\Users\Administrator\Desktop\1.txt’,‘a’),可见字符串前加了r,这表示拒绝转义
而前缀加u没意义,且u和r不同时用
'\1'#会自动转义为'\x01'
str不同与其他序列如[1,2,3,4,5],元素用逗号隔开;
a = '1,2,3'
a[1]#会返回逗号
没有可变字符穿类型,但通过str.join和io.StringIO可以拼合构建str。
class str(object=’’)
会返回对象的_ str (),如果object是str就返回本身,如果没有 str _()方法,调用repr(object),
如果ob是bytes或bytearray。
>>> str(b'Zoot!')
"b'Zoot!'"
class str(object=b’’, encoding=‘utf-8’, errors=‘strict’),
如果encoding和errors至少给了一个那么,object是一个bytes或bytearray对象,然后str(ob,encode,error)相当于bytes.decode(encoding, errors),另外the bytes object underlying the buffer object is obtained before calling bytes.decode(). See Binary Sequence Types — bytes, bytearray, memoryview and Buffer Protocol for information on buffer objects
字符串方法
常见序列的操作,格式,文本服务处理,还有方法。
str支持所有常见序列的操作,下面指出其他一些
str还支持两种格式一种灵活定制化的(str.format()),另一种基于C printf格式(后面会介绍就是用%识别操作)适用类型较少不太好用,但快。
文本处理服务部分还提供了许多其他模块如re
方法如下:
str.capitalize():首字母大写
str.casefold():都小写,比lower()更加激进如:德语的 小写字符’ß’相当于ss,因为本身是小写的了因此lower无变化,但casefold会把他转成‘ss’
算法在unicode standard
str.center(width[, fillchar]),么错,就是添加fillchar使str居中
a = 'ß'
a.center(4,'1')#'1ß11'
a ='aaaaaa'
a.center(4,'1')#'aaaaaa' 4比len(a)小返回原值
str.encode(encoding=“utf-8”, errors=“strict”)
encoding和errors的解释看open的参数
返回str的bytes。
str.count(sub[, start[, end]]):数sub在str中出现了几次
a = 'aaaabbbb'
a.count('a',3)#1
str.endswith(suffix[, start[, end]]):是不是suffix结尾的在start和end的范围内,suffix可以为tuple,只要一个元素是str的结尾,就返回True
str.expandtabs(tabsize=8)
返回一str,根据tabsize和现在的列,把原来str的tabs(\t)都用空格替换;
'01\t012\t0123\t01\n234\t2323'.expandtabs(3)#'01 012 0123 01\n234 2323'
计算过程:tabsize =3,则tab位置为0,3,6,。。。
重头开始读出不是\n,\t,\r直接复制如下
01
这时候读到了\t,这时候01的现在位置是2,在2后面的tab的位置是3,因此添加一个空格
‘01 ‘
继续读012没\t,\r,\n;
'01 012'
这时候又遇到\t这时候 '01 012'现在位置6,下一个tab的位置9,填充3个空格
‘01 012 ’
以此类推读到了
'01 012 0123 ‘
继续读01,当这时候遇到了\n(\r同理),这是现在位置重置为0(\n的现在位置为0),继续读234这时候现在位置为3,下一个tab位置为6,填充3个空格
'01 012 0123 01\n234 ’
这主要是为了排版tabssizes一般取最长的字符就行了
f = open(r'C:\Users\Administrator\Desktop\code.txt','w+')
print('join\t1993.0701\tmale\thfdjfhjf\tnihao'.expandtabs(26),file=f)
print('jackson\t1992.0201\tfemale\tfhdsjhfjdshfjd\tnihao'.expandtabs(26),file=f)
f.close()
输出在txt文件里:
join 1993.0701 male hfdjfhjf nihao
jackson 1992.0201 female fhdsjhfjdshfjd nihao
但是缺陷明显:这样设置列宽一样,不能自定义列宽。
str.find(sub[, start[, end]]),
返回start和end之间的sub在str中最小的按个index。
找不到返回-1不报错
a ='12jackjakson'
a.find('ja',1)
2
str.format()
str.format(*args, **kwargs)控制格式
>>> '{0}, {1}, {2}'.format('a', 'b', 'c')
'a, b, c'
>>> '{}, {}, {}'.format('a', 'b', 'c') # 3.1+ only
'a, b, c'
>>> '{2}, {1}, {0}'.format('a', 'b', 'c')
'c, b, a'
>>> '{2}, {1}, {0}'.format(*'abc') # *的作用unpacking argument sequence
'c, b, a'
>>> '{0}{1}{0}'.format('abra', 'cad') # arguments' indices can be repeated
'abracadabra'
str.format_map(mapping)
类似于str.format(**maping)(注意maping前必须有双星号):但是mapping是直接用的而不是复制到一个dict上的,如果mapping是dict的一个子类这是很有用的。
实参和形参的*,和**1
class Default(dict):#建立一个dict的子类
def __missing__(self, key):
