







文章目录
前言
网络上有着很多这种类型的使用说明以及教程,但终归不是自己的。
遇到不会的时候还得不断的重复去百度,这样导致效率低下。
最终还是想着结合网上的教程,给自己归纳总结一部分库的使用,方便自己回顾。
selenium (from selenium import webdriver)
- 更详细操作见:Selenium_Python英文版、Selenium中文翻译操作文档
- Selenium手册
- Selenium使用
- Selenium教程
- 这边推荐一个元素测试网站(动作链部分针对于该网站):元素测试网站
1、安装
-
安装步骤1:通过
pip install selenium安装
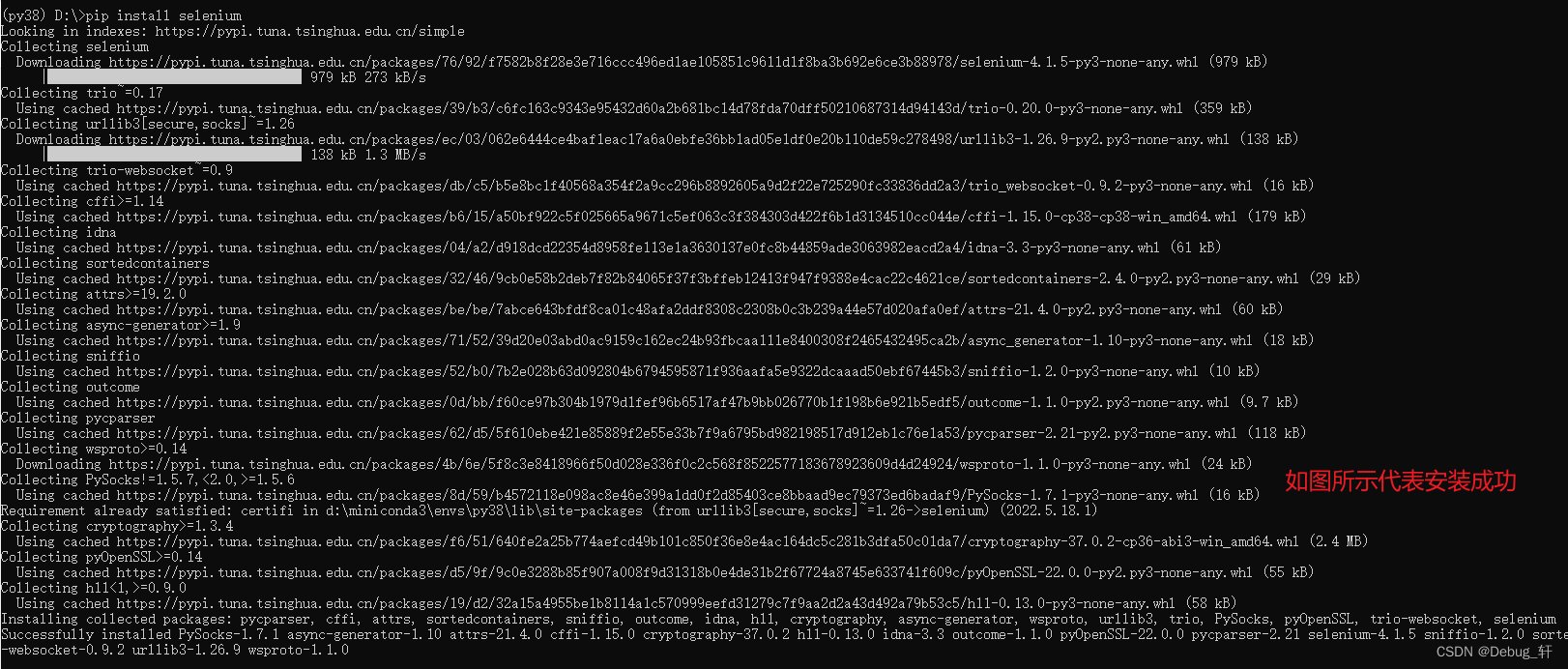
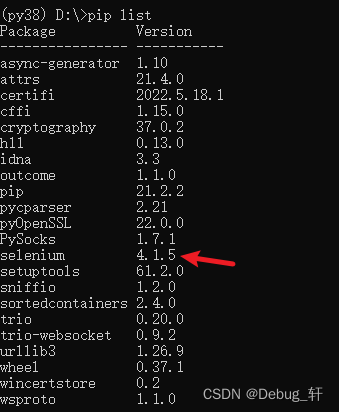
-
安装步骤2:安装与计算机使用浏览器版本相对应的WebDriver
- Chrome(ChromeDriver与浏览器对应的版本)
- Firefox(默认下载最新的geckodriver即可)
-
安装步骤3:下载完成解压后,将文件移动到一个配置了环境变量的文件夹中,例如Python环境的文件夹下。
2、基本使用
- Selenium是一个用于Web应用程序测试的工具。
- Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Firefox,Safari,Chrome,Opera等。
- Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。同时也可以获取页面的源代码,可以获取页面渲染后的元素,做到
可见即可爬
'''
功能如下:
自动弹出一个Chrome浏览器,浏览器首先会跳转至百度,然后输入Python,回车,等待3秒,自动关闭浏览器。
'''
import time
from selenium import webdriver
from selenium.webdriver.common.by import By # 显示等待中使用By进行定位元素
from selenium.webdriver.common.keys import Keys # 可以实现键盘回车的功能
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome() # 声明Chrome浏览器对象
try:
browser.get('https://www.baidu.com') # get()方法请求网页
input_item = browser.find_element(By.ID, 'kw') # 定位到百度输入框,find_element()方法获取单个元素节点
input_item.send_keys('Python') # send_keys()方法向input框中填入字符串
input_item.send_keys(Keys.ENTER) # 模拟键盘回车
wait = WebDriverWait(browser, 10) # 显示等待,指定加载的最长时间
wait.until(EC.presence_of_element_located((By.ID, "content_left"))) # 等待内容节点,直到出现进行下一步
print(browser.current_url) # 获取当前浏览器中url
print(browser.page_source) # 获取当前url的网页源代码
finally:
time.sleep(3) # 等待3s
browser.quit() # 退出浏览器
3、声明浏览器对象
- 在使用Selenium之前肯定要先声明浏览器对象,以下代码完成了浏览器对象的初始化并赋值给browser对象,接下来就是调用browser对象,让其执行一系列的人为操作。
'''
功能如下:
声明浏览器对象
'''
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.Safari()
4、访问页面
- get():请求网页,参数:url网址
'''
功能如下:
输入一个网址,通过selenium进行访问页面
'''
from selenium import webdriver
browser = webdriver.Chrome() # 创建浏览器对象
browser.get("https://www.baidu.com") # get() 方法访问页面
print(browser.page_source) # 获取网页源代码
browser.quit() # 退出浏览器
5、查找节点
5.1 查找单个节点
- find_element():返回的是WebElement类型,这个方法需要导入这个包
from selenium.webdriver.common.by import By
find_element_by_XXX:这个方法不需要额外添加依赖包
| 方法1 | 方法2 |
|---|---|
| find_element_by_id | find_element(By.ID, “”) |
| find_element_by_name | find_element(By.NAME, “”) |
| find_element_by_xpath | find_element(By.XPATH, “”) |
| find_element_by_link_text | find_element(By.LINK_TEXT, “”) |
| find_element_by_partial_link_text | find_element(By.PARTIAL_LINK_TEXT, “”) |
| find_element_by_tag_name | find_element(By.TAG_NAME, “”) |
| find_element_by_class_name | find_element(By.CLASS_NAME, “”) |
| find_element_by_css_selector | find_element(By.CSS_SELECTOR, “”) |
单独拿一个id做案例,代码使用参考如下:
'''
功能如下:
实现查找节点中id方法的案例
案例网站:【豆瓣电影排行榜】https://movie.douban.com/chart
'''
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def fun_one():
'''
使用 find_element_by_xxx类型
:return:
'''
icp1 = browser.find_element_by_id('icp')
icp2 = browser.find_element_by_xpath('//span[@id="icp"]')
icp3 = browser.find_element_by_css_selector('#icp')
print("方法一:")
print(icp1)
print(icp2)
print(icp3)
def fun_two():
'''
使用 find_element()类型
:return:
'''
icp1 = browser.find_element(By.ID, 'icp')
icp2 = browser.find_element(By.XPATH, '//span[@id="icp"]')
icp3 = browser.find_element(By.CSS_SELECTOR, '#icp')
print("方法二:")
print(icp1)
print(icp2)
print(icp3)
if __name__ == '__main__':
browser = webdriver.Chrome()
browser.get('https://movie.douban.com/chart')
wait = WebDriverWait(browser, 15)
wait.until(EC.presence_of_element_located((By.ID, "content")))
fun_one() # 方法一:find_element_by_xxx类型
fun_two() # 方法二:find_element()类型
browser.quit()
# 最后运行的结果如下
#方法一:
#<selenium.webdriver.remote.webelement.WebElement (session="65c0086ed6faf3c3c2b63e349de342d0", element="c62310d9-a5aa-4b66-9ed0-fd9ea0a178c0")>
#<selenium.webdriver.remote.webelement.WebElement (session="65c0086ed6faf3c3c2b63e349de342d0", element="c62310d9-a5aa-4b66-9ed0-fd9ea0a178c0")>
#<selenium.webdriver.remote.webelement.WebElement (session="65c0086ed6faf3c3c2b63e349de342d0", element="c62310d9-a5aa-4b66-9ed0-fd9ea0a178c0")>
#方法二:
#<selenium.webdriver.remote.webelement.WebElement (session="65c0086ed6faf3c3c2b63e349de342d0", element="c62310d9-a5aa-4b66-9ed0-fd9ea0a178c0")>
#<selenium.webdriver.remote.webelement.WebElement (session="65c0086ed6faf3c3c2b63e349de342d0", element="c62310d9-a5aa-4b66-9ed0-fd9ea0a178c0")>
#<selenium.webdriver.remote.webelement.WebElement (session="65c0086ed6faf3c3c2b63e349de342d0", element="c62310d9-a5aa-4b66-9ed0-fd9ea0a178c0")>
5.2 查找多个节点
- find_elements():返回的是列表类型,列表里面每一个都是WebElement类型。
find_elements_by_XXX:这个方法不需要额外添加依赖包
| 方法1 | 方法2 |
|---|---|
| find_elements_by_id | find_elements(By.ID, “”) |
| find_elements_by_name | find_elements(By.NAME, “”) |
| find_elements_by_xpath | find_elements(By.XPATH, “”) |
| find_elements_by_link_text | find_elements(By.LINK_TEXT, “”) |
| find_elements_by_partial_link_text | find_elements(By.PARTIAL_LINK_TEXT, “”) |
| find_elements_by_tag_name | find_elements(By.TAG_NAME, “”) |
| find_elements_by_class_name | find_elements(By.CLASS_NAME, “”) |
| find_elements_by_css_selector | find_elements(By.CSS_SELECTOR, “”) |
'''
功能如下:
实现查找节点中id方法的案例
案例网站:【豆瓣电影排行榜】https://movie.douban.com/chart
'''
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def fun_one():
'''
使用 find_elements_by_xxx类型
:return:
'''
items1 = browser.find_elements_by_css_selector('div.indent .item')
items2 = browser.find_elements_by_xpath('//div[@class="indent"]//tr[@class="item"]')
print("方法一:")
print(items1)
print(items2)
def fun_two():
'''
使用 find_elements()类型
:return:
'''
items1 = browser.find_elements(By.CSS_SELECTOR, 'div.indent .item')
items2 = browser.find_elements(By.XPATH, '//div[@class="indent"]//tr[@class="item"]')
print("方法二:")
print(items1)
print(items2)
if __name__ == '__main__':
browser = webdriver.Chrome()
browser.get('https://movie.douban.com/chart')
wait = WebDriverWait(browser, 15)
wait.until(EC.presence_of_element_located((By.ID, "content")))
fun_one() # 方法一:find_elements_by_xxx类型
fun_two() # 方法二:find_elements()类型
browser.quit()
6、节点交互(操作节点事件)
- Selenium驱动浏览器执行一些动作,比较常见的方法有:
- send_keys():输入文字方法
- clear():清空文字
- click():点击按钮
- submit():回车
- 更多操作见:文档
'''
功能如下:
实现input框的输入
实现input框的清空
实现元素的点击操作
'''
import time
from selenium import webdriver
from selenium.webdriver.common.by import By # 显示等待中使用By进行定位元素
from selenium.webdriver.common.keys import Keys # 可以实现键盘回车的功能
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome() # 声明Chrome浏览器对象
try:
browser.get('https://cn.bing.com/') # get()方法请求网页
input_item = browser.find_element(By.ID, 'sb_form_q') # 定位到百度输入框,find_element()方法获取单个元素节点
input_item.send_keys('Python') # send_keys()方法:向input框中填入字符串
input_item.submit() # 模拟键盘回车
# input_item.send_keys(Keys.ENTER) # 模拟键盘回车
wait = WebDriverWait(browser, 10) # 显示等待,指定加载的最长时间
wait.until(EC.presence_of_element_located((By.ID, "b_results"))) # 等待内容节点,直到出现进行下一步
time.sleep(1)
input_item2 = browser.find_element(By.ID, 'sb_form_q')
input_item2.clear() # clear()方法:清空input框内容
time.sleep(0.2)
input_item2.send_keys("阿尔法") # send_keys()方法:输入字符串
browser.find_element(By.ID, "sb_form_go").click() # click()方法:进行点击操作
finally:
time.sleep(3) # 等待3s
browser.quit() # 退出浏览器
7、动作链
- 用selenium做自动化,有时候会遇到需要模拟鼠标操作才能进行的情况,比如单击、双击、点击鼠标右键、拖拽等等。而selenium给我们提供了一个类来处理这类事件——ActionChains
- 更多操作见:文档
