






007
007: Democratically Finding The Cause of Packet Drops
NSDI ’18
作者:Behnaz -伊朗
单位:微软
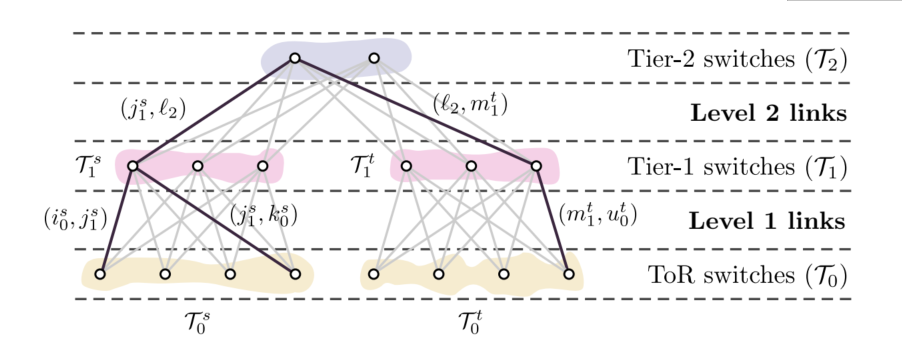
前序: 这篇 paper 他说T-1 (Tier-1) 交换机和Tier-2交换机… 我以为是L1和L2的交换机,而且他在文章正式部分没有给结构图,而是在最后一页的证明部分才给!!!
结果发现T2说的是L3交换机, T1说的是L2交换机!!!
数据中心网络默认规则 Tier 就是说数据中心架构, Layer 说的是交换机ISO层数
但是对Tier-0是指最上层还是最下层,好像没有统一的意见。
这一篇的我想获得的知识点:
1.traceroute 如何在数据中心做故障定位的
在一个汇聚层下路由,它的IP地址是走
2.ETW 的TCP重传检测是如何工作的,或者说TCP本身就有重传检测吗?
(本篇paper在github上有源码)
3.交换机CPU发送ICMP包,响应traceroute 的上限是100/秒。
1 Introducion
网络故障症状和它们发生的地方和原因没有直接的关系,这困扰着网络运维人员。
007 争对每条丢包的TCP连接,找出造成丢包的link。
007是 end host、always-on、lightweight。
验证:Tier-1 DC 部署两个月。
提出三个问题
少量的丢包会影响到正常业务,例如 会导致VM 重启。
1.2 Challenges
-
Engineering challenges
- tracertoute packets need to be carefully carafted to ensurethat they follow the same path as the TCP flow.
- traceroute sampling strikes the right balance between accuracy and the overhead on the switches.
-
theoretical challenge
- we are able to show that 007’s simple blame assignment scheme is highly accurate even in the presence of noise
1.3 Contribution
-
(i) design 007, a simple, lightweight, and yet accurate fault localization system for datacenter networks;
- First, not require any changes to the existing networking infrastructure.
- Second, not require changes to the client software—the monitoring agent is an independent entity that sits on the side.
- Third, detects in-band failures.
- Fourth, continues to perform well in the presence of noise (e.g. lone packet drops).
- Finally, overhead is negligible.
另外slide里写的:
- Detect short-lived failures
- Detect concurrent failures
- Robust to noise
-
(ii) prove that 007 is accurate without imposing excessive burden on the switches;
-
(iii) prove that its blame assignment scheme correctly finds the failed links with high probability; and
-
(iv) show how to tackle numerous practical challenges involved in deploying 007 in a real datacenter
1.summary:
利用traceroute去故障定位,通过blame制度去找到重传的原因,
测量目标:争对每个TCP flow中的packet丢包做一个诊断.
每个TCP flow都能做检测,这将可以和应用程序关联起来.(好处:在修复的时候可以有一个优先级)
这系统的优点是
1.带内测量-使用相同的五元组
2.不改变网络基础设施
3.限制路由器的回复的ICMP报文.
2.overview
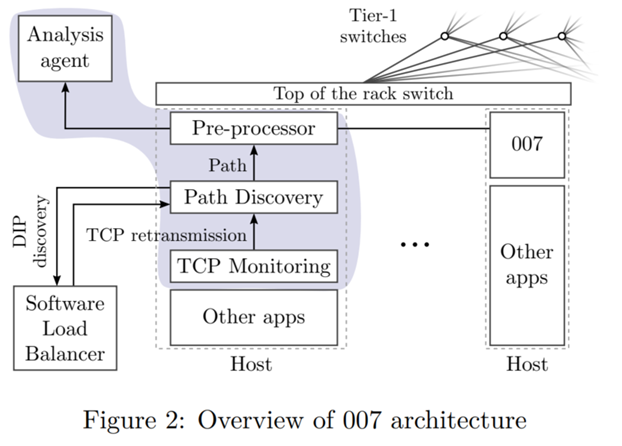
三个部分,
TCP monitoring Agent-部署ETW框架,当TCP重传时,触发Path discovery
Path discovery-识别flow到D IP的路径
Analysis Agent:在hosts会有 voted scheme,然后30s汇聚一次 Analysis Agent
2.1 TCP monitoring Agent
在每个终端上部署,去探测TCP重传.用到的工具是ETW (event tracing for windows),linux也存在这样的功能.
The Event Tracing For Windows(ETW) [14] framework notifies the agent as soon as an active flow suffers a retransmission .
2.2 Path Discovery Agent:
被 TCP monitoring触发之后, 利用traceroute去探测重传路径
The path discovery agent uses traceroute packets to find the path of flows that suffer retransmissions.
2.3 Analysis Agent
进行voting scheme ,找出top-voted links.
2.4 Cost of 007
007’s implementation consists of 6000 lines of C++code.
Its memory usage never goes beyond 600 KB on any of our production hosts,
its CPU utilization is minimal (1-3%), and
its bandwidth utilization due to traceroute is minimal (maximum of 200 KBps per host).
3.Challenge
3.1.获取五元组
因为需要用traceroute去进行跟踪,所以需要获取相同的五元组才能走一样的路径.
所以需要考虑的是负载均衡.
方法相似于[16] Ananta: Cloud scale load balancing
ACM SIGCOMM Computer Communication Review
1.TCP连接的SYN目的地址是VIP 发往SLB . SLB会给 the VIP 分配一个DIP和端口
2.SLB会把DIP配置给相应的源机器的 VSwitch
3.之后的包 直接使用DIP
4.traceroute 去询问SLB得到VIP-DIP mapping,然后直接用DIP进行传输.
1.The connection is first established to a virtual IP (VIP) and the SYN packet (containing the VIP as destination) goes to a software load balancer (SLB) which assigns that flow to a physical destination IP (DIP) and a service port associated with that VIP.
2.The SLB then sends a configuration message to the virtual switch (vSwitch) (in the hypervisor of the source machine that registers ) that DIP with that vSwitch.
3.The destination of all subsequent packets in that flow have the DIP as their destination and do not go through the SLB.
4.For the path of the traceroute packets to match that of the data packets, its header should contain the DIP and not the VIP.
3.2 Re-routing and packet drops
traceroute packet可能会出现故障,但是没有关系,这样子就帮助我们直接指出了故障的链路.
3.3.traceroute和packet路径是否一样?
这是一个问题,路径不改变只要少于 几毫秒,那么我们就可以使得traceroute跟踪相同的路径与packet.
整个过程和时间:
RTT少于1-2ms,(应该是说超过这个时间就进行重传)
然后ETW立刻通知监测Agent,然后唤醒路径探测
路径探测会查询缓存, 如果有必要,会询问VIP-DIP的mapping(询问 这一步少于1ms)
RTT重传时间阈值 (1-2ms)+ ETW立刻激活路径探测+路径探测在SLB查询 mapping(less 1ms)
4.Blame 机制
汇总计票时间是:每次的epoch.(我猜测一个epoch就是一个流 ,证据如下)
it allows 007 to find the most likely cause of packet drops on each flow.
好的路径:得分0
有流重传的路径:每个链路得1/h 分, h是该路径的跳数。
消除noise,减少误报率:挑选most voted link --Lmax ,然后按比例去剔除 因为Lmax而得分的links–K.
进一步通过算法1: 总分数的1%作为阈值,作为清理参数,这在漏报率和误报率之间找到了一个平衡。

