







《高级语言基本世界观——类型系统》源站链接,阅读体验更佳!
编写程序实际上就是在进行一个给定数据->进行处理->输出数据的过程,指令只是手段,数据才是我们的目的。**而高级语言中抽象出来的数据类型又直接决定了我们对数据的操作方式,其重要程度可见一斑。**我们在《高级语言中如何操作内存——变量和值》一文中讨论了高级语言使用左值定位数据存储区域,抽象出数据类型的概念限制读或者写的数据存储区域的大小以及对于数据存储区域中的值可以进行什么样的操作。
可以说,类型系统是一门语言的世界观的基本规则,只有理解了一门语言的类型系统,才能真正掌握这门语言的核心。
不同语言的类型规则可能天差地别,但是我们往往会从两个维度来描述一门语言类型系统的基本特征,分别是:
- 动/静
- 强/弱
同时,原子数据类型也是任何一门高级语言都会内建的基本特性,也是构成一门语言类型系统的基本特性。下面,我们就从这动/静和强/弱这两个维度来讨论一下高级语言类型系统的基本特性,同时简单说明一下原子数据类型在类型系统中的重要作用。
指令也是数据
我们在《指令也是数据?浅谈计算机体系结构》一文中曾经强调过一个概念——指令和数据是同构的,也就是说指令也是一种数据,把指令或者说行为当做数据其实是函数式编程范式的思维,这也是本人最喜欢的编程范式,因为这是一种抽象程度更高、能编写出更加通用的代码的编程范式。我在后面也会有一个专辑专门介绍函数式编程范式。
静态类型/动态类型
在进行这部门内容的讨论之前,我们需要先明确以下几个事实:
- 左值(变量)代表了一个数据存储区域,我们可以认为它是一个用来存储值的容器,之所以称其为变量是因为这个容器中的值是可以改变的。
- 一个值一定是一个常量,一个值是确定且唯一的。
- **数据类型是值的固有属性,一个值一定具有明确且唯一的类型。**高级语言抽象出数据类型的概念根本目的就是为存储值、读取值以及使用值提供元数据信息以及约束。
而静态类型/动态类型所描述的其实是左值是不是具有数据类型约束。换句话说,其描述的是变量(左值)是不是只能存储某种类型的值。
静态类型
如果左值只能存储某种类型的值,这个时候,这门语言就是静态类型的。
在静态类型的语言中,我们在声明一个变量的时候可能需要为这个变量指定数据类型,也有可能不需要指定,如果不需要指定那么编译器就会根据这个变量的初始化信息来推断出这个变量的类型,总之,在静态类型的语言中,一个变量只能存储某种类型的值,而不能随意使用。
静态类型的核心是变量只能存储某种类型的值,因此,一个变量在静态期必须具有一个明确且唯一的类型,而到了语言的运行时,变量中的值肯定是和我们声明变量时指定的数据类型是兼容的。
下面我们来理一下静态类型的特点:
- 某一个变量只能存储某种数据类型的值,一个变量在编译期必须具有一个明确且唯一的类型。
- 因为数据类型提供了值所占用内存大小的信息,因此对一些偏移量的解析在源代码编译的时候就可以完成。
静态类型检查
静态类型的语言都会有静态类型检查,在我们对左值进行LHS操作的时候,编译器会检查我们提供的源值的数据类型是不是和声明左值时指定的数据类型兼容,如果不兼容,语言就拒绝存储这个值,编译器就会报告错误。
然而,静态类型检查并不是静态类型语言的专利,**并不是具有静态类型检查能力的语言就是静态类型的,**某些动态类型语言也提供了静态类型检查的功能,比如TypeScript。
TypeScript是对JavaScript的扩展,具有明显的工具属性。而且在我所见的所有语言中,TypeScript的类型观是最为完整的——它甚至把每一个字面值都视为一个数据类型,只不过其值集就只有这个字面值本身一个单值。如下ts代码:
let value:String|1|true; value = 'abc' value = 1 value = true value = 3 //Error上面的ts代码中使用了联合类型,意思是value可以存储字符串类型的值,可以存储字面值1,也可以存储字面值true,至于到底存储的是什么类型的值,只有在运行时才能得知。
而我们在对value进行LHS赋值操作的时候,编译器会帮我们检查源值是不是落在了联合类型中各个类型值集的并集中,如果没有落在其中,那么类型检查失败,无法通过编译。
虽然ts具有静态类型检查的能力,但是其并不强制左值只能存储某种类型的值,比如上面的value,它在编译期的类型可能是String类型、Number类型(字面值1)或者是Boolean类型(字面值true),它在编译期并不具备唯一且确定的类型。也正是因为这一点,对所有偏移量的解析都只能放到运行时进行确定,其静态类型检查的目的也只是为了提高程序的健壮性,其本质上还是动态类型的。
动态类型
而如果一门语言是动态类型的,那么我们在声明一个左值的时候,就不用指定它的类型,它可以存储任意类型的值,具体的类型要到语言的运行阶段才能确认。
这在很大程度上提高了编码的灵活性,但是同时也意味着所有的类型检查工作都需要放在运行时进行,在一定程度上会损耗性能。而且,由于我们并不知道左值中存储的值的实际类型是什么,我们的代码中可能需要很多处理类型的代码,在动态类型的语言中通常称这样的代码为能力检测代码。
静态类型 VS 动态类型
上面我们已经介绍了静态类型语言和动态类型语言的本质区别:
- 静态类型的语言限制左值的数据类型,一个左值中所存储的值在编译阶段就可以确定
- 动态类型的语言不限制左值的数据类型,左值中存储的值的数据类型只有在代码运行的时候才能确定
我们来看一下下面的JavaScript代码和c++代码:
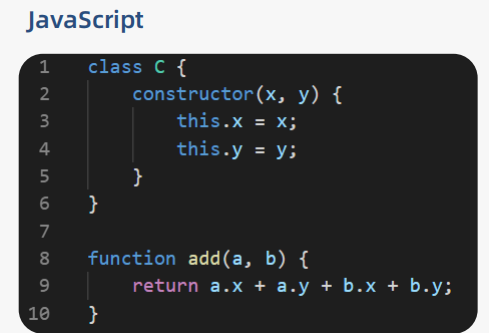
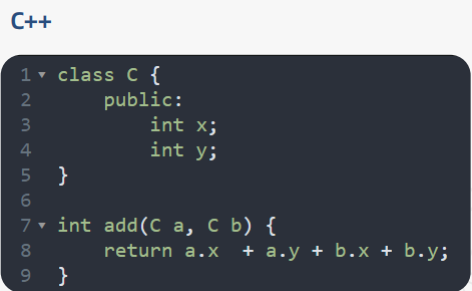
这两段代码所实现的功能是一样的,但是JavaScript是动态类型的,而C++是静态类型的,它们二者的对比如下:
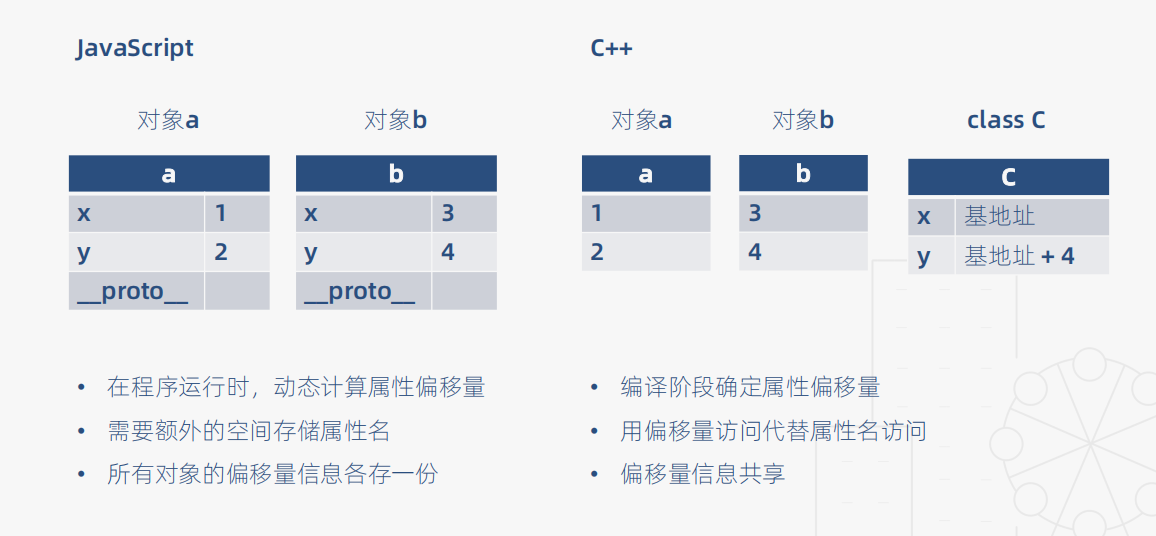
通过上面的对比,二者的优势如下:
- 静态类型
- 代码更可读,可以实现一定程度上的自文档化;
- 代码更健壮,可以在编译期就发现很多bug;
- 代码运行时性能更好
- 动态类型
- 代码更灵活
- 代码更灵活
- 代码更灵活…
这么看下来,使用动态类型好像有点得不偿失,但是:
- 性能是可以改善的
- 隐藏的错误可以通过单元测试发现
- 文档可以通过工具生成…
总之,在硬件越来越强大,软件迭代越来越快的今天,动态类型似乎也越来越受欢迎了。
灵活使用类型
数据类型是高级语言抽象出来,为数据的存储和数据可以进行的操作提供元数据信息的。它代表了一门高级语言最基本的抽象能力。一门语言的数据类型的灵活性将直接影响整门语言的灵活性。
对于动态类型的语言,其类型本身就很灵活。动态类型的语言往往通过鸭子类型来最大化数据类型的抽象能力;对于静态类型的语言,类型的使用就相对没有那么灵活了,这种不灵活性是由于编译期对左值类型的限制造成的,所以很多静态类型的语言提供了类似泛型或者模板的功能,以提高类型使用的灵活性。
类型参数化