使用动作链常用的几个场景,如下:
- 鼠标点击(单击、双击、右键)
- 鼠标移动(解决hover的某些问题)
- 鼠标拖拽(实现节点拖拽操作,将某个节点从一处拖拽到另一处。)
- 按键监听(监听按键的状态)
ActionChains方法列表
click(on_element=None) # 单击鼠标左键
click_and_hold(on_element=None) # 点击鼠标左键,不松开
context_click(on_element=None) # 单击鼠标右键
double_click(on_element=None) # 双击鼠标左键
drag_and_drop(source, target) # 按住鼠标左键拖拽到某个元素然后松开
drag_and_drop_by_offset(source, xoffset, yoffset) # 拖拽到某个坐标(偏移量)然后松开
key_down(value, element=None) # 按下某个键盘上的键,不释放
key_up(value, element=None) # 松开某个键
move_by_offset(xoffset, yoffset) # 鼠标从当前位置移动到某个坐标
move_to_element(to_element) # 鼠标移动到某个元素的中间
move_to_element_with_offset(to_element, xoffset, yoffset) # 移动到距某个元素(左上角坐标)多少距离的位置
perform() # 执行链中的所有动作
release(on_element=None) # 在某个元素位置松开鼠标左键
reset_actions() # 清除链中的所有操作
send_keys(*keys_to_send) # 发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send) # 发送某个键到指定元素
7.1 鼠标点击
示例网址:https://sahitest.com/demo/clicks.htm
'''
功能如下:
1. 实现左键单击操作
2. 实现左键双击操作
3. 实现右键单击操作
'''
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome() # 初始化浏览器对象
try:
browser.maximize_window() # 窗口最大化
browser.get('http://sahitest.com/demo/clicks.htm')
time.sleep(0.5)
click_btn = browser.find_element(By.XPATH, '//input[@value="click me"]') # 单击按钮
doubleclick_btn = browser.find_element(By.XPATH, '//input[@value="dbl click me"]') # 双击按钮
rightclick_btn = browser.find_element(By.XPATH, '//input[@value="right click me"]') # 右键单击按钮
ActionChains(browser).click(click_btn).double_click(doubleclick_btn).context_click(rightclick_btn).perform() # 链式用法,执行动作链
time.sleep(0.5)
textarea = browser.find_element(By.XPATH, '//textarea[@name="t2"]').get_attribute('value') # 获取textarea文本域中的值
print(textarea)
finally:
time.sleep(3)
browser.quit()
7.2 鼠标移动
示例网址:https://sahitest.com/demo/mouseover.htm
'''
功能如下:
解决某些hover的问题
'''
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome() # 初始化浏览器对象
try:
browser.maximize_window() # 窗口最大化
browser.get('https://sahitest.com/demo/mouseover.htm')
time.sleep(0.5)
write = browser.find_element(By.XPATH, '//input[@value="Write on hover"]') # Writer on hover
black = browser.find_element(By.XPATH, '//input[@value="Blank on hover"]') # Blank on hover
action = ActionChains(browser)
action.move_to_element(write).perform() # 将鼠标移动到Writer on hover
time.sleep(2)
action.move_to_element(black).perform() # 将鼠标移动到Blank on hover
finally:
time.sleep(3)
browser.quit()
7.3 鼠标拖拽
示例网址:https://sahitest.com/demo/dragDropMooTools.htm
'''
功能如下:
实现鼠标将某一个元素拖拽到另一个元素中
'''
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome() # 初始化浏览器对象
try:
browser.maximize_window() # 窗口最大化
browser.get('https://sahitest.com/demo/dragDropMooTools.htm')
time.sleep(0.5)
dragger = browser.find_element(By.ID, 'dragger') # dragger
items = browser.find_elements(By.XPATH, '//div[@class="item"]') # items
action = ActionChains(browser)
action.drag_and_drop(dragger, items[0]).perform() # 将drop拖拽到第一个item中
time.sleep(2)
action.drag_and_drop(dragger, items[2]).perform() # 将drop拖拽到第三个item中
time.sleep(2)
action.drag_and_drop(dragger, items[-1]).perform() # 将drop拖拽到第四个item中
finally:
time.sleep(3)
browser.quit()
7.4 按键监听
示例网址:http://sahitest.com/demo/keypress.htm
'''
功能如下:
在selenium中实现键盘的简易操作
'''
import time
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.maximize_window()
browser.get('http://sahitest.com/demo/keypress.htm')
key_up_radio = browser.find_element(By.ID, 'r1') # 监测按键升起
key_down_radio = browser.find_element(By.ID, 'r2') # 监测按键按下
key_press_radio = browser.find_element(By.ID, 'r3') # 监测按键按下升起
enter = browser.find_elements(By.XPATH, '//form[@name="f1"]/input')[1] # 输入框
result = browser.find_elements(By.XPATH, '//form[@name="f1"]/input')[0] # 监测结果
# 监测key_down
key_down_radio.click()
