






并发,这个对于所有java开发来说都是一个耳熟能详的词汇,在时下大流量的冲击下,并发是一种趋势,驱使着各种新技术、新架构的诞生,时下最应景而生的技术则属缓存(例如redis、memcached),消息中间件(ActiveMq,Kafka等),微服务在架构中也必然有一席之地,这些上层建筑固然重要,但是地基更是不容小觑,随着工作年限的增长,经验逐渐的积累,在并发下处理名称重复总结以下几点
Redis序列
使用过Redis的小伙伴一定都知道,Redis的incr功能,其介绍如下
incr用法,当key不存在时,先创建该key,然后给该key设置默认值为零,然后再给该key加一 ,如果该key不是一个数值,将报错
利用这点我们就可以设置一个键值,例如2019082500000000,然后使用incr关键值给该值依次递增一,并且redis是操作缓存,速度较快,不占用内存

Redis命令操作过程
Java自带的UUID
Java开发应该都知道Java有个自带的生成不重复的36位字符串,但是中间常用会包含四个横杠,所以我们经常需要将其横杠替换掉得到一个32位不重复的字符串,利用这种不重复的字符串加上文件名同样可以防止名称重复,导致数据不一致的问题,(idea实在太重了,电脑带不动,就手写了一个java程序)
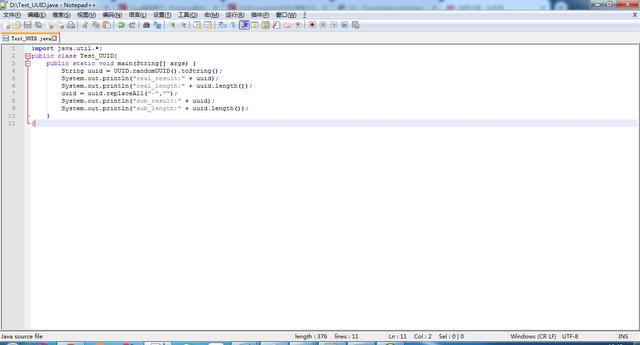
生成的UUID以及截取后的UUID
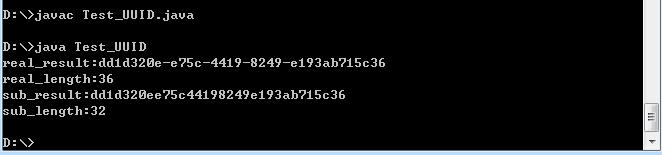
生成结果
时间戳
在java类库中有一个Date对象和目前最新的Calendar对象,都可以用来获取时间戳,利用文件名拼接时间戳的方式也可以避免文件名重复的问题
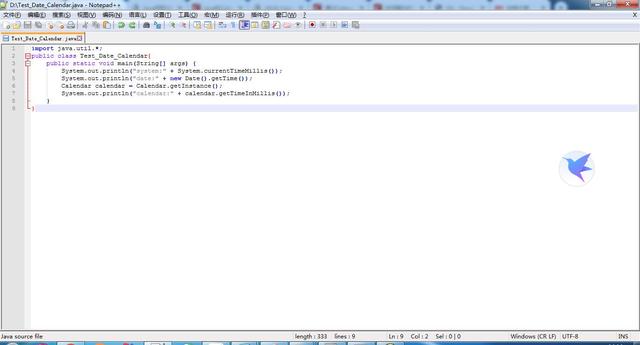
生成时间戳的方式

生成结果
从耗时来看,操作基本数据类型,比操作对象要耗时的多,之前就是在做数据运算的时候,因为当时想到BigDecimal能够做精确运算可能会让结果更加准确些,但是实际上结果本来就是求近似值,所以当时改用double计算就快很多















 2679
2679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