静态类型可以提高程序的可读性和健壮性,可以在编译期就消除很多的bug;但是,我们上文也提到了,静态类型的语言由于在编译时限制了左值的类型,这在很大程度上限制了编码的灵活性,为代码的重用造成了一定的障碍,而代码的重用能力又是一门语言所亟待解决的问题——于是,静态类型成了一堵围城,城里的人想出去,城外的人想进来。
为了更大程度上提高代码的抽象能力和复用能力,很多静态类型的编程语言提供了泛型或者模板的功能,这种技术的核心思想就是类型参数化,把数据类型当做参数使用,让编译器根据类型参数生成对应类型的代码或者是进行静态类型校验。
比如C++中提供了模板的功能,编译器可以根据模板生成实际的代码;Java提供了泛型,编译器根据类型参数来进行静态类型校验,由于Java在实现泛型的时候采用了类型擦除的解决方案,所以Java中的泛型并不会生成实际类型的代码,而是在使用类型参数的地方自动插入类型转换的代码…
如下C++代码:
#include <iostream>
using namespace std;
template <typename T>
void duck_like_tweet(T *duck_like) {
duck_like->tweet();
}
class Goose {
public:
void tweet();
};
void Goose::tweet() {
cout << "Goose" << endl;
}
class Duck {
public:
void tweet();
};
class Human{
public:
void tweet(string &msg);
};
void Human::tweet(string &msg) {
cout << msg << endl;
}
void Duck::tweet() {
cout << "Duck" << endl;
}
int main() {
duck_like_tweet(new Goose);
duck_like_tweet(new Duck);
// duck_like_tweet(new Human);
}
上述代码中的Goose和Duck这两个类之间并没有任何的继承关系,但是我们使用一个模板类把类型参数化之后,这两个类就可以使用同一个方法了。
C++的模板使用类预编译的处理方式,而预编译发生在代码的编译之前,所以C++的参数化类型更接近于我们下面要介绍的鸭子类型。而像Java中的泛型,它的能力检查是基于类型的,还要有所不同,下一篇文章中我们会进行介绍。
参数化类型中的协变、逆变和不可变
在类型被参数化之后,相当于我们可以针对类型进行运算从而产生一个新的类型。如果作为类型实参的类型之间存在继承关系,那么我们通过运算之后得到的新类型之间是不是也存在继承关系呢?这其实分为三种情况:
- Covariant(协变)
- Contravariant(逆变)
- invariant(不变)
受限于篇幅,这篇文章中我就不对变型这个话题进行深入讨论了,下一篇文章中将会专门介绍静态类型语言中的泛型和变型相关的内容。
鸭子类型
动态类型的语言本身就是非常灵活的,由于我们在编码的时候并不知道一个左值中的数据是什么类型的,而我们在动态类型的语言中使用一个左值的时候往往也不用太关注它是什么类型的,我们在使用的时候往往只关注一个值具有什么样的能力(或者说能进行什么样的操作)就可以了。
这种使用值的风格就是典型的鸭子类型——只要一只鸟,它看起来像鸭子、走起来像鸭子、游起来也像鸭子,但是我们并不知道这到底是一种什么鸟,那我们就认为它是一只鸭子。
比如下面的Python代码:
class Goose:
def tweet(self):
print('Goose')
class Duck:
def tweet(self):
print('Duck')
def like_duck_tweet(duck_like):
if hasattr(duck_like, 'tweet'):
duck_like.tweet()
if __name__ == '__main__':
goose = Goose()
duck = Duck()
like_duck_tweet(goose)
like_duck_tweet(duck)

可以看到Goose和Duck这两个类之间并没有任何的继承关系,但是这两者有共同的能力,就是能够鸣叫,所以我们在调用like_duck_tweet方法的时候,这两个类的实例都是可以作为参数的。
从上面我们也可以看出,鸭子类型关注的是值的能力,而不是值的类型。而我们在使用类似风格的语言的时候,代码中也会出现非常多的能力检测代码,就像上面代码中的if hasattr(like_duck, 'tweet')一样。
泛型 VS 鸭子类型
和泛型不同的是,鸭子类型的能力检测一般发生在运行时,这个时候我们如果处理不好的话代码的运行就会受到影响。而泛型的检查大都发生在静态阶段,我们可以在代码的运行之前就发现大多数的类型错误。
灵活使用类型的本质
提高类型的灵活性的核心思维其实和鸭子类型的思维是不谋而合的——我们只想关注值所拥有的能力,而不想关注值的类型。
其实我们在上文中介绍的c++模板的那段代码也在一定程度上体现出了鸭子类型的思维:
在void duck_like_tweet(T *duck_like)这个模板方法中,我们并不知道T的实际类型是什么,但是我们要求这个类型的值能够鸣叫。c++的编译器在根据实际的类型生成对应类型的代码之后,会再走一遍编译的流程,这时候就会判断传进来的类型是不是符合要求,如果我们把上面c++代码的最后一行的注释打开,编译器就会提示如下错误:

意思就是Human类中并没有符合使用要求的tweet()方法。这和鸭子类型的思维是差不多的,只不过能力检测是在静态阶段由编译器完成的。
当然有一些静态类型的语言的泛型并不是基于能力检测的鸭子类型,而是一种纯粹的类型判断,比如Java,但是静态类型中能力是基于类型的,所以说到底思想还是一样的:
最灵活的使用类型的模式是只关注值的能力而不关注值的类型。
GoLang——一只‘静态鸭’
我们上面说明了各种语言中提高类型使用灵活性的方法,大致的套路如下:
- 静态类型中一般通过类型参数化来提高类型的灵活性
- 动态类型中一般通过鸭子类型来提高类型的灵活性
但是事情并不是绝对的,上面我们已经介绍过了TypeScript中提供了静态类型检查的能力,其中的一个重要特性就是泛型;而我们这里要介绍的是GoLang。
Go语言是静态强类型的,其一直以精炼著称,其类型系统也是短小精悍,而网上讨论的比较多的就是Go语言到底是不是面向对象的编程语言——因为Go语言并不支持继承。
但是,在我的眼里,Go语言是支持面向对象编程范式的,只不过其更类似于基于原型的流派,而不是基于类的。同时其对多态的支持也是通过其接口的鸭子类型机制来实现的。
可以看到Go语言中灵活使用类型的做法却是动态类型常用的解决方案。
下面我给出一个在基于类型的面向对象语言中非常典型的应用场景——模板方法来说明一下:
package ch13
import (
"fmt"
"testing"
)
// 所有步骤定义一个接口