ActionChains(browser).key_down(Keys.CONTROL, enter).key_up(Keys.CONTROL).perform() # 在输入框中按下ctrl建
print(result.get_attribute('value'))
time.sleep(5)
# 监测key_up
key_up_radio.click()
enter.click()
ActionChains(browser).key_down(Keys.SHIFT).key_up(Keys.SHIFT).perform() # 在输入框中按下shift建,松开
print(result.get_attribute('value'))
time.sleep(5)
# 监测key_press
key_press_radio.click()
enter.click()
ActionChains(browser).send_keys('a').perform()
print(result.get_attribute('value'))
time.sleep(5)
browser.quit()
8、执行JavaScript脚本
- execute_script():可以直接模拟运行JavaScript,常见的几种执行场景如下:
- 将滚动条拉至顶部
- 将滚动条拉至底部
- 直接使用js操作页面,能解决很多click()不生效的问题
- 处理富文本,时间控件的输入
代码如下:
'''
功能如下:
- 将滚动条拉至顶部
- 将滚动条拉至底部
- JS执行元素操作(点击、输入文本、等)
'''
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.maximize_window()
browser.get('https://movie.douban.com/chart')
time.sleep(2)
# driver.execute_script("arguments[0].click();", element),点击操作
# driver.execute_script("arguments[0].scrollIntoView();", element),移动到目标元素,类似于滑动查找
# 滚动条拉到底部
js = 'window.scrollTo(0, document.body.scrollHeight)'
browser.execute_script(js)
print(f'''滚动条滑动到底部''')
time.sleep(2)
# 滚动条拉到顶部
js = 'window.scrollTo(0, 0)'
browser.execute_script(js)
print(f'''滚动条滑动到顶部''')
time.sleep(2)
# 输入文本操作
msg = '悬疑'
send_js = f"text_input = document.getElementById('inp-query'); " \
f"text_input.value = '{msg}'"
browser.execute_script(send_js)
print(f'''{msg}文本输入成功。。。''')
time.sleep(2)
# 点击操作
input_btn = browser.find_element(By.CSS_SELECTOR, ".inp-btn input")
click_js = 'arguments[0].click();'
browser.execute_script(click_js, input_btn)
print(f'''搜索按钮点击成功''')
# 创建一个新的选项卡
browser.execute_script('window.open()')
handles = browser.window_handles # 获取当前浏览器对象中有多少选项卡
print(handles)
browser.switch_to.window(handles[-1]) # 跳转到最后一个选项卡中
browser.get('https://www.taobao.com') # 跳转至淘宝中
time.sleep(3)
browser.quit()
9、获取节点信息
-
page_source属性可以获取网页的源代码,也可以使用解析库(如正则表达式、BeautifulSoup、pyquery、parsel等)来提取信息
-
Selenium已经提供了选择节点的方法,返回的是WebElement类型,那么它也有相关的方法和属性来直接提取节点信息,如属性、文本等。这样的话,我们就可以不用通过解析源代码来提取信息了,非常方便。
get_attribute():获取节点的属性,但是其前提是先选中这个节点,示例如下:
from selenium import webdriver import time from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.maximize_window() browser.get('https://movie.douban.com/chart') time.sleep(2) items = browser.find_elements(By.XPATH, '//div[@class="pl2"]/a[1]') for item in items: print(item.get_attribute('href')) # 获取节点属性href time.sleep(2) browser.quit() # 运行效果 # https://movie.douban.com/subject/30314848/ # https://movie.douban.com/subject/27199850/ # https://movie.douban.com/subject/35874097/ # https://movie.douban.com/subject/35008440/ # https://movie.douban.com/subject/34861178/ # https://movie.douban.com/subject/30165311/ # https://movie.douban.com/subject/35769174/ # https://movie.douban.com/subject/35307624/ # https://movie.douban.com/subject/35303842/ # https://movie.douban.com/subject/35441573/text:获取文本值,每个WebElement节点都有text属性,直接调用这个属性就可以得到节点内部的信息,示例如下:
from selenium import webdriver import time from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.maximize_window() browser.get('https://movie.douban.com/chart') time.sleep(2) items = browser.find_elements(By.XPATH, '//div[@class="pl2"]/a[1]') for item in items: print(item.text) # 获取文本数据 time.sleep(2) browser.quit() # 运行结果 # 瞬息全宇宙 / 妈的多重宇宙(台) / 奇异女侠玩救宇宙(港) # 暗夜博士:莫比亚斯 / 莫比亚斯 / 魔比煞(港) # 网络炼狱:揭发N号房 / 网路炼狱:揭发N号房(台) / 网络地狱:N号房现形记 # 唐顿庄园2 / 唐顿庄园电影版2 / 唐顿庄园:全新世代(港/台) # 北欧人 / 北方人(台) # 坏蛋联盟 / 大坏蛋 / 坏家伙 # 万湖会议 / The Conference # 渔港的肉子酱 / 渔港的肉子 / Fortune Favors Lady Nikuko # 迷失之城 / 迷失D城 / Lost City of D # 首尔怪谈 / Urban Myths / Urban Myths: Tooth Wormsid属性:selenium 使用的内部 ID。
location属性:获取节点在页面中的相对位置
tag_name属性:可以获取标签名称