#可以看出当使用__getitem__来访问一个不存在的key的时
#候,会调用__miss__()方法获取默认值,并将该值添加到字典中去
return 'China'
'{name} was born in {country}'.format_map(Default(country1='Guido'))
'{name} was born in {country}'.format(**{'name':'lqq','country':'china'})#必须有**
('{name} was born in {country}'.format(**Default(country1='Guido')))#会报错
输出
'China was born in China'
'lqq was born in china'
KeyError: 'name'
因此想使用__miss__指定缺省值,建议用后者
dict方法__miss__的介绍参照上例
str.index(sub[, start[, end]])
返回索引值,没有报错valueerror
以下都是判别是不是is后跟的部分,空false;只简单介绍:太多了进度慢了很多
str.isalnum()
字母或者数字
c.isalpha(), c.isdecimal(), c.isdigit(), or c.isnumeric().中一个True,返回True
'123RRR'.isalnum()
True
'123RR,R'.isalnum()
False
str.isalpha()
字母在unicode编码表中Letter部分
str.isdecimal()
nicode General Category “Nd”
str.isdigit()
有属性value Numeric_Type=Digit or Numeric_Type=Decimal.
str.isidentifier()
'def'.isidentifier()
True
'1'.isidentifier()
False
str.islower()
小写
str.isnumeric()
digit characters, and all characters that have the Unicode numeric value property, e.g. U+2155, VULGAR FRACTION ONE FIFTH
str.isprintable():这个空也可以true
Unicode character database as “Other” or “Separator”, excepting the ASCII space (0x20) which is considered printable. (Note that printable characters in this context are those which should not be escaped when repr() is invoked on a string. It has no bearing on the handling of strings written to sys.stdout or sys.stderr.)
str.isspace()
Unicode character database as “Other” or “Separator” and those with bidirectional property being one of “WS”, “B”, or “S”.
str.istitle()
str.isupper()
Return true if all cased characters [4] in the string are uppercase and there is at least one cased character, false otherwise.
str.join(iterable)
用str连接iterable的str元素,必须是str否则typeerror
','.join(['1','2'])
'1,2'
','.join(['1','2',3])
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: sequence item 2: expected str instance, int found
str.ljust(width[, fillchar]):l是左
左填充fillchar(默认ascii的空格)到str的长度为width
'adsa asd '.ljust(20,'1')
'adsa asd 1111111111'
str.lower()
返回一个复制的str小写
str.lstrip([chars])
返回一个复制的str,从左边删除chars(chars 的组合默认为wihitespace),
>>> 'wzw.example.com'.lstrip('cmowz.')
'example.com'
第一个w chars里有删了,第2,3,4个z,我,.,都有删了,第五个e没有。停止输出剩下的
static str.maketrans(x[, y[, z]])
返回一个翻译表,用在str.translate()
一个参数时:x是一个dict(建立从unicode序数或是长度1的字符
到unicode 序数或是任意长的str或是None。
两个参数,两个参数通长,组合一个dict参数如上
三个参数,str,str里的字符会默认映射到None。
**str.partition(sep)**返回三元tuple
'www.example.com'.partition('w')
('', 'w', 'ww.example.com')
如果sep在str里,则在index最小的sep放在tuple的中间位置,str以sep分开左右两部分,分别写在tuole的左右。
'www.example.com'.partition('w1')
('www.example.com', '', '')
sep不再str里,如上。
str.replace(old, new[, count])
替代count次;不提供count全部替换
**str.rfind(sub[, start[, end]]):**r从右边
参考str.find,从右边找,即返回index最大的;找不到返回-1
a ='12jackjakson'
a.rfind('ja',1)
6
str.rindex(sub[, start[, end]])
同理,从右,以后参考index
str.rjust(width[, fillchar])
同理
str.rpartition(sep)
同理