type Executor interface {
stepOne()
stepTwo()
}
// 模板结构
type ExecutorTemplate struct {
//Executor
executor Executor
}
// 模板方法实现
func (s *ExecutorTemplate) say() {
s.executor.stepOne()
s.executor.stepTwo()
}
// 实现步骤的策略结构
type ExecutorA struct {}
func (p *ExecutorA) stepOne() {
fmt.Println("ExecutorA stepOne()")
}
func (p *ExecutorA) stepTwo() {
fmt.Println("ExecutorA stepTwo()")
}
type ExecutorB struct {
ExecutorA
}
func (st *ExecutorB) stepTwo() {
fmt.Println("ExecutorB stepTwo()")
}
// 测试代码
func TestXX(t *testing.T) {
fnTemplate := ExecutorTemplate{new(ExecutorB)}
fnTemplate.say()
}
上面的代码中定义了两个结构,ExecutorA和ExecutorB,其中ExecutorA是ExecutorB的原型。我们声明了一个接口,其中有两个方法stepOne()和stepTwo(),ExecutorA中有两个签名一致的方法,fnTemplate := ExecutorTemplate{new(ExecutorB)}这行代码中我们构造了一个ExecutorTemplate实例,这个实例有一个Executor接口成员。我们可以看到,在ExecutorB中我们没有任何说明其实现了接口Executor的代码,但是这个赋值是成立的,说明了其利用了鸭子类型的能力检查机制。
同时,ExecutorB并没有实现stepOne方法,但是ExecutorA是它的原型,ExecutorA是实现了stepOne方法的,所以ExecutorB也就具有了stepOne的能力,最终静态能力检测得以通过。运行上面的测试方法,结果如下:
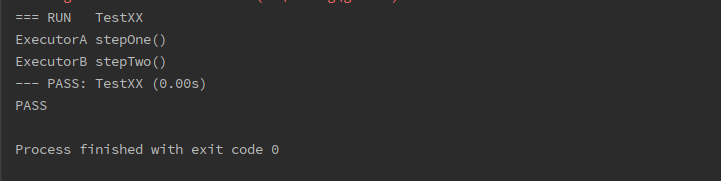
上面的Go代码其实还有很多需要注意的细节,这里我们不做过多的说明。
强类型/弱类型
对于类型的强弱,这个概念一直是模糊不清的,并没有一个明确的定义。网上的解释也比较杂乱,而且往往是错误的解释。比如有人说因为在Python中下面的代码会抛出错误而认为Python是强类型的:
if __name__ == '__main__':
s = 'a'
i = 1
st = s + i //Error
但是这这种解释是不太合理的,在Java中类似的代码是可以正常运行的,但是Java也是公认的强类型语言。
那么,到底该怎么定义强类型和弱类型的,二者是如何进行界定的呢?下面是我摘抄自维基百科的解释:
强弱类型(Strong and weak typing)表示在计算机科学以及程序设计中,经常把编程语言的类型系统分为强类型(英语:strongly typed)和弱类型(英语:weakly typed (loosely typed))两种。
这两个术语并没有非常明确的定义,但主要用以描述编程语言对于混入不同数据类型的值进行运算时的处理方式。
