







 点击关注上方“Java大厂面试官”,第一时间送达技术干货。阅读文本大概需要 8 分钟。前言前面已经讲了面试必问 Redis 数据结构底层原理String、List篇;链接如下:面试必问 Redis 数据结构底层原理String、List篇redis版本:6.0.6Hash 字典是什么听名称就知道很像Java中的HashMap,原理也有很多相似之处,但是Reids做了很多优化,Redis的...
点击关注上方“Java大厂面试官”,第一时间送达技术干货。阅读文本大概需要 8 分钟。前言前面已经讲了面试必问 Redis 数据结构底层原理String、List篇;链接如下:面试必问 Redis 数据结构底层原理String、List篇redis版本:6.0.6Hash 字典是什么听名称就知道很像Java中的HashMap,原理也有很多相似之处,但是Reids做了很多优化,Redis的...
点击关注上方“Java大厂面试官”,第一时间送达技术干货。
阅读文本大概需要 8 分钟。
前言
前面已经讲了面试必问 Redis 数据结构底层原理String、List篇;
链接如下:
面试必问 Redis 数据结构底层原理String、List篇
redis版本:6.0.6
Hash 字典
是什么
听名称就知道很像Java中的HashMap,原理也有很多相似之处,但是Reids做了很多优化,Redis的hash的底层存储有两种数据编码,一种是ziplist,另外一种是hashtable,ziplist之前已经讲过了。
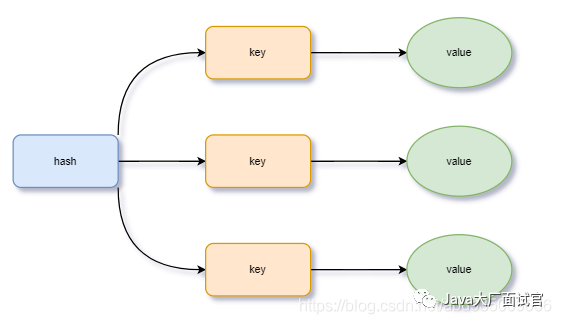
我们来用redis自带的debug命令来看下hash类型的encoding编码字段:
ziplist
> hset key4 name Nick
1
> debug object key4
Value at:0x7f21f2eadde0 refcount:1 encoding:ziplist serializedlength:24 lru:13214504 lru_seconds_idle:21
hashtable
> hset key5 name 01234567890123456789012345678901234567890123456789012345678901234
1
> debug object key5
Value at:0x7f21f2eade00 refcount:1 encoding:hashtable serializedlength:28 lru:13214661 lru_seconds_idle:3
hash类型,会优先使用ziplist编码,当下面任一条件被破坏了才会采用hashtable编码:
- hash对象保存的键和值字符串长度都小于
64字节 - hash对象保存的键值对数量小于
512ziplist
这两个条件是可以修改的,在redis.conf中
hash-max-ziplist-value 64 #字符串长度都小于64字节
hash-max-ziplist-entries 512 #元素数量小于512
为什么
为什么要优先使用ziplist压缩列表?
- 压缩列表是非常紧凑的数据结构,占用的内存已经压缩的非常小了,可以提高内存的利用率。
- 压缩列表底层是连续的内存空间,对CPU高速缓存支持更友好,提高查询效率。
如何实现
下面来剖析hashtable原理;
是什么
其实就是上一篇中的dict,内部有2个hashtable,通车情况下只有一个hashtable是有值的,但是在字典扩容、缩容的时候,需要用的另一个hashtable过渡,进行渐进式搬迁,搬迁完成后,旧的hashtable删除,新的hashtable取而代之。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2841
2841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









