







布隆过滤
基本原理:当一个元素被加入集合时,通过k个散列函数将这个元素映射到一个位数组中的k个点,把他们置为1。检索时,我们只需要看这些点是不是都是1,就(大约)直到集合中有没有他了:如果这些点中有任何一个点为0,则被检索元素一定不存在;如果都是1,则该元素很可能存在。
原理图:
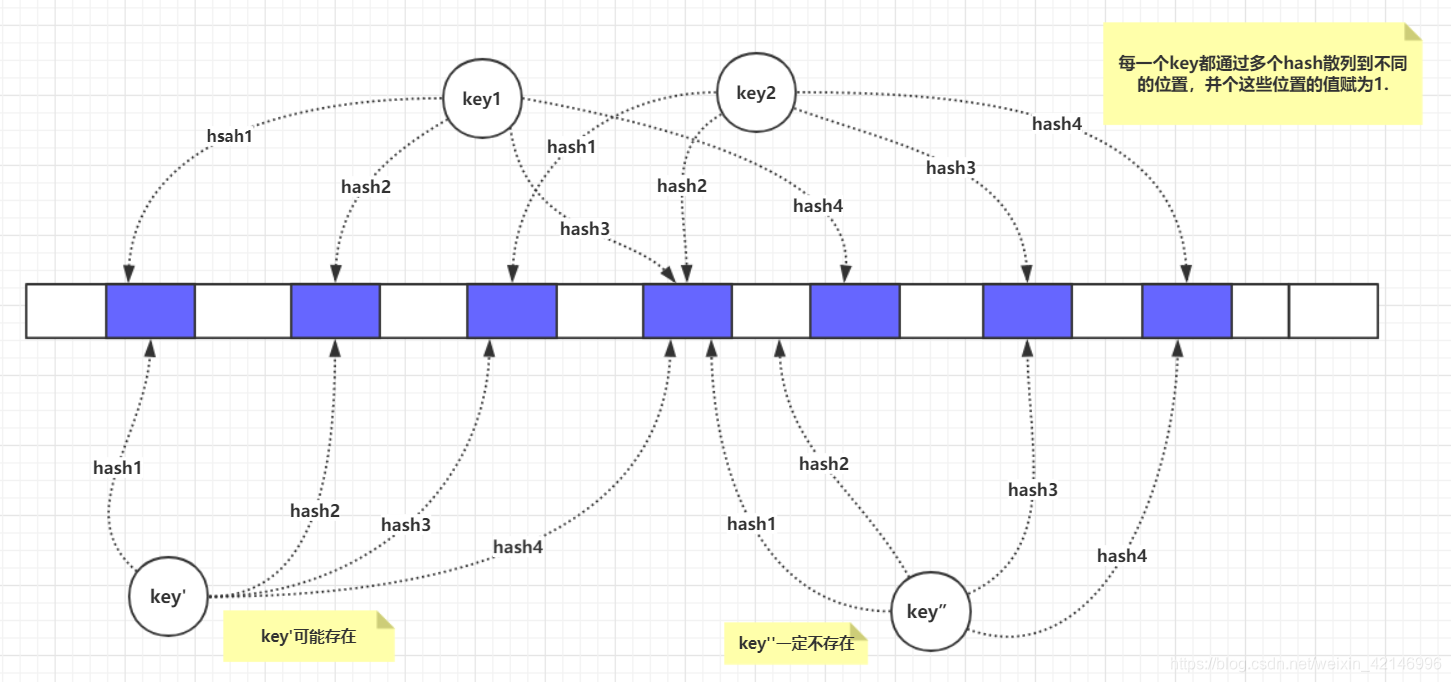
分析:
不用保存原始数据,只需要保存原始数据的位图,位图占据的空间很小。只需要经过k次hash进行比对即,效率高。但是会不准确,造成一定的误差
模拟代码如下:
import java.math.BigInteger;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.ArrayList;
import java.util.List;
import java.util.logging.Level;
import java.util.logging.Logger;
public class BoolmFilter {
public static final int NUM_SLOTS=1024*1024*8; //位图的长度
public static final int NUM_HASH=8; //hash函数的个数 每一个hash函数结果用于标记一个位
private BigInteger bitMap=new BigInteger("0"); //位图
public static void main(String[] args) {
BoolmFilter bf=new BoolmFilter();
List<String> list=new ArrayList<String>();
list.add("eyufgvdvc");
list.add("eyufgvdvc1");
list.add("eyufgvdvc2 1887129 5611 石市豪 湖北孝感");
list.add("15827598337 湖北武汉 波波");
list.add("15623533404 17671645348 子良");
list.add("18208281973 四川宜宾 福风 ");
for (int i = 0; i <list.size() ; i++) {
bf.addElement(list.get(i));
}
System.out.println(bf.checkElement("eyufgvdvc"));
System.out.println(bf.checkElement("eyufgvdvc1"));
System.out.println(bf.checkElement("eyufgvdvc2"));
System.out.println(bf.checkElement("eyufgvdv"));
System.out.println(bf.checkElement("eyufgvd"));
System.out.println(bf.checkElement("eyufgvdvcc"));
}
//模拟的hash算法
public int hash(String message,int n){
message=message+String.valueOf(n);
try {
MessageDigest md5=MessageDigest.getInstance("md5"); //MD5是将任意输入映射成128位整数的hash函数
byte[] bytes=message.getBytes(); //字符串转化成字节数组
md5.update(bytes);
byte[] digest = md5.digest(); //128位 16个字节的数组
BigInteger bigInteger=new BigInteger(digest); //至此 获取到了message的128位整数
return Math.abs(bigInteger.intValue())%NUM_SLOTS; //128位整数可能超出位图的大小 所以进行了取余操作
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
Logger.getLogger(BoolmFilter.class.getName()).log(Level.SEVERE,null,e);
}
return -1;
}
//处理原始数据:每hash(message)一次---->就标注一个位;操作k次
//hash的值域位:0~NUM_SLOTS-1
public void addElement(String meaasge){
for (int i = 0; i <NUM_HASH ; i++) {
int hashCode=hash(meaasge,i); //进行k次hash操作 根据参数的不同 此处模拟了8个不同的hash函数
if(!bitMap.testBit(hashCode)){ //如果该位置还不为1
bitMap=bitMap.or(new BigInteger("1").shiftLeft(hashCode)); //用于标注位图的该位值为: 1
}
}
}
//判断某一个元素是否存在
public boolean checkElement(String message){
for (int i = 0; i <NUM_HASH ; i++) {
int hashCode=hash(message,i); //hashCode代表一个位置
if(!bitMap.testBit(hashCode)){ //如果在位图的该位置为0
return false;
}
}
return true; //不精确,有可能误判
}
}


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