str.rsplit(sep=None, maxsplit=-1)
同理
str.rstrip([chars])
同理
str.split(sep=None, maxsplit=-1)
'1,2,3'.split('2', maxsplit=1)
['1,', ',3']
在str里读取遇到sep,则以sep,分割左边部分,成为list的元素。
str.splitlines([keepends])
返回一个list元素为str的每一行,如果keepens存在或者true。

str.startswith(prefix[, start[, end]])
参见endswith
str.strip([chars])
rstrip和lsrip合体,两头去
str.swapcase()
大写变小写,小写变大写
'AddsdaS'.swapcase()
'aDDSDAs'
str.title()
>>> 'hjelGo world'.title()
'Hjelgo World'
字开头大写,其他小写
str.translate(table)
a = str.maketrans({"a":'apple','b':'banana'})
'a和b是水果'.translate(a)
'apple和banana是水果'
str.upper()
大写
str.zfill(width)
左边(除了+,-)添加ASCII0,到srt的长为width
>>> "-42".zfill(5)
'-0042'
printf-style String Formatting
推荐使用foramt
Binary Sequence Types — bytes, bytearray, memoryview
python用bytes和bytearray处理二进制数据,他俩被memmoryview支持(用buffer 规则无需copy获取二进制对象的内存)
array(import array ;memory(array.array([1,23])))模块支持高效基本数据与储存。
bytes对象
class bytes([source[, encoding[, errors]]]):
和str一样单引号,双引号,三引号,只要加前缀b
在bytes的字面值中,只能存在ASCII字符(不然一定要转义)(参见内置函数ord和chr)即:下面这种情况不可以,ascii查询表2 (0-127)
和str一样可以不转义,前加r
b =rb’\x01\x02’;list(b);print(b)
b’\x01\x02’
a =b'了'
File "<input>", line 1
SyntaxError: bytes can only contain ASCII literal characters.
Any binary values over 127 must be entered into bytes literals using the appropriate escape sequence.
除了字面值的创建还有以下方法:
bytes(5)#创建长度为5的空字节
b'\x00\x00\x00\x00\x00'
下面的bytes(iterable),iterable 的元素一定是int
bytes(range(5))# iterable of int
b'\x00\x01\x02\x03\x04'
bytes(range(255,276))#in不能超过256,两位16进制最大255
Traceback (most recent call last):
File "<input>", line 1, in <module>
ValueError: bytes must be in range(0, 256)
a = b'1'#从一个bytes对象复制
bytes(a)
b'1'
补充内置bytes
**classmethod fromhex(string)**这个方法float也有
str必须有2个16进制数字每个字节,而ascii的空格会被忽略
>>> bytes.fromhex('2E2a F1f2 ')
b'.*\xf1\xf2'
>>> bytes.fromhex('2Ef0 F1f2 ')
b'.\xf0\xf1\xf2'
**hex()**这个方法float也有
>>> b'\xf0\xf1\xf2'.hex()
'f0f1f2'
注意:有一点和str不同,bytes[index]返回的是int,而str[index]返回的是str
a = '123';b=b'123';print(type(a[1]),type(b[1]))
<class 'str'> <class 'int'>
list(b)
[49, 50, 51]
list(bytes)
h会返回int的list,请看下面的例子
b =b'\x01\x02\x61';b =list(b);print(b)#返回每个十六进制的10进制数
[1, 2, 97]
b =b'12a';b =list(b);print(b)#list返回每个字符在ascii表的十进制编号
[49, 50, 97]
bytearray对象
和bytes一样,不同点在于他是可变的。
class bytearray([source[, encoding[, errors]]])
type(b'123')#可见这种字面值是bytes,bytearray不能这样构建
<class 'bytes'>
一般构建方法类似bytes:
bytearray()
bytearray(10)
bytearray(range(12))
bytearray(b'123‘)
bytearray支持渴念序列的全部操作和下面即将介绍的bytes和bytearray常见操。
classmethod fromhex(string)
参见bytes
hex()
参见bytes
bytes and bytearray操作(注意和str的比较)
bytes和bytearray都支持常见序列操作,这些在bytes-like(支持buffer protocol,export一个c-contiguous buffer;包含了bytes,bytearray,memoryview,array.array)对象中都可以操作,而返回的对象
和计算数的顺序有关
a = bytearray(b'asd')
a +b'a'
bytearray(b'asda')#a,bytearray在前,输出为bytearray。
剩下的函数和str的差不多,bytes和bytearray都可以使用
链接;
https://docs.python.org/3.6/library/stdtypes.html#bytes.count
printf-style Bytes Formatting(注意和str的比较)
