






一、参考资料
二、总体框架
Java集合是java提供的工具包,包含了常用的数据结构:集合、链表、队列、栈、数组、映射等。Java集合工具包位置是java.util.*
Java集合主要可以划分为4个部分:List列表、Set集合、Map映射、工具类(Iterator迭代器、Enumeration枚举类、Arrays和Collections)、。
Java集合工具包框架图(如下):
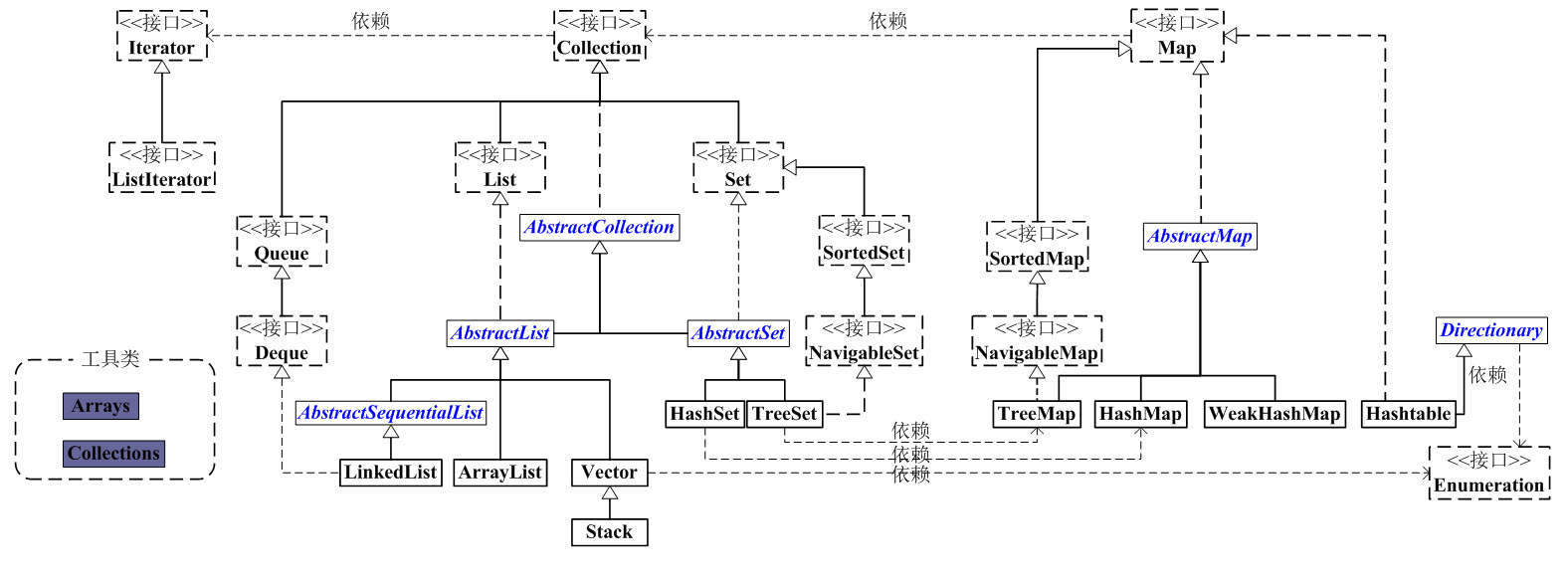
数组([])——数组操作工具类Arrays
列表Collection(有序集合List、无序集合Set、映射Map)——列表操作工具类Collections
遍历方法:
Iterator迭代器:Collection接口的方法,因此各子类均有。
Enumeration枚举:线程安全者HashTable、Vector。
for-each遍历:List的实现类。有两种遍历方式:for(int i=0;i
Map和Set的对应:
HashMap——HashSet
LinkedHashMap——LinkedHashSet(内部按插入顺序组织,因此遍历得到的就是插入顺序的序列)。LiskedHashMap是HashMap的子类,支持按插入顺序遍历、按访问顺序遍历。
TreeMap——TreeSet(按key排序,因此遍历得到按key有序序列。可提供比较器)
看上面的框架图,先抓住它的主干,即Collection和Map。
1、Collection
Collection是一个接口,是高度抽象出来的集合,它包含了集合的基本操作和属性。
Collection包含了List和Set两大分支。
1.1、List
(1)List概括
List是一个有序的队列,每一个元素都有它的索引,第一个元素的索引值是0。List 是一个接口,它继承于Collection的接口。
AbstractList 是一个抽象类,它继承于AbstractCollection。AbstractList实现List接口中除size()、get(int location)之外的函数。
AbstractSequentialList 是一个抽象类,它继承于AbstractList。AbstractSequentialList 实现了“链表中,根据index索引值操作链表的全部函数”。
ArrayList, LinkedList, Vector, Stack是List的4个实现类。
ArrayList 是一个数组队列,相当于动态数组。它由数组实现,随机访问效率高,随机插入、随机删除效率低。(默认初始容量10,扩容时增加已有元素量的一半)
LinkedList 是一个循环双向链表。它也可以被当作堆栈、队列或双端队列进行操作。LinkedList随机访问效率低,但随机插入、随机删除效率高。
Vector 是矢量队列,和ArrayList一样,它也是一个动态数组,由数组实现。但是ArrayList是非线程安全的,而Vector是线程安全的。
Stack 是栈,它继承于Vector。它的特性是:先进后出(FILO, First In Last Out)。
(2)List使用场景
如果涉及到“栈”、“队列”、“链表”等操作,应该考虑用List,具体的选择哪个List,根据下面的标准来取舍。
对于需要快速插入,删除元素,应该使用LinkedList。
对于需要快速随机访问元素,应该使用ArrayList。
对于“单线程环境” 或者 “多线程环境,但List仅仅只会被单个线程操作”,此时应该使用非同步的类(如ArrayList)。对于“多线程环境,且List可能同时被多个线程操作”,此时,应该使用同步的类(如Vector)。
1.2、Set
Set是一个不允许有重复元素的集合,它通过Map来实现。
Set的实现类有HashSet和TreeSet。
(1)HashSet
HashSet依赖于HashMap,它实际上是通过HashMap实现的,因此非同步、允许有null、无序。
(1)TreeSet
TreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。因此非同步、允许有null、有序。
2、Map
