






1、关于Java项目的应用层分层模型
传统的MVC简单易用,但是也有一些缺点:模型层分层太粗,融合了数据处理、业务处理等所有的功能,核心的复杂业务逻辑都放到模型层,导致模型层很乱等。所以比较适应场景:后端业务逻辑简单的服务,比如接口直接提供对数据库增删改查。

对于较为复杂的业务,后端可以分为:表现层controller(可以连接view视图层/也可以是api对外输出约定格式的数据)、逻辑层service(处理业务逻辑)、模型层beanI(entity实体对应数据库中字段)、数据访问层dao(等同mybatis中逆向工程生成mapper层/对数据库持久化操作,主要实现一些增删改查操作),优点是业务逻辑与数据层分离。
2、JDBC的操作流程
JDBC是Java定义的一套和数据库建立连接的规范(接口),那么各家数据库厂商,想要Java去操作各家的数据库,必须实现这套接口,我们把数据库厂商写的这套实现类,称之为数据库驱动。
1)导入数据库的jar包
2)加载驱动jar包
3)获取连接对象
4)获取操作对象
5)开始操作
6)释放资源
这里主要展示常用的DBTUtil数据库资源链接及数据库资源释放代码
package com.www.util;
import java.sql.*;
public class DBUtil {
/**
* 用于链接数据库,得到的结果是数据库的连接对象,链接对象具备了操作数据库的很多功能。=
* @return 链接对象
*/
public static Connection getConn(){
//1. 加载数据库驱动
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
//2. 获取数据库链接
try {
Connection conn = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/springframe?characterEncoding=utf8&useSSL=false","root","123456");
//3. 将链接返回给工具的使用者
return conn;
} catch (SQLException throwables) {
throwables.printStackTrace();
}
return null;
}
/**
* 断开数据库资源的链接,用于释放资源
* @param conn 要释放链接
* @param statement 要释放的执行环境
* @param resultSet 要释放的结果集
*/
public static void close(Connection conn, Statement statement, ResultSet resultSet){
if(conn != null){
try {
conn.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(statement != null){
try {
statement.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(resultSet != null){
try {
resultSet.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
}DAO层的UserBean中的一段展示代码
public class UserDaoImp implements BaseDao<User>{
private static final String SQL_INSERT = "insert into spring_addon_resume_user(name,age,city,address,email,phone,weixin,qq,weibo,sex,description) values(?,?,?,?,?,?,?,?,?,?,?)";
private static final String SQL_FIND_BY_USERID = "select * from spring_addon_resume_user where id=?";
@Override
public int insert(User o) {
//1. 得到链接
Connection conn = DBUtil.getConn();
PreparedStatement state = null;
try {
//2. 得到执行环境
state = conn.prepareStatement(SQL_INSERT, Statement.RETURN_GENERATED_KEYS);
//3. 向执行环境中,填充参数、
state.setString(1,o.getName());
state.setInt(2,o.getAge());
state.setString(3,o.getCity());
state.setString(4,o.getAddress());
state.setString(5,o.getEmail());
state.setString(6,o.getPhone());
state.setString(7,o.getWeixin());
state.setString(8,o.getQq());
state.setString(9,o.getWeibo());
state.setString(10,o.getSex());
state.setString(11,o.getDescription());
//4. 执行
state.executeUpdate();
ResultSet rs = state.getGeneratedKeys();
if(rs.next()){
//5. 将数据的插入结果返回
return rs.getInt(1);
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}finally {
//释放数据库资源
DBUtil.close(conn,state,null);
}
return -1;
}3、其中使用 Statement.getGeneratedKeys() 获得自增键值的注意点
(1)为什么要用 rs.next()?
ResultSet 是带有头结点的结果集,初始时游标指向第一行之前也就是头结点的位置,只是一个标识。如果不使用next()方法将它指向第一行的话,是什么都得不到的。
(2)getInt(1)的作用
getInt() 的参数为columnIndex,即列序号,MySQL 的列序号是从 1 开始的。比如对于下面的表
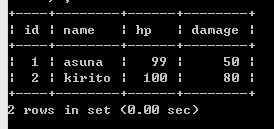
要获得自增主键 id 也就是第 1 列的值,就要使用 getInt(1)。















 253
253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









