







数组简介
如果各位猿友是一路跟着LZ看到这里的,那么数组的定义就非常简单了,它就是一个相同数据类型的数据集合。数组存储在一系列逻辑上连续的内存块当中,之所以说是逻辑上连续,是因为整个内存或者说存储器本身就是逻辑上连续的一个大内存数组。如果我们用Java语言的类型来表示我们的存储器的话,可以看做是byte[] memory这样的类型。
数组的定义非常简单,它遵循以下这样简单的规则。
T N[L];
这当中T表示数据类型,N是变量名称,L是数组长度。这样的声明会做两件事,首先是在内存当中开辟一个长为L*length(T)的内存空间(其中length(T)是指数据类型的字节长度),然后将这块内存空间的起始地址赋给变量N。当我们使用N[index]去读取数组元素的时候,我们会去读N+index*length(T)的内存位置,这一点并不难理解。
指针操作数组
在C语言当中,*符号可以取一个指针指向的内存区域的值,而对于数组来说,*符号依然可以这样做。因此,我们可以很轻松地想到,对于上面的声明来说,*N就相当于N[0],类似的,*(N+1)就相当于N[1],以此类推。
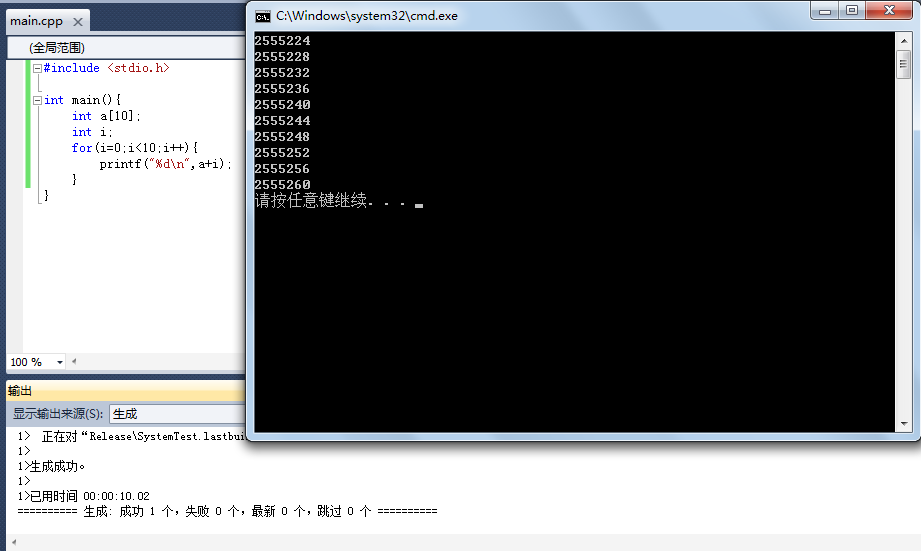
在上面*(N+1)这样的方式当中,我们其实对指针进行了运算,即对数组的起始地址N加了上1。在这一过程中,编译器会帮我们自动乘上数据类型的长度(比如int为4),如此一来,我们的指针运算才算是正确了,比如对于*(N+1)来说,假设T为int类型,则 【实际地址(N+1)】 = N + 1 * 4。对于这一点,我们可以用以下这个小程序来验证一下,从这个程序可以很明显的看出来,当我们对指针进行加1操作的时候,实际的地址会被乘以数据类型的长度。
定长和变长数组
要理解定长和变长数组,我们必须搞清楚一个概念,就是说这个“定”和“变”是针对什么来说的。在这里我们说,这两个字是针对编译器来说的,也就是说,如果在编译时数组的长度确定,我们就称为定长数组,反之则称为变长数组。
比如上图当中的示例,就是一个定长数组,它的长度为10,它的长度在编译时已经确定了,因为长度是一个常量。之前的C编译器不允许在声明数组时,将长度定义为一个变量,而只能是常量,不过当前的C/C++编译器已经开始支持动态数组,但是C++的编译器依然不支持方法参数。另外,C语言还提供了类似malloc和calloc这样的函数动态的分配内存空间,我们可以将返回结果强转为想要的数组类型。
接下来,LZ和各位一起分析一个有关数组的C程序,我们先来一个简单的,也就是一个定长数组,我们看下在汇编级别是如何操作定长数组的。需要一提的是,由于数组的长度固定,所以有的时候编译器会根据实际情况作出一些优化,以下是一个简单的小程序。
int main(){
int a[5];
int i,sum;
for(i = 0 ; i < 5; i++){
a[i] = i * 3;
}
for(i = 0 ; i < 5; i++){
sum += a[i];
}
return sum;
}
以上这个小程序的功能LZ就不介绍了,如果哪位猿友看不懂,请自觉面壁吧。下面我们来看下-S和-O1下的汇编代码,如下所示。
main:
pushl %ebp
movl %esp, %ebp//到此准备好栈帧
subl $32, %esp//分配32个字节的空间
leal -20(%ebp), %edx//将帧指针减去20赋给%edx寄存器?为什么?你能猜到吗?
movl $0, %eax//将%eax设置为0,这里的%eax寄存器是重点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7732
7732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