size属性:可以获取节点元素大小''' 功能如下: id属性:selenium 使用的内部 ID。 location属性:获取节点在页面中的相对位置 tag_name属性:可以获取标签名称 size属性:可以获取节点元素大小 ''' from selenium import webdriver import time from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.maximize_window() browser.get('https://movie.douban.com/chart') time.sleep(2) item = browser.find_elements(By.XPATH, '//div[@class="pl2"]/a[1]')[0] print(item.id) # 获取节点在selenium中的id print(item.location) # 获取节点在页面中的位置 print(item.size) # 获取节点的大小 print(item.tag_name) # 获取节点的标签名称 time.sleep(2) browser.quit() # 执行效果 # 8c32db1c-1321-4674-9aee-92abad562603 # {'x': 534, 'y': 281} # {'height': 16, 'width': 318} # a
10、切换iFrame
示例网址:https://sahitest.com/demo/iframesTest.htm
selenium中处理iFrame有三种方式
-
1、如果iframe有id或name,则可根据iframe的id或name切换。
<iframe name="aa"id="x-URS-iframe1610006384373.8518"></iframe> browser.switch_to.frame('x-URS-iframe1610006384373.8518') # id定位 browser.switch_to.frame('aa') # name定位 -
2、把iframe当作页面元素,通过元素定位表达式进行切换。
<iframe name="aa"id="x-URS-iframe1610006384373.8518"></iframe> frame = browser.find_element_by_xpath('//iframe[@id="x-URS-iframe"]') # 先定位元素 browser.switch_to.frame(frame) # 在切换iframe -
3、将iframe存储到list中,然后根据ifrane的索引定位 (适合页面有多个iframe,且前两种方法无法使用)。
browser.switch_to.frame(0) -
返回上一级
browser.switch_to.parent_frame() # 返回上一级 -
跳出iframe窗口并返回到Top Window 上
browser.switch_to_default_conten() # 跳出iframe窗口并返回Window主窗体 -
这里案例只用将元素作为参数传递,进入iframe中。
from selenium import webdriver import time from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.maximize_window() browser.get('https://sahitest.com/demo/iframesTest.htm') time.sleep(2) item = browser.find_element(By.ID, 'checkRecord').get_attribute('value') h2_out = browser.find_element(By.TAG_NAME, 'h2').text print(f'''外层的主体输出:{item}, {h2_out}''') time.sleep(2) # 第一层iframe iframe = browser.find_element(By.TAG_NAME, 'iframe') browser.switch_to.frame(iframe) h2_in = browser.find_element(By.TAG_NAME, 'h2').text print(f'''内层iframe的输出:{h2_in}''') time.sleep(2) browser.quit()
11、延迟等待(显示等待和隐式等待)
-
在selenium中,get()方法会在网页框架加载完之后结束,但是在这时候获取网页源代码page_source,可能并不是浏览器加载完之后的数据,如果某些页面有额外的Ajax请求,我们在网页源代码中也不一定能成功获取到。所以,这里需要延时等待一定时间,确保节点已经加载出来。
-
等待的方式有两种:一种是显示等待,一种是隐式等待
-
隐式等待implicily_wait():当使用隐式执行测试时,如果selenium没有在DOM中找到节点,将继续等待,超出设定时间后则抛出找不到节点的异常。【换句话说,当前查找节点的节点没有立即出现,则进行等待隐式等待设定的时候,再查找DOM节点,默认的隐式等待时间为0】from selenium import webdriver from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.implicitly_wait(10) # 隐式等待10s browser.maximize_window() browser.get('https://movie.douban.com/chart') items = browser.find_elements(By.XPATH, '//div[@class="pl2"]/a[1]') for item in items: print(item.get_attribute('href')) # 获取节点属性href browser.quit() -
显式等待wait = WebDriverWait(browser,10):隐式等待的效果其实没有这么好,隐式等待只是设置固定等待一段时间,而页面会收到网络的影响。有一中更适合的显示等待方法,去处理上述问题,【简单的说,显示等待就是在查找节点时,设置一个最长等待时间,在这个规定的时间内,不断的间隔查找节点是否加载出来,如果加载出来,则返回查找的节点;如果到了规定时间依然没有加载出该节点,则抛出找不到节点的异常】import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC browser = webdriver.Chrome() browser.implicitly_wait(10) # 隐式等待10s browser.maximize_window() browser.get('https://movie.douban.com/chart') item = WebDriverWait(browser, 10).\ until(EC.presence_of_element_located((By.XPATH, '//div[@class="pl2"]'))) print(item) time.sleep(2) browser.quit() # 运行结果 <selenium.webdriver.remote.webelement.\ WebElement (session="21cb0b79ea3b60b9711ae9bb7aab33a5", element="0d6c5acb-9eba-40eb-8075-3655d02b336a")> -
详细操作:文档
| 等待条件 | 含义 |
|---|---|
| title_is | 标题是某内容 |
| title_contains | 标题包含某内容 |
| presence_of_element_located | 节点加载出来,传入定位元组,如(By.ID,‘p’) |
| visibility_of_element_located | 节点可见,传入定位元组 |
| visibility_of | 可见,传入节点对象 |
| presence_of_all_elements_located | 所有节点加载出来 |
| text_to_be_present_in_element | 某个节点文本包含某文字 |