Memory Views
memory对象,是的python代码可以通向对象(支持buffer protocal)的内部数据,不用借助与copy。
import sys
a = b'abcefgfdgfdgdfgdfgggqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqjfh /' \ b'ertger43545fgggggggggggggggdgshgfshgjhgjqqqqqqdsfsdfdsfdhhqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq'
b = memoryview(a)
print(sys.getsizeof(a))
print(sys.getsizeof(b))
291
192
变量a指向的内存随bytes的长度不断增加(因为是ASCII码一个字符一个字节),其占用内存大小:33+len(a)字节;而b的大小是不变的。
在此举例说以下为什么要memoryview:
a = bytearray(b'aaaaaa')
b = a[:2] # 会产生新的bytearray
b[:2] = b'bb' # 对b的改动不影响a
print(a,b)
a = memoryview(bytearray(b'aaaaaa'))
b = a[:2] # bu会产生新的bytearray
b[:2] = b'bb' # 对b的改动影响a
print(a.tobytes(),b.tobytes())
及减少了内存的占用
创建一个obj的memoryview,obj必须支持buffer protocol(内置类型里如bytes和bytearray,也可以是array.array)
memoryview有元素的概念,对于bytes和bytearray元素是字节,而如array.array可能有更大的元素。
len(view)相当于tolist(后面会介绍)的长度
支持slice和index
v = memoryview(b'abcefg')
v[1]
98
momeryview的方法
_ eq _(exporter)
A memoryview and a PEP 3118 exporter are equal if their shapes are equivalent and if all corresponding values are equal when the operands’ respective format codes are interpreted using struct syntax.
For the subset of struct format strings currently supported by tolist(), v and w are equal if v.tolist() == w.tolist():
>>> import array
>>> a = array.array('I', [1, 2, 3, 4, 5])
>>> b = array.array('d', [1.0, 2.0, 3.0, 4.0, 5.0])
>>> c = array.array('b', [5, 3, 1])
>>> x = memoryview(a)
>>> y = memoryview(b)
>>> x == a == y == b
True
>>> x.tolist() == a.tolist() == y.tolist() == b.tolist()
True
>>> z = y[::-2]
>>> z == c
True
>>> z.tolist() == c.tolist()
True
If either format string is not supported by the struct module, then the objects will always compare as unequal (even if the format strings and buffer contents are identical):
>>> from ctypes import BigEndianStructure, c_long
>>> class BEPoint(BigEndianStructure):
... _fields_ = [("x", c_long), ("y", c_long)]
...
>>> point = BEPoint(100, 200)
>>> a = memoryview(point)
>>> b = memoryview(point)
>>> a == point
False
>>> a == b
False
Note that, as with floating point numbers, v is w does not imply v == w for memoryview objects.
tobytes()
以bytestring的形式返回缓冲里的数据,a.tobytes相当于bytes(a).a是memoryview的对象
For non-contiguous arrays the result is equal to the flattened list representation with all elements converted to bytes. tobytes() supports all format strings, including those that are not in struct module syntax.
hex()
>>> m = memoryview(b"abc")
>>> m.hex()
'616263'
tolist()
以list形式返回缓冲里的data
>>> memoryview(b'abc').tolist()
[97, 98, 99]
>>> import array
>>> a = array.array('d', [1.1, 2.2, 3.3])
>>> m = memoryview(a)
>>> m.tolist()
[1.1, 2.2, 3.3]
release()
>>> m = memoryview(b'abc')
>>> m.release()
>>> m[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: operation forbidden on released memoryview object
context management protocol
>>> with memoryview(b'abc') as m:
... m[0]
...
