







本章我们要实现断点续传功能。断点续传功能分两部分,分别是断点下载和断点上传。
为什么对象存储需要支持断点续传
在实验室的理想环境里网络永远通畅,对象存储系统并不需要断点续传这个功能。但在现实世界,对象存储服务在数据中心运行,而客户端在客户本地机器上运行,它们之间通过互联网连接。互联网的连接速度慢且不稳定,有可能由于网络故障导致断开连接。 在客户端上传或下载一个大对象时,因网络断开导致上传下载失败的概率就会变得不可忽视。为了解决这个问题,对象存储服务必须提供断点续传功能,允许客户端从某个检查点而不是从头开始上传或下载对象。
断点下载流程
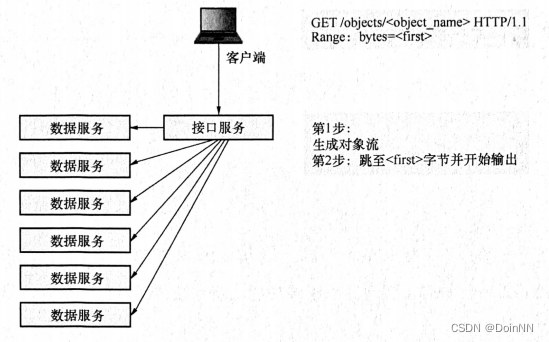
断点下载的实现非常简单,客户端在GET对象请求时通过设置 Range头部来告诉接口服务需要从什么位置开始输出对象的数据。
接口服务的处理流程在生成对象流之前和上一章没有任何区别,但是在成功打开了对象数据流之后,接口服务会额外调用 rs.RSGetStream.Seek 方法跳至客户端请求的位置,然后才开始输出数据。
断点上传流程
断点上传的流程则要比断点下载复杂得多,这是由 HTTP 服务的特性导致的。客户端在下载时并不在乎数据的完整性,一旦发生网络故障,数据下到哪算哪,下次继续从最后下载的数据位置开始续传就可以了。
但是对于上传来说,接口服务会对数据进行散列值校验,当发生网络故障时,如果上传的数据跟期望的不一致,那么整个上传的数据都会被丢弃。
所以断点上传在一开始就需要客户端和接口服务做好约定,使用特定的接口进行上传,客户端在知道自己要上传大对象时就主动改用对象POST接口提供对象的散列值和大小。
接口服务的处理流程和上一章处理对象 PUT 一样,搜索6个数据服务并分别 POST临时对象接口。数据服务的地址以及返回的 uuid 会被记录在一个 token 里返回给客户端。
客户端POST对象后会得到一个 token。对 token 进行PUT可以上传数据。在上传时客户端需要指定range 头部来告诉接口服务上传数据的范围。接口服务对 token进行解码,获取6个分片所在的数据服务地址以及 uuid,分别调用 PATCH 将数据写入6个临时对象。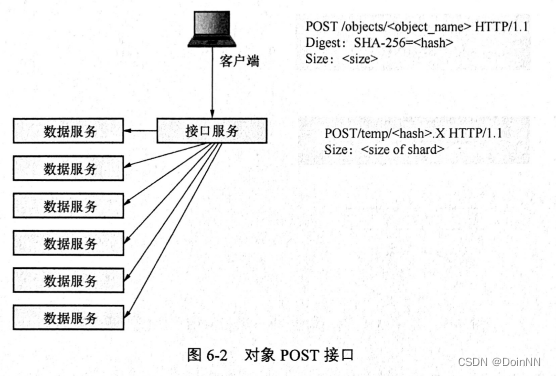
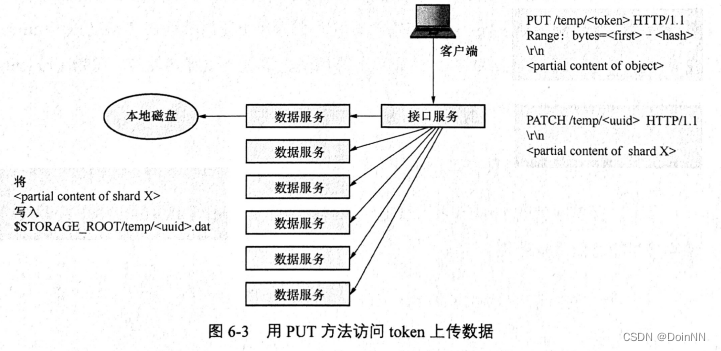
通过 PUT上传的数据并不一定会被接服务完全接收。我们在第5章已经知道经过 RS分片的数据是以块的形式分批写入 4 个数据片的,每个数据片一次写入 8000字节,4 个数据片一共写入 32 000 字节。所以除非是最后一批数据,否则接口服务只接收 32 000 字节的整数倍进行写入。这是一个服务端的行为逻辑,我们不能要求客户端知道接口服务背后的逻辑,所以接口服务必须提供 token 的 HEAD 操作,让客户端知道服务端上该 token目前的写入进度。