Map是一个映射接口,即key-value键值对。Map中的每一个元素包含“一个key”和“key对应的value”。
SortedMap 有序的“键值对”映射接口。
NavigableMap 是继承于SortedMap的,支持导航函数的接口。
AbstractMap是个抽象类,它实现了Map接口中的大部分API,减少了“Map的实现类”的重复编码。HashMap,TreeMap,WeakHashMap都是继承于AbstractMap。
Dictionary是一个抽象类,它直接继承于Object类,没有实现任何接口。
HashMap, Hashtable, TreeMap, WeakHashMap这4个类是“键值对”映射的实现类。它们各有区别!
非同步、线程不安全;键、值可为null;只支持Iterator(迭代器)遍历
注:
HashMap初始容量(16,就算用户给了个参数也会被改为不小于该参数值的最小2的次幂)及扩容(加倍)为什么采用2的次幂?扩容后进行重hash更快、元素分布更均匀(重hash时元素要么在原位要么移动原容量位数)。具体参阅:http://yikun.github.io/2015/04/01/Java-HashMap%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E5%8F%8A%E5%AE%9E%E7%8E%B0/
直接取h=hashCode(key)来获取bucket位置吗?否,因为对2n求模相当于取低n-1位,很容易碰撞,故进一步将h高16位与低16位异或结果h ^ (h>>>4)作为bucket位置。
JDK8开始,当一个桶里的单向链表的Entry数达TREEIFY_THRESHOLD(默认8)且capacity大于MIN_TREEIFY_CAPACITY(默认64)时再往该桶添加Entry前会转为红黑树,少于6时红黑树转为单向链表
LinkedHashMap,是HashMap的子类,不同在于内部加了双向链表来关联entry,这样就支持按插入顺序遍历,还支持按访问顺序遍历(即最近访问的在遍历时会最新被遍历到,相当于优先队列)。
同步、线程安全的;键、值不可为null;支持Iterator(迭代器)和Enumeration(枚举器)两种方式遍历。Collections.synchronizedMap(Map m)会返回一个线程安全的Map,其原理是在每个方法调用前通过synchronized(mutex)加锁,所以相当于HashTable;更甚的是,即使传入的Map是线程安全的如HashTable,也还是会这样操作,显然效率会很低。
LinkedHashMap是HashMap的子类,与HashMap不同的是其额外维护了一条贯穿全部Entry的双向链表,以保证读出的Entry的顺序与插入的顺序一致。
注意Map中用自定义类做key时,须重写其hashCode和equals方法,以保证:两对象相同(即equals成立)则两对象的hashCode相等(反之则不一定成立),即hashCode相等是equals成立的必要非充分条件。
接下来,再看Iterator。它是遍历集合的工具,即我们通常通过Iterator迭代器来遍历集合。我们说Collection依赖于Iterator,是因为Collection的实现类都要实现iterator()函数,返回一个Iterator对象。
ListIterator是专门为遍历List而存在的。
再看Enumeration,它是JDK 1.0引入的抽象类。作用和Iterator一样,也是遍历集合;但是Enumeration的功能要比Iterator少。在上面的框图中,Enumeration只能在Hashtable, Vector, Stack中使用。
最后,看Arrays和Collections。它们是操作数组、集合的两个工具类。
三、更好的第三方库
HashMap 的实例有两个参数影响其性能:初始容量 和加载因子,其他类似。GNU Trove (http://trove4j.sourceforge.net/) 是一个Java 集合类库。在某些场景下,Trove集合类库提供了更好的性能,而且内存使用更少。















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