强类型的语言遇到函数引数类型和实际调用类型不符合的情况经常会直接出错或者编译失败;而弱类型的语言的类型规则比较宽松,常常会实行隐式转换,或者产生难以意料的结果。
其实上面的解释也是不尽人意的,但是我们可以抓住关键的一点:用以描述编程语言对于混入不同数据类型的值进行运算时的处理方式。
- 强类型所表现出来的特征是:类型会对操作产生明显的影响,类型限制了可以在该种类型的值上进行的操作并且明确了这些操作的含义,限制表达式可以产生的值。如果对不支持某个操作的类型的值进行了某个操作,则会在编译时或者运行时提示错误,而不会让程序以某种不可预知的方式继续运行。
- 而弱类型的语言常常会实行隐式转换,或者产生难以意料的结果;弱类型表现为对类型的容忍度较高,如果操作符接收到的操作数的数据类型和定义操作符是定义的数据类型不相符的时候,不会直接报出异常,而是首先尝试将接收到的值转换为操作符期望的数据类型的值,然后再使用操作符进行运算,如果数据类型转换失败,最终才会抛出异常。
也就是说,类型的强弱实际上描述的是,语言对类型的敏感程度。
其实在谈到类型的强弱的时候,我们更侧重的是类型的安全程度,即程序在编译时和解释时不是会检测一些非法的操作,以保证操作的安全和合法性。对于这一点最典型的例子就是数组访问的越界检查。
很多人都把类型的静/动和强/弱混为一谈,诚然,静态类型的编程语言对类型好像天生比较敏感,其看上去好像就是强类型的,其实这是因为静态类型本身固有的静态期类型检查的功能所造成的错觉,实际上强/弱跟静/动描述的是不同的维度。
- 静/动描述的是语言是不是限制左值的数据类型
- 强/弱则主要描述语言对类型的敏感程度,侧重于描述语言的类型安全性
比如C语言,它是静态类型的,静态类型检查是其固有的属性,但是其设计思想是——相信程序员,不妨碍程序员做任何事情。这就意味着其类型是比较弱的——它连数组访问是否越界都不会进行检查。
同时,对语言强弱类型的划分并没有明显的分界线,但是我们的直观感受是——如果一门语言对外声称自己是强类型的,那么我们在使用类型的时候就会受到更多的限制。
强类型 VS 弱类型
强类型的语言对类型的使用会有更多的限制,由于要实现这些限制,程序在运行时往往需要作出一定的校验动作,这会消耗额外的性能;但是程序的安全性可以得到保证,不会或者说很少会发生莫名其妙的bug。
弱类型的语言对类型的限制较少,往往可以得到更好的性能,但也不是绝对的,比如JavaScript,由于在运行的时候要尽可能使得程序正常运行并产生结果,可能要进行各种各样的类型转换,反而会消耗性能。
就个人而言,本人更加喜欢强类型的语言,一个优秀的软件工程师在使用一门语言的时候应该是充分理解该语言的特性之后把自己限制在一个特定的子集里,以求自己的程序更加稳定,强类型的语言可以帮助我们完成这一点。而且,弱类型的语言往往会发生不可控的副作用,尤其是C语言这种本身非常底层的语言,发生的不可控副作用可能是具有毁灭性的。
标量数据类型
关于标量数据类型、基本数据结构、高级数据结构的内容可以参考《数据结构中的原子、分子和物质》一文。
我们这里所说的标量数据类型其实跟字面值有一定的相关性,包括数字、字符串、布尔值等。
我们前面的文章中提到过,字面值是我们向程序中传递信息的最终方式,而标量数据类型具有这样的特点:
- 其本身代表值,不具有结构信息,或者说我们可以忽略它的结构信息,比如字符串,其底层往往是一个数组,但是我们在使用的时候可以把它看做一个逻辑上的点,而不用过多关注其底层的数据结构。
我们这里为什么要把标量数据类型单独拎出来呢?
