








作者 | 天涯泪小武
责编 | 王晓曼
出品 | CSDN博客
前天618大促演练进行了全链路压测,在此之前刚好我的热key探测框架也已经上线灰度一周了,小范围上线了几千台服务器,每秒大概接收几千个key探测,每天大概几亿左右,因为量很小,所以框架表现稳定。借着这次压测,刚好可以检验一下热key框架在大流量时的表现。毕竟作为一个新的中间件,里面很多东西还是第一次用,免不得会出一些问题。
压测期,我没有去扩容热key的worker集群,还是平时用的3个16C+1个4C8G的组合,3个16核是是主力,4核的是看上限能到什么样。
由于之前那一周的平稳表现,导致我有点大意了,没再去好好检查代码。导致实际压测期间表现有点惨淡。
框架的架构如下:
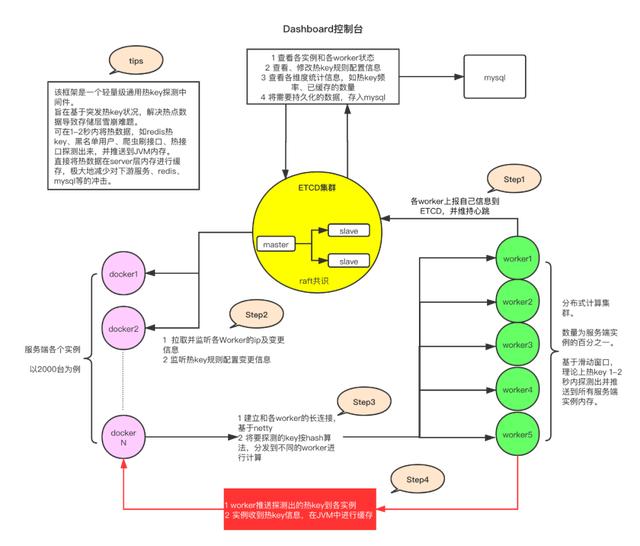
大概0点多压测开始,初始量比较小,从10w/s开始压,当然都是压的APP的后台,我的框架只是被动的接收后台发来的热key探测请求而已。我主要检测的就是worker集群,也就是那4台机器的情况。
从压测开始的一瞬间,那台4核8G的机器就CPU100%,16核的CPU在90%以上,4核的100%即便在压测暂停的间隙也没有恢复,一直都是100%,无论是10w/s,还是后期到大几十万/s。16核的在20w/s以上时也开始CPU100%,整体卡到不行了已经,连10秒一次的定时任务都卡的不走了,导致定时注册自己到etcd的任务都停了,再导致etcd里把自己注册信息过期删除,大量和Client断连。
然后Dashboard控制台监听etcd热key信息的监听器也出了大问题,热key产生非常密集,导致Dashboard将热key入库卡顿,甚至于入库时,都已经过期1分钟多了,导致插入数据库的时间全部是错的。
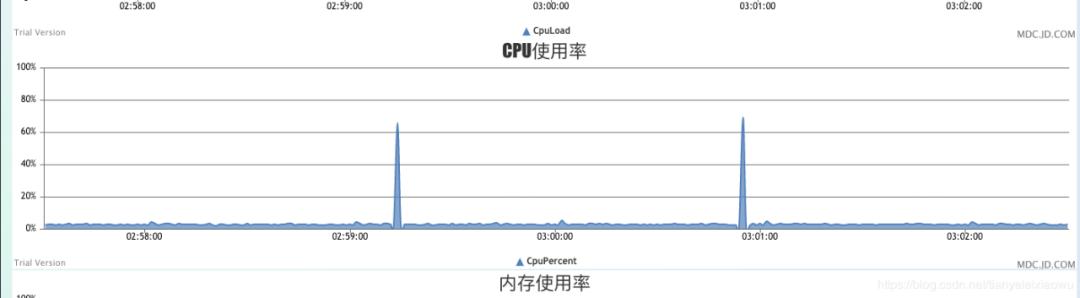
虽然Worker问题蛮多,也蛮严重,但好在etcd集群稳如老狗,除了1分钟一次的热key密集过期导致CPU有个小尖峰,别的都非常稳定,接收、推送都很稳,Client端表现也可以,没有什么异常表现。
其中etcd真的很不错,比想象中的更好,有图为证:
Worker呢就是这样子
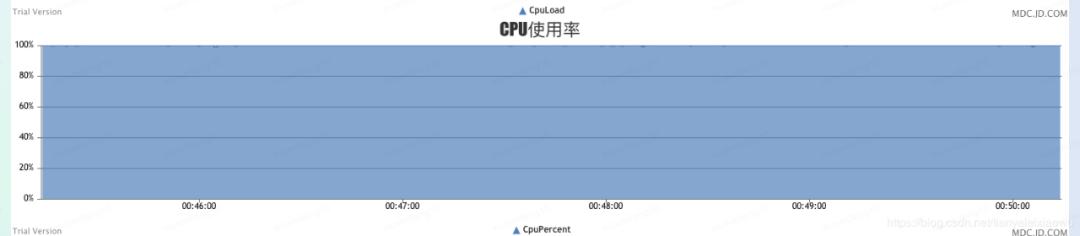
后来经过一系列操作,我还乐观的修改上线了一版,然后没什么用,在100%上稳的一匹。
后来经过我一天的研究分析,发现
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5164
5164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