97
>>> m[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: operation forbidden on released memoryview object‘’
cast(format[, shape])
把一个memoryview转成一个新的符合format(struck里的format)和shape指数据的维度的memoryview
import struct
buf = struct.pack("i"*12, *list(range(12)))
x = memoryview(buf)
y = x.cast('i', shape=[2,2,3])#format为i(整数,4字节;shape指数据维度如[[[0, 1, 2], [3, 4, 5]], [[6, 7, 8], [9, 10, 11]]])
print(y.tolist())
[[[0, 1, 2], [3, 4, 5]], [[6, 7, 8], [9, 10, 11]]]
y.ndim#数据维度三维
3
y.shape
(2, 2, 3)
下面是memoryview的属性值
obj
>>> b = bytearray(b'xyz')
>>> m = memoryview(b)
>>> m.obj is b
True
nbytes
nbytes = = product(shape) * itemsize = = len(m.tobytes()),表现数据要多少字节,不一定和len(m)相等。len是指有多少元素。
>>> import array
>>> a = array.array('i', [1,2,3,4,5])
>>> m = memoryview(a)
>>> len(m)
5
>>> m.nbytes
20
>>> y = m[::2]
>>> len(y)
3
>>> y.nbytes
12
>>> len(y.tobytes())
12
readonly
如bytes的memoryview对象就是true
而bytearray的false
format
format
格式
itemsize,元素的字节大小
>>> import array, struct
>>> m = memoryview(array.array('H', [32000, 32001, 32002]))
>>> m.itemsize
2
>>> m[0]
32000
>>> struct.calcsize('H') == m.itemsize
#format为i
#[[[0, 1, 2], [3, 4, 5]], [[6, 7, 8], [9, 10, 11]]]
#itemsize不是3*4,注意是[calsize](https://docs.python.org/3.6/library/struct.html)(i')
True
ndim
维度int
shape
每一个维度的长度
strides
suboffsets
memory是那种
c_contiguous
contiguous
Set Types — set, frozenset
set是一个内部元素都是hashable的无序集合。
如[1]不可hash所以下面报错
set([1,2,3,[1]])
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: unhashable type: 'list'
经常用来元素检查,删去重复项,进行集合的相关计算。
支持x in set ,for x in set,但是不支持index,slice绝其他序列方法
set可变集合,add(),remove(),,但也因为可变,不支持不可以作为dict的键值或者另一个 set的元素
而frozenset是不可变的,可哈希的。
type({})#dict
type({,})#类似tuple的操作,会报错
这两种是无法建立一个空set的。
class set([iterable])
class frozenset([iterable])
无参数,返回相应的空集
iterable如上所说,元素必须是hashable的,如果想表示set里包含一个set,后者必须是frozenset(可哈希的),从iterable中取不重复的元素
len(set) 集合长
x in s x属于s
x not in s x不属于s
isdisjiont(other),交集是否为空集
issubset(other),是否为子集
set <= other set是否被other包含
set >= other
set<other
set>other
*union(others),
set|other|…
返回一个set,包含others的所有元素,所有集合的并集
intersection(*others)
set & other & …
所有的交集
*difference(others)
set - other - …
返回一个集合元素,我有你没有的
symmetric_difference(other)
set ^ other#这种是操作符
返回一个集合,并集后删去交集的部分
copy(),返回一个新的浅复制集合
注意,以上有些方法,有两种形式及函数和操作符形式如
symmetric_difference(other)¶
set ^ other#这种是操作符
前一种可以接受任意iterable对象,而操作符两边的操作数必须为集合
这种规定排除了,构建set的容易犯的错误如set(‘abc’) & ‘cbs’
==set和frozenset都支持集合之间的比较,
集合相等,set()frozenset(),交集,并集相等
其他的上面有<,>,<=,>=,
Binary operations中提到的(contiguous buffer;包含了bytes,bytearray,memoryview,array.array)对象中都可以操作,而返回的对象和计算数的顺序有关),同样适用于set和frozenset。
type(frozenset([1,2])|set([2,3]))
<class 'frozenset'>
接下里提到的方法是适用于set,不适用于frozenset
*update(others)
set |= other | …
Update the set, adding elements from all others.
*intersection_update(others)
set &= other & …
Update the set, keeping only elements found in it and all others.
*difference_update(others)
set -= other | …
Update the set, removing elements found in others.
symmetric_difference_update(other)
set ^= other
Update the set, keeping only elements found in either set, but not in both.
add(elem)
Add element elem to the set.
remove(elem)
Remove element elem from the set. Raises KeyError if elem is not contained in the set.
discard(elem)
Remove element elem from the set if it is present.
pop()
Remove and return an arbitrary element from the set. Raises KeyError if the set is empty.
clear()
Remove all elements from the set.
Note, the non-operator versions of the update(), intersection_update(), difference_update(), and symmetric_difference_update() methods will accept any iterable as an argument.
Note, the elem argument to the contains(), remove(), and discard() methods may be a set. To support searching for an equivalent frozenset, a temporary one is created from elem.