5.缺点
5.好词好句
6.知识点
- 数据中心中的几乎所有流量都是TCP流量 - p3
- links are bad , **due to devices,port,cable,**etc.
7.创新点
-
the same mechanisms can be used in other contexts as well (see §9).
同样的机制可以用在其他背景之下(华为那个工具也是这样的啊,算是一个优点,可移植性)
8.阅读中的问题
-
Re-routing and packet drops ,那我们怎么识别是真的随机丢包了,还是因为故障丢包的呢?
-
数据中心 超时重传设置的时间大概是多少?
-
out-of-band 是什么意思?
Also, since it uses out-of-band probes, it cannot detect failures that affect only in-band data . -
-
out-of-band指的是跟某些应用或者数据不同一个传输通道
比如pingmesh用的是ping的icmp报文,跟应用是不一样的
-
in-band:如果直接用应用的报文来测量,或者是用应用的同一个flow(五元组相同)来测量
或者:我的浏览器访问某一个网页,先建立socket连接,然后进行HTTP交互,交互完之后不关掉socket,继续用这个socket来收发探测报文,这也是in-band
-
-
一个TCP flow能有多大,它能丢多少的包? 不然怎么去区分 lone packet drop?
-
flow 重传和 packet 重传有区别? 007都是说flow重传.
if a flow has no retransmission, no traceroute is needed.
- 应该是flow中的packet重传.
-
.这个是为什么 B不是应该包含在L里面了嘛? B©是什么意思?
9.相关paper
有很多丢包的原因解决方法:
- One can **monitor switch counters.**These are inherently unreliable [5] and monitoring thousands of switches at a fine time granularity is not scalable
- [5]Automating datacenter network failure mitigation. --ACM SIGCOMM Computer Communication Review 42, 4 (2012)
- One can use new hardware capabilities to gather more useful information [6],Correlating this data with each retransmission reliably is difficult
- [6]Language-directed hardware design for network performance monitoring. --In Proceedings of the Conference of the ACM Special Interest Group on Data Communication
(2017), ACM, pp. 85–98.
- [6]Language-directed hardware design for network performance monitoring. --In Proceedings of the Conference of the ACM Special Interest Group on Data Communication
- One can use PingMesh [1] to send probe packets and monitor link status. Such systems suffer from a rate of probing trade-off: sending too many probes creates unacceptable overhead whereas reducing the probing rate leaves temporal and spatial gaps in coverage.
- Everflow 无法提前预知,必须去跟踪每个TCP包才可以去获知丢包情况,但是这是不可能去实现跟踪每个包,因此导致我们必须去跟踪一部分的包, 是和采样率的权衡了 (这个角度可以的)
- Network Tomography 和故障定位有关的. [7, 8, 9]

















 1852
1852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