| text_to_be_present_in_element_value | 某个节点值包含某文字 |
| frame_to_be_available_and_switch_to_it | 加载并切换 |
| invisibility_of_element_located | 节点不可见 |
| element_to_be_clickable | 节点可点击 |
| staleness_of | 判断一个节点是否仍在DOM,可判断页面是否已经刷新 |
| element_to_be_selected | 节点可选择,传节点对象 |
| element_located_to_be_selected | 节点可选择,传入定位元组 |
| element_selection_state_to_be | 传入节点对象以及状态,相等返回true,否则返回False |
| element_located_selection_state_to_be | 传入定位元组以及状态,相等返回True,否则返回False |
| alert_is_present | 是否出现警告 |
12、前进与后退
- back():后退
- forward():前进
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.zhihu.com/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
13、Cookies使用
- get_cookies():获取cookies 【列表格式】
- add_cookie(dict):添加cookie【字典格式】
- delete_cookie(name=“”):删除某一个cookie
- delete_all_cookies():删除所有的cookies
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
cookies = browser.get_cookies() # 获取页面的cookie【列表格式】
print(cookies)
time.sleep(1)
browser.add_cookie({'name': 'name', 'domain': '.baidu.com', 'value': 'xuan'}) # 添加cookie
time.sleep(0.5)
print(browser.get_cookies())
time.sleep(0.5)
browser.delete_all_cookies() # 删除所有的cookies
time.sleep(0.5)
print(browser.get_cookies())
browser.close()
# 运行结果
# [{'domain': '.baidu.com', 'expiry': 1685068239, 'httpOnly': False, 'name': 'ZFY', 'path': '/', 'sameSite': 'None', 'secure': True, 'value': '6L4XyME:AUQ:AgwiMtufstx4tSWgLYItHOAIkkYt6HSMo:C'}, {'domain': '.baidu.com', 'expiry': 1653618639, 'httpOnly': False, 'name': 'BA_HECTOR', 'path': '/', 'secure': False, 'value': '8cak8121ah252lela01h8tpif15'}, {'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '36454_31253_36452_36421_36165_36488_36055_26350_36301_36469_36311_36447'}, {'domain': '.baidu.com', 'expiry': 1685068238, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'secure': False, 'value': 'C0B5A9B5DBE343265E238C99CE101CAC:FG=1'}, {'domain': '.baidu.com', 'expiry': 3801015885, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': 'C0B5A9B5DBE3432620590E72CBC92B05'}, {'domain': '.baidu.com', 'expiry': 3801015885, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1653532239'}, {'domain': 'www.baidu.com', 'expiry': 1654396239, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'secure': False, 'value': '12314753'}, {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '1'}]
# [{'domain': '.baidu.com', 'expiry': 1685068239, 'httpOnly': False, 'name': 'ZFY', 'path': '/', 'sameSite': 'None', 'secure': True, 'value': '6L4XyME:AUQ:AgwiMtufstx4tSWgLYItHOAIkkYt6HSMo:C'}, {'domain': '.baidu.com', 'expiry': 1653618639, 'httpOnly': False, 'name': 'BA_HECTOR', 'path': '/', 'secure': False, 'value': '8cak8121ah252lela01h8tpif15'}, {'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '36454_31253_36452_36421_36165_36488_36055_26350_36301_36469_36311_36447'}, {'domain': '.baidu.com', 'expiry': 1685068238, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'secure': False, 'value': 'C0B5A9B5DBE343265E238C99CE101CAC:FG=1'}, {'domain': '.baidu.com', 'httpOnly': False, 'name': 'name', 'path': '/', 'secure': True, 'value': 'xuan'}, {'domain': '.baidu.com', 'expiry': 3801015885, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': 'C0B5A9B5DBE3432620590E72CBC92B05'}, {'domain': '.baidu.com', 'expiry': 3801015885, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1653532239'}, {'domain': 'www.baidu.com', 'expiry': 1654396239, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'secure': False, 'value': '12314753'}, {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '1'}]
# []
- 这里增加一个扩展功能,比如selenium的Cookies转换成字符串Cookie可以给requests使用,又或者requests的Cookie字符串转换成selenium可使用的list格式Cookies。
