







引自:http://shiyanjun.cn/archives/942.html
HDFS是一个分布式文件系统,在HDFS上写文件的过程与我们平时使用的单机文件系统非常不同,从宏观上来看,在HDFS文件系统上创建并写一个文件,流程如下图(来自《Hadoop:The Definitive Guide》一书)所示:
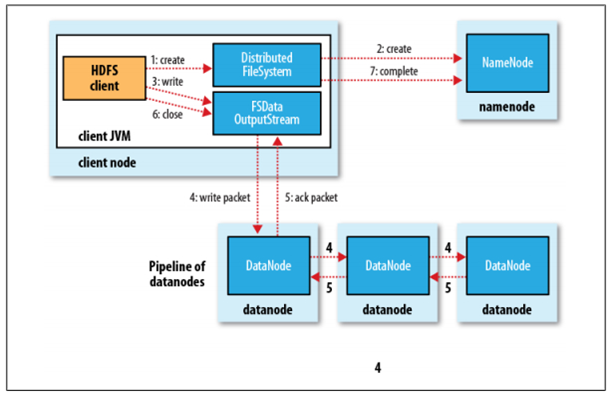
具体过程描述如下:
Client调用DistributedFileSystem对象的create方法,创建一个文件输出流(FSDataOutputStream)对象
通过DistributedFileSystem对象与Hadoop集群的NameNode进行一次RPC远程调用,在HDFS的Namespace中创建一个文件条目(Entry),该条目没有任何的Block
通过FSDataOutputStream对象,向DataNode写入数据,数据首先被写入FSDataOutputStream对象内部的Buffer中,然后数据被分割成一个个Packet数据包
以Packet最小单位,基于Socket连接发送到按特定算法选择的HDFS集群中一组DataNode(正常是3个,可能大于等于1)中的一个节点上,在这组DataNode组成的Pipeline上依次传输Packet
这组DataNode组成的Pipeline反方向上,发送ack,最终由Pipeline中第一个DataNode节点将Pipeline ack发送给Client
完成向文件写入数据,Client在文件输出流(FSDataOutputStream)对象上调用close方法,关闭流
调用DistributedFileSystem对象的complete方法,通知NameNode文件写入成功
下面代码使用Hadoop的API来实现向HDFS的文件写入数据,同样也包括创建一个文件和写数据两个主要过程,代码如下所示:
01
static String[] contents = new String[] {
02
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa",
03
"bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb",
04
"cccccccccccccccccccccccccccccccccccccccccccccccccccccccccc",
05
"dddddddddddddddddddddddddddddddd",
06
"eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee",
07
};
08
09
public static void main(String[] args) {
11
Path path = new Path(file);
12
Configuration conf = new Configuration();
13
FileSystem fs = null;
14
FSDataOutputStream output = null;
15
try {
16
fs = path.getFileSystem(conf);
17
output = fs.create(path); // 创建文件
18
for(String line : contents) { // 写入数据
19
output.write(line.getBytes("UTF-8"));
20
output.flush();
21
}
22
} catch (IOException e) {
23
e.printStackTrace();
24
} finally {
25
try {
26
output.close();
27
} catch (IOException e) {
28
e.printStackTrace();
29
}
30
}
31
}
结合上面的示例代码,我们先从fs.create(path);开始,可以看到FileSystem的实现DistributedFileSystem中给出了最终返回FSDataOutputStream对象的抽象逻辑,代码如下所示:
1
public FSDataOutputStream create(Path f, FsPermission permission,
2
boolean overwrite,
3
int bufferSize, short replication, long blockSize,
4
Progressable progress) throws IOException {
5
6
statistics.incrementWriteOps(1);
7
return new FSDataOutputStream
8
(dfs.create(getPathName(f), permission, overwrite, true, replication, blockSize, progress, bufferSize), statistics);
9
}
上面,DFSClient dfs的create方法中创建了一个OutputStream对象,在DFSClient的create方法:
01
public OutputStream create(String src,
02
FsPermission permission,
03
boolean overwrite,
04
boolean createParent,
05
short replication,
06
long blockSize,
07
Progressable progress,
08
int buffersize
09
) throws IOException {
10
... ...
11
}
创建了一个DFSOutputStream对象,如下所示:
1
final DFSOutp
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









