







爬虫目标
本次爬虫需要从知乎的话题精华回答中爬取前1000个回答的问题。然后得到关注数最多的100个问题的url后,到问题主页把问题下的50%的回答内容和作者信息爬取下来。
本次爬虫主要分为四部分:
1.爬取精华回答页面,获取每个回答对应的问题的url。
2.爬取上一步的问题页面获取问题的关注人数、评论数,用来选择最热门问题。
3.爬取热门问题主页的前50%回答内容、回答获得的赞同数、回答时间、回答作者的url等。
4.到作者主页获得回答的作者的一些信息,如,获赞量、评论量、关注人数等。
为方便阅读,本篇讲解第一部分
知乎话题主页数据爬虫
需要用到的包
from urllib.parse import urlencode
import requests
import pymysql
前期准备,base_url是动态加载数据的url的前面不变的部分。在知乎话题主页鼠标右键–>检查(或者Fn+F12)。选择文件类型XHR,查看通过Ajax加载的文件。然后向下滑动时我们看到不断加载出来的文件。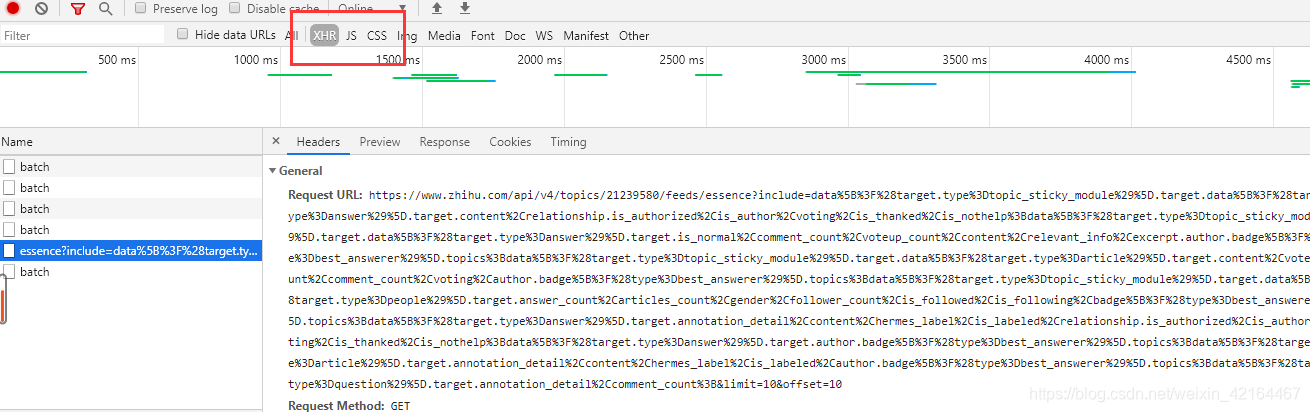
这类文件的格式通常是这样的,我们后面从这个文件中获取数据,需要分析这个结构。
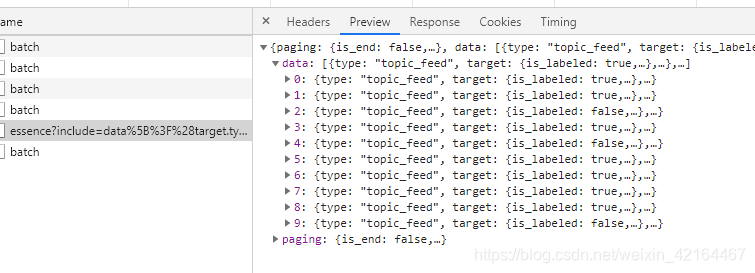
回到,数据包的首部信息。我们需要分析下这个URL的结构。主要是第一部分红色固定部分加上三个量。
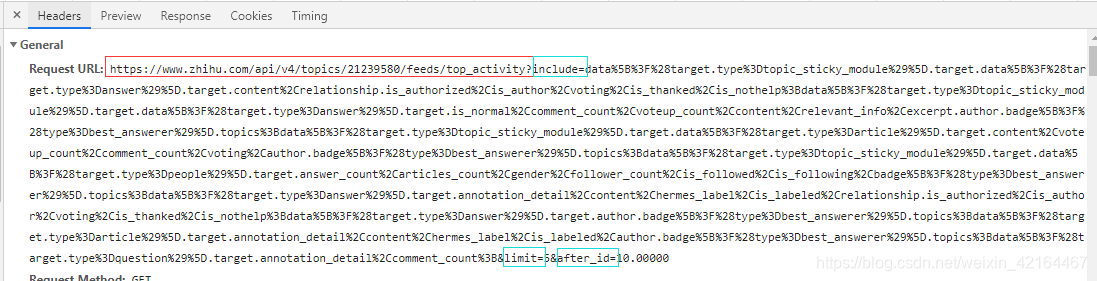
鼠标下滑观察三个量的具体变化情况。
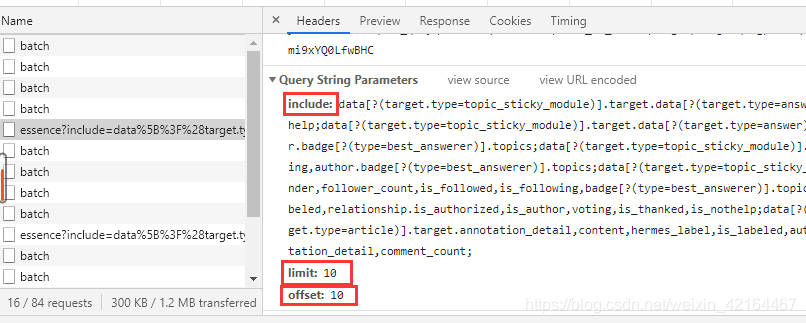
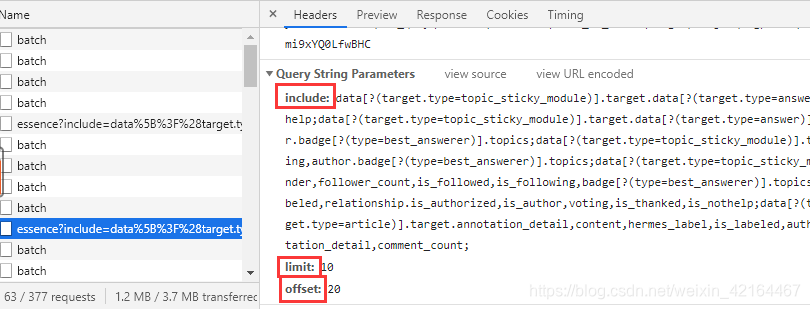
可以发现include、limit是定量,offset递增,每次加10.
然后我们就可以构造爬虫的url了!
base_url就是不变的部分,params字典里将offset设置为变量,offset作为算法的输入参数,借助循环就可以爬取所有的json文件了。
base_url = 'https://www.zhihu.com/api/v4/topics/21239580/feeds/essence?'
#数据包的头部信息完整不容易被反爬
headers = {
'referer': 'https://www.zhihu.com/topic/21239580/top-answers',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'X-Requested-With': 'fetch' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1276
1276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