# 网页中的cookie转换成selenium使用的cookie
def cookie_seleinium(cookieStr, domain):
'''
将requests拿到的cookie转换成selenium使用的cookie
:param cookieStr: cookie
:param domain: 填入统一的domin域名
:return:
'''
cookie_list = cookieStr.split(';')
selenium_cookie_list = []
for cookie in cookie_list:
# print(cookie)
# print(cookie.split('=', 1))
cookie = cookie.strip()
name = cookie.split('=', 1)[0]
value = cookie.split('=', 1)[-1]
cookie_dict = {
"domain": domain,
"name": name,
"value": value,
"path": "/"
}
selenium_cookie_list.append(cookie_dict)
return selenium_cookie_list
# selenium获取cookie可转成requests使用的cookie
def selenium_requests_cookie(selenium_list):
#获取cookies
cookie_list = [item["name"] + "=" + item["value"] for item in selenium_list]
cookieStr = ';'.join(item for item in cookie_list)
return cookieStr
14、选项卡管理(切换句柄)
- 获取当前句柄:
browser.current_window_handle - 获取所有句柄:
hanles = browser.window_handles - 切换指定句柄:
handle = handles[-1] # 取最新窗口的idbrowser.switch_to.window(handle) # 切换窗口 - 访问网页的时候,很多时候我们点击一个链接时,会新建一个选项卡,那么如何跳转至新打开的选项卡呢?就需要用到switch_to.window(handle)方法去跳转,以下代码会做一个小案例。
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 调用execute_script()方法,传入window.open()这个javascript语句新开启一个选项卡
browser.execute_script('window.open()')
# 获取当前开启的所有选项卡,返回的是选项卡的代号列表
print(browser.window_handles)
# 调用switch_to.window()方法切换选项卡,参数是选项卡代号,跳转到最后一个,选项卡中序号默认从0开始
browser.switch_to.window(browser.window_handles[-1])
browser.get('https://www.taobao.com')#打开淘宝页面
time.sleep(1)
browser.switch_to.window(browser.window_handles[0])#跳转到第一个选项卡
browser.get('https://douban.com')
time.sleep(1)
browser.quit()
# 运行结果:
# ['CDwindow-AD42B99E578AAAFBD39CE0B27261CEFB', 'CDwindow-A06ACF8B3CABE2F92782552A95C36071']
15、异常处理
- 在使用selenium时,会经常遇到一些报错哦异常。例如:超时异常、节点未找到等报错异常,一旦出现这种异常,程序就会停止执行,这时我们可以使用try···except语句来实现捕获异常进行处理。
- 更多异常类:文档
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,NoSuchElementException
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element_by_id('hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()
# 运行结果
# No Element
16、浏览器退出
- browser.close():关闭浏览器的一个标签页
- browser.quit():关闭浏览器
17、截图操作
-
在linux中,使用selenium进行截图,需要安装中文库,否则中文会变成方框。 -
Selenium截图有大的两个方式,一个是针对于浏览器而言,另一种是针对与元素而言
-
针对于浏览器对象browser而言,有四种截图方式
- driver.get_screenshot_as_base64():以 base64 编码字符串形式获取当前窗口的屏幕截图,在HTML界面输出截图时使用。
- driver.get_screenshot_as_png():以二进制数据形式获取当前窗口的屏幕截图。
- driver.save_screenshot(filename/full_path):获取截屏png图片,参数是文件名称,截屏必须是.png图片, 如果只给文件名,截图会保存在项目的根目录下面。
- driver.get_screenshot_as_file(filename/full_path):获取截屏png图片,参数是文件的绝对路径,截屏必须是.png图片。如果只给文件名,截屏会存在项目的根目录下。
import time from selenium import webdriver from selenium.webdriver.common.by import By def save_screenshot_demo(): ''' 获取截屏png图片,参数是文件名称,截屏必须是.png图片, 如果只给文件名,截图会保存在项目的根目录下面。 :return: ''' try: browser.get('https://www.baidu.com') browser.find_element(By.LINK_TEXT, '新闻').click() time.sleep(3) browser.switch_to.window(browser.window_handles[-1]) browser.save_screenshot('save_screenshot_demo.png') # save_screenshot的图片数据必须以png结尾 finally: time.sleep(3) browser.quit() def get_screenshot_as_file_demo(): ''' 获取截屏png图片,参数是文件的绝对路径,截屏必须是.png图片。如果只给文件名,截屏会存在项目的根目录下。 :return: ''' try: browser.get('https://www.baidu.com') browser.find_element(By.LINK_TEXT, '新闻').click() time.sleep(3) browser.switch_to.window(browser.window_handles[-1]) browser.get_screenshot_as_file('get_screenshot_as_file_demo.png') # get_screenshot_as_file的图片数据必须以png结尾 finally: time.sleep(3) browser.quit() def get_screenshot_as_base64_demo(): ''' 以 base64 编码字符串形式获取当前窗口的屏幕截图,在HTML界面输出截图时使用。 :return: ''' try: browser.get('https://www.baidu.com') browser.find_element(By.LINK_TEXT, '新闻').click() time.sleep(3) browser.switch_to.window(browser.window_handles[-1]) b64 = browser.get_screenshot_as_base64() print(b64) finally: time.sleep(3) browser.quit() def get_screenshot_as_png_demo(): ''' 以二进制数据形式获取当前窗口的屏幕截图。 :return: ''' try: browser.get('https://www.baidu.com') browser.find_element(By.LINK_TEXT, '新闻').click() time.sleep(3) browser.switch_to.window(browser.window_handles[-1]) b_data = browser.get_screenshot_as_png() print(b_data) finally: time.sleep(3) browser.quit() -