Mapping Types — dict
字典在可在可哈希值(键值)和任意对象之间建立映射。dict是唯一一个标准的映射类型,
数值类型做键值,遵循数值类型比较的原则,即1==1.0.在这里不推荐用float类型作为键值
dic = {1:2,1.0:3}
list(dic.keys())#[1]
字面值{1:2,2:3},即{key1:vlaue1,key2:value2},键值id不可以重复,value可以。
dict的构造函数:
class dict(**kwarg)
class dict(mapping, **kwarg)
class dict(iterable, **kwarg)
dict({1:2})
{1: 2}
dict()
{}
dict([(1,2),(2,3)])#只要参数是iterable,而且每一个元素是二元iterable就可以
{1: 2, 2: 3}
dict([(1,2),[1,3]])#第一个元素作为键值,可以重复,重复的value按最后一个。
{1: 3}
dict(one=1, two=2, three=3)
{'one': 1, 'two': 2, 'three': 3}
第三种经常和zip搭配使用。参考内建函数built-in zip
a = ['a','b'];fruit = ['apple','banana']
c = zip(a,fruit)
dict(c)
{'a': 'apple', 'b': 'banana'}
逆运算
p.keys()
dict_keys(['a', 'b'])
p.values()
dict_values(['apple', 'banana'])
以下是dict的方法,普通的映射类型也支持
len(d)
返回int代表长度
d[key]
返回键值为key的value
d[key] = value
设置dict键key对应的值为value
del d[key]
键值为key的键值对
del a[1]
a
{}
key in d
Return True if d has a key key, else False.
key not in d == not key ind
Equivalent to not key in d.
iter(d)
Return an iterator over the keys of the dictionary. This is a shortcut for iter(d.keys()).
clear()
Remove all items from the dictionary.
copy()
Return a shallow copy of the dictionary.
classmethod fromkeys(seq[, value])
建立一个和seq的键一样,值设为value的dict
fromkeys() is a class method that returns a new dictionary. value defaults to None.
get(key[, default])
default默认为None,从dict获取键为key的值,没有则返回deflaut。不会引起keyerror,所以当不确定的时候不要使用dict[key]
items()
Return a new view of the dictionary’s items ((key, value) pairs). See the documentation of view objects.
keys()
Return a new view of the dictionary’s keys. See the documentation of view objects.
values()
Return a new view of the dictionary’s values. See the documentation of view objects.
b = {1: 2, 2: 3, 5: 6, 7: 8}
b.items()
dict_items([(1, 2), (2, 3), (5, 6), (7, 8)])
b.keys()
dict_keys([1, 2, 5, 7])
b.values()
dict_values([2, 3, 6, 8])
pop(key[, default])
If key is in the dictionary, remove it and return its value, else return default. If default is not given and key is not in the dictionary, a KeyError is raised.
popitem()
Remove and return an arbitrary (key, value) pair from the dictionary.
popitem() is useful to destructively iterate over a dictionary, as often used in set algorithms. If the dictionary is empty, calling popitem() raises a KeyError.
setdefault(key[, default])
如果键存在则返回值,键不存在则插入键值,返回default
If key is in the dictionary, return its value. If not, insert key with a value of default and return default. default defaults to None.
update([other])
把没有的键,添加键值对;都存在的键则按照other的值重写,. Return None.
a = {1:2,2:3};b= {1:"b"}
b.update(a)
b
{1: 2, 2: 3}
update可以接受dict,[[1,2],[3,6]],或者q=1,w=2.
字典= =,所有键值对相等;但<>之类的会引起typeerror。
Dictionary view objects
dict.keys(), dict.values() and dict.items() 返回的是viewobject,他提供字典条目的实时view。
字典view可以迭代,也支持成员测试(a in b)
len(dictview)
Return the number of entries in the dictionary.
iter(dictview)
Return an iterator over the keys, values or items (represented as tuples of (key, value)) in the dictionary.
x in dictview
Return True if x is in the underlying dictionary’s keys, values or items (in the latter case, x should be a (key, value) tuple).