这是因为,不管在哪一门语言中,标量数据类型都应该是语言的内建类型,用户通过自定义的方式声明的类型都不会是标量,而是一个具有结构的数据类型(某些语言中的枚举除外)。
通过上面的分析,我们可以得出这样一个结论:标量就是数据类型中的‘原子’,是构成具有结构的类型的基础。
如下js代码:
let obj = {
a: 12,
b: 'a',
c: true,
d: {
a: 12,
b: 'a',
c: true,
}
}
上面我们创建了一个对象obj(注意这不是创建了一个类型,而是一个对象,严格来说js中没有任何自定义类型的机制),它是具有结构的,而且里面还嵌套了一层,我们可以观察一下obj是不是最终是由一个个标量所组成的。
字面值的补充
其实这里是对《高级语言中的单词——5种类型的token》一文中字面值部分的补充,里面所介绍的字面值其实就只包含了标量,其实一门语言所支持的字面值可能更多,比如我们上面的js代码中就使用了js中的对象字面值。
值集
每一种数据类型都有其所能表示的值的范围,一个数据类型所能表示的所有的值我们就称之为这个数据类型的值集。
在讨论数据类型的值集的时候其实我们只需要关注标量数据类型的值集,原因有以下几点:
- 标量数据类型都是语言内建的数据类型
- 标量数据类型的值集往往与硬件相关,比如java中的int类型的值集是 -2147483648~2147483647 的闭区间。
- 标量数据类型是数据类型中的原子,是构成所有具有结构的数据类型的基础。
不同语言对于标量类型都具有不同的规则,相似标量类型的值集可能也有所不同,在我们介绍具体语言的时候会对语言的标量类型的值集有所介绍。
真假值
布尔类型在任何一门高级程序设计语言中都是一个使用频率相当高的数据类型,因为任何的逻辑判断的结果都是由布尔类型的值表示的。为了编码方便,很多操作语言的类型系统都引入了真值和假值的概念。
当一个不是bool类型的值转化成bool类型之后如果是
true,我们就称其为真值,反之,如果一个不是bool类型的值转化为bool类型值后值为false,那么我们就称这个值为假值。这样就相当于在任何数据类型中都有跟true和false等价的值,这样我们在进行逻辑判断的时候就能够依赖真值和假值的特性。
在支持真假值的类型系统中,一个值除了其本身所代表的值之外,还代表了一个逻辑值,支持真假值在动态类型系统中是比较常见的,比如在js中,下面的代码是非常常见的:
let obj = ? //我们不知道obj的实际值是怎样的,但是可以确定的是其是一个对象
let value = (obj || {value:1}).value
obj如果是null或者是undefined,那么我们最终得到的value是1。
也就是说,在支持真假值的类型系统中,逻辑表达式会返回一个真值或假值,而其数据类型还是其原来的数据类型,并不是一个布尔类型。这会给我们的编程带来极大的方便。
总结
在这篇文章中,我们简要介绍了描述一门语言类型系统的两个方面:静/动和强/弱。这是两个维度,我们不应该把它们混为一谈。而文中,我们也留下了一个问题——静态类型的编程语言中灵活使用类型的常用手段是泛型,而泛型其实就是参数化类型,它允许我们在代码中定义类型变量,在真正使用的时候才决定具体的类型是什么。这其实为我们提供了一种用现有的类型构造更复杂类型的手段,同时也引出了另一个问题——变型。下一篇文章我们就来简单介绍一下静态类型的编程语言中的参数化类型和变型。
同时,这篇文章比较长,感谢你耐心读完。本人深知技术水平和表达能力有限,如果文中有什么地方不合理或者你有其他不同的思考和看法,欢迎随时和我进行讨论(laomst@163.com)。
















 786
786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