针对于元素而言
- element.screenshot(save_file_path):针对某一个元素进行截图,并报错到相对的路径文件
from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as ec from selenium.webdriver.support.wait import WebDriverWait import random def selenium_screenshot(url, css_element: str, width=None, height=None, file_name=None): """ 快照截图(截图某个元素) :param url: url :param width: 窗口宽度 :param height: :param css_element: css定位 :return: """ ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36" driver = "" ip = '' # ip = "xxx.xxx.xxx.xxx" try: chrome_options = Options() chrome_options.add_argument('--headless') # 无头模式 chrome_options.add_argument('--disable-gpu') # 禁用gpu chrome_options.add_argument('--no-sandbox') chrome_options.add_argument(f'user-agent={ua}') # 添加UA if ip: chrome_options.add_argument(f'--proxy-server=http://{ip}:port"') driver = webdriver.Chrome(options=chrome_options) driver.maximize_window() if width: driver.set_window_size(width, height) driver.get(url) wait = WebDriverWait(driver, 10) wait.until(ec.presence_of_element_located((By.CSS_SELECTOR, css_element))) ele = driver.find_element(By.CSS_SELECTOR, css_element) except Exception as err: print(f"{url} selenium_screenshot false: {err} ") return else: if not file_name: file_name = random.random() save_file_path = f"{file_name}.png" ele.screenshot(save_file_path) print(f"selenium_screenshot success {url}") return save_file_path finally: if driver: driver.quit()
18、Selenium项目模板
这里给大家分享一个我自己常用的Selenium脚本执行的模板。
import time
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.support.wait import WebDriverWait
from tenacity import retry, stop_after_attempt
TIME_OUT = 15 # wait最长等待时间
class Selenium_Chrome(object):
def __init__(self):
# 参数初始化
self.chrome_path = r'' # 指定chrome版本浏览器存放的路径
self.user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
@retry(
stop=stop_after_attempt(3) # 重启三次
)
def start_chrome(self):
'''
Chrome初始化配置对象
:return:
'''
chrome_options = ChromeOptions()
if self.chrome_path: # 如果指定Chrome的版本,就设置这个
chrome_options.binary_location = self.chrome_path
# chrome_options.add_argument("--headless") # 无界面运行
chrome_options.add_argument('accept-language="zh-CN,en-US;q=0.8"')
chrome_options.add_argument(f'''user-agent={self.user_agent}''')
chrome_options.add_experimental_option('useAutomationExtension', False)
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
chrome_options.add_argument('--disable-gpu') # 爬虫的时候,我们一般会选择禁用GPU,如果不禁用,访客GPU都相同,太容易判断了
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument("-incognito") # 设置无痕模式
# 创建Chrome对象
self.browser = Chrome(options=chrome_options)
# 进行简单的规避操作
self.browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
self.browser.maximize_window() # 将窗口最大化
self.wait = WebDriverWait(self.browser, TIME_OUT)
def end_chrome(self):
"""
清除缓存并关闭chrome
"""
time.sleep(3)
self.browser.delete_all_cookies()
self.browser.quit()
def start(self):
try:
self.start_chrome()
'''
这里存放主程序的各种执行函数
'''
self.browser.get('https://www.baidu.com')
finally:
self.end_chrome()
if __name__ == '__main__':
test = Selenium_Chrome()
test.start()
总结
以上便是目前我在selenium中常用的方法以及知识汇总,其中可能还会有欠缺,如果实际操作中,有用到其他的案例,也会继续在这里进行添加。当然如果文章中有不对的地方,欢迎评论区留言进行指导,我会及时更改。在这里非常感谢开头的几篇优质文章作为参考。
















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