接着介绍一下,set-like view,如果以上三个方法返回的键或者值或者键值对是不重复且可哈希的,则他们也支持 abstract base class collections.abc.Set 定义的方法。
>>> dishes = {'eggs': 2, 'sausage': 1, 'bacon': 1, 'spam': 500}
>>> keys = dishes.keys()
>>> values = dishes.values()
>>> # iteration
>>> n = 0
>>> for val in values:
... n += val
>>> print(n)
504
>>> # keys and values are iterated over in the same order
>>> list(keys)
['eggs', 'bacon', 'sausage', 'spam']
>>> list(values)
[2, 1, 1, 500]
>>> # view objects are dynamic and reflect dict changes
>>> del dishes['eggs']
>>> del dishes['sausage']
>>> list(keys)
['spam', 'bacon']
>>> # set operations
>>> keys & {'eggs', 'bacon', 'salad'}
{'bacon'}
>>> keys ^ {'sausage', 'juice'}
{'juice', 'sausage', 'bacon', 'spam'}
Context Manager Types
定义了进入要执行有关操作,退出要执行有关操作。
第一种语法表示中with语句的执行流程:
1,计算上下文表达式 (with_item 中给出的表达式) ,获得一个上下文管理器,该上下文管理器包括__enter__() 和 exit()方法;
2,加载该上下文管理器的 exit() 方法留待以后使用;
3,调用上下文管理器的 enter() 方法;,
4,如果 with 语句中的 with_item 指定了目标别名(as 分句后面的变量名),enter() 的返回值被赋给这个目标别名;
*注
with 语句确保只要 enter() 正常返回,那么 exit()一定会被调用。因此如果在将值赋给目标别名时发生错误,该错误将被当做发生在suite中。可以看下面的第6步。
5. with语句中嵌套的 suite 部分被执行(第二种表示中的 with-block 部分);
6. 上下文管理器的 exit() 方法被调用,如果是异常造成 suite(with-block) 部分退出,异常的类型、值和回溯都被当做参数传给 exit(type, value, traceback) 方法,这三个值和sys.exc_info的返回值相同。如果suite(with-block) 部分没有抛出异常,exit()的三个参数都是 None。
如果 suite 部分是由于异常导致的退出,且__exit__()方法的返回值是false,异常将被重举;如果返回值是真,异常将被终止,with 语句后的代码继续执行。
如果 suite 部分是由于不是异常的其他原因导致的退出,exit()方法的返回值被忽视,执行在退出发生的地方继续。
contextmanager.enter()
进入运行时上下文,要么返回该对象,要么返回一个与运行时上下文相关的对象,如果有 as 分句的话,with 语句将会把该方法的返回值和 as 分句指定的目标(别名)进行绑定。
比如文件对象在__enter__()里返回自己,这样 open() 函数可以被当做环境表达式在一个 with 语句中使用。
另一种情形中,decimal.localcontext()返回一个相关的对象。上下文管理器将活跃的小数上下文设置为初始小数上下文的拷贝,然后返回拷贝后的引用。这样可以在 with 语句中修改当前的小数上下文而不影响with 语句外的代码。
contextmanager.exit(exc_type, exc_val, exc_tb)
退出运行时上下文,参数是 with 代码块中抛出的异常的详细信息,返回一个Bool型的标识符,该标识符说明上下文管理器能否处理异常:如果上下文管理器可以处理这个异常,exit() 应当返回一个true值来指示不需要传播这个异常;如果返回false,就会导致__exit__() 返回后重新抛出这个异常,如果上下文不是因为异常而退出,则三个参数都是 None。
该方法如果返回True ,说明上下文管理器可以处理异常,使得 with 语句终止异常传播,然后直接执行 with 语句后的语句;否则异常会在该方法调用结束后正常传播,该方法执行时发生的异常会替代所有其他在执行 with 代码块时出现的异常。
在__exit__()中不需要显式重举传入的异常,只需要返回 false 表明 exit() 正常执行且传入的异常需要重举即可,重举传入__exit__()方法的异常是调用__exit__()的函数的工作。这种机制便于上下文管理器检测 exit() 方法是否真的执行失败。
Python定义了若干上下文管理器,Python的 generator 类型和装饰器 contextlib.contextmanager 提供了实现上下文管理器协议的手段,如果一个生成器函数被装饰器 contextlib.contextmanager 所装饰,它将会返回一个实现了必要的 enter() 和 exit() 方法的上下文管理器,而不是普通的迭代器!