接口服务的REST接口
接口服务的 objects 接口 GET 方法新增了 Range 请求头部,用于告诉接口服务需要的对象数据范围。
GET /objects/<object name>
请求头部
Range: bytes=<first>-
响应头部
Content-Range: bytes <first>-<size>/<size>
响应正文
first开始的对象内容
Range 请求头部定义在RFC7233 中,是HTTP/1.1协议的一部分。给GET 请求加上Range 头部意味着这个请求期望的只是全体数据的一个或多个子集。Range 请求主要支持以字节为单位的 byte Range 。byte range的格式是固定字符串“bytes=”开头,后面跟上一个或多个数字的范围,由逗号分隔。假设我们的整体数据是 10000 字节,那么合法的byte range格式可以有以下几个例子:
- 请求最后500个字节(9500~9999): bytes–500 或 bytes-9500
- 请求第一个和最后一个字节(字节 0和9999):bytes=0-0,-1
其他几个合法但不常见的请求第 500~999 个字节的格式。
- bytes=500-600,601-999
- bytes=500-700,601-999
我们的对象存储系统实现的格式是bytes=<first>-。客户端通过指定first的值告诉接口服务下载对象的数据范围,接口服务返回的数据从 first 开始,first 之前的对象数据会在服务端被丢弃。根据 Range 请求的协议规范,接口服务需要返回 HTTP 错误代码206 Partial Content,并设置 Content-Range 响应头部告知返回数据的范围<first>-<size>/<size>,其中<firs>是客户端要求的起始位置,<size>是对象的大小。
objects 接口还新增了POST方法,用于创建 token。
POST /objects/<object name>
请求头部
Digest: SHA-256=<对象散列值的 Base64 编码>
Size:<对象内容的长度>
响应头部
Location:<访问/temp/token的 URI>
token 被放在Location 头部返回给客户端,客户端拿到后可以直接访问该URI。
除了 objects 接口发生的改变以外,接口服务还新增temp 接口。
HEAD /temp/<token>
响应头部
Content-Length:<token当前的上传字节数>
PUT /temp/<token>
请求头部
Range: bytes=<first>-<last>
请求正文
对象的内容,字节范围为 first~last
客户端通过 Range头部指定上传的范围,first必须跟tken 当前的上传字节数一致否则接口服务会返回416 Range Not Satisfiable。如果上传的是最后一段数据,<last>为空
数据服务的REST接口
数据服务的 temp 接口新增了 HEAD 和GET两个方,HEAD 方法用于取某个分片临时对象当前的大小;而 GET 方法则用于获取临时对象的数据。
HEAD /temp/<uuid>
响应头部
Content-Length:<临时对象当前的上传字节数>
GET /temp/<uuid>
响应正文
临时对象的内容
客户端将对象所有的数据上传完毕之后,接口服务需要调用这个方法从数据服务读取各分片临时对象的内容并进行数据校验,只有在验证了对象的散列值符合预期的情况下,服务端才认为该对象的上传是成功的,进而将临时对象转正。
小结
本章实现了对象数据的断点续传。断点下载通过 Range 请求头部实现,客户端可以在调用对象的GET 接口时,通过 Range 头部告知服务端下载数据的偏移量,接口服务将该偏移量之前的对象数据流丢弃并将剩下的部分返回给客户端。
断点上传则比较复杂,由于 HTTP 服务的特点,需要使用新的对象 POST 接创建一个token,并通过接口服务的temp 接口访问token 上传数据。客户端需要根据上传对象的大小自行选择上传的方式:对于小对象,客户端可以使用之前的 PUT 方法上传对于大对象,客户端需要选择POST方法并自行分块上传。
除非正好将对象完整上传,否则接口服务每次只接受 32 000字节的整数倍,不足的部分将被丢弃。如果客户端的分块小于 32 000字节,那么上传的数据就会被全部丢弃。客户端需要在PUT每一块之前调用HEAD检查该 token 当前的进度,并选择合适的偏移量和分块大小。














 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