class TraceBlock(object):
def message(self, arg):
print('running' + arg)
def __enter__(self):
print('starting with block')
return self
def __exit__(self, exc_type, exc_value, exc_tb):#出现异常的类型,值和追溯会传递给这个函数
if exc_type is None:
print('exited normally\n')
else:
print('raise an exception! ' + str(exc_type))
return False #Propagate
if __name__ == '__main__':
with TraceBlock() as action:
action.message('test1')
print('reached')
with TraceBlock() as action:
action.message('test2')
raise TypeError
print ('not reached')
如果__exit__返回的是Ture,则会不理会错误继续执行
class TraceBlock(object):
def message(self, arg):
print('running' + arg)
def __enter__(self):
print('starting with block')
return self
def __exit__(self, exc_type, exc_value, exc_tb):
if exc_type is None:
print('exited normally\n')
else:
print('raise an exception! ' + str(exc_type))
return True # Propagate
if __name__ == '__main__':
with TraceBlock() as action:
action.message('test2')
raise TypeError
print('not reached')
多个上下文管理器
with open('data') as fin, open(''res', 'w') as fout:
for line in fin:
if 'some key' in line:
fout.write(line)
Other Built-in Types
modules模块
module唯一特别的操作就是获得特性的方式,m.name(m是module,name是symbal table中定义的属性名)
模块的属性是可以分配的(注意import语句,严格的说不是模块的操作;imoprt foo不需要一个模块对象叫做foo,这个foo实在外面定义的)
模块的一个属性_ dict _,是一个symbol table的字典,调整这个之三,会改变模块的symbol table
m.__dict__['a'] = 1#可以
m.__dict__ = {}#不可以
模块建立到解释器里被写作<module ‘sys’ (built-in)>,如果是从文件里加载则
<module ‘os’ from ‘/usr/local/lib/pythonX.Y/os.pyc’>
类和实例
function
唯一的操作就是call 他,即fun(argu)
方法
方法是一种用用属性符号(.)加方法来调用的function。
There are two flavors: built-in methods (such as append() on lists) and class instance methods. Built-in methods are described with the types that support them.
If you access a method (a function defined in a class namespace) through an instance, you get a special object: a bound method (also called instance method) object. When called, it will add the self argument to the argument list. Bound methods have two special read-only attributes: m.self is the object on which the method operates, and m.func is the function implementing the method.
Calling m(arg-1, arg-2, …, arg-n) is completely equivalent to calling m.func(m.self, arg-1, arg-2, …, arg-n).
调用m(arg1…)和m._ func (m. self _,arg1)完全一样。
和function一样bound methed(如果你通过实例调用命名空间里的一个方法,那就是bound methed),支持获取任意属性,然而既然方法属性存在underlying函数met.__ func _里,在bound方法里设置方法属性是不可以的,会引起attributeerror如下
>>> class C:
… def method(self):
… pass
…
>>> c = C()
>>> c.method.whoami = ‘my name is method’ # can’t set on the method
Traceback (most recent call last):
File “”, line 1, in
AttributeError: ‘method’ object has no attribute ‘whoami’
>>> c.method.func.whoami = ‘my name is method’
>>> c.method.whoami
‘my name is method’
Code Objects
Type Objects
type()内置函数没有额外操作
The Null Object
无额外操作
The Ellipsis Object
经常在是slicing里使用,无额外操作
The NotImplemented Object
Boolean Values
Internal Objects
Special Attributes
以下属性只读,部分不会被内置函数dir(),爆出。
object.dict¶
字典或者是映射类型,用来储存一个对象可写的性质
instance.class
实例所属的类
class.bases
返回一个包含一个类对象的基类元组tuple
definition.name
The name of the class, function, method, descriptor, or generator instance.
definition.qualname
The qualified name of the class, function, method, descriptor, or generator instance.
New in version 3.3.
class.mro
This attribute is a tuple of classes that are considered when looking for base classes during method resolution.
class.mro()
This method can be overridden by a metaclass to customize the method resolution order for its instances. It is called at class instantiation, and its result is stored in mro.
class.subclasses()
Each class keeps a list of weak references to its immediate subclasses. This method returns a list of all those references still alive. 返回自类序列。
问题
1,证明memoryview的好处
2,那些可以hashable
3.sys.getsizeof(ob),ob是不同类的对象。这个大小为什么不变56
实参和形参的单星号和双星号 ↩︎
ASCII
ASCII(American Standard Code for Information Interchange,美国信息互换标准代码,ASCⅡ)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
ASCII第一次以规范标准的型态发表是在1967年,最后一次更新则是在1986年,至今为止共定义了128个字符,其中33个字符无法显示(这是以现今操作系统为依归,但在DOS模式下可显示出一些诸如笑脸、扑克牌花式等8-bit符号),且这33个字符多数都已是陈废的控制字符,控制字符的用途主要是用来操控已经处理过的文字,在33个字符之外的是95个可显示的字符,包含用键盘敲下空白键所产生的空白字符也算1个可显示字符(显示为空白)。 ↩︎

















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









