






前言:笔者业务场景:当前表无分区,需将数据导出,创建分区后,重新导入当前表;当然,该方法同样使用于普通的数据迁移,或新旧表数据同步(表结构一致)
一、涉及数据量:5470w+
二、导入方式:sqlloader命令导入
1.导入命令
sqlldr oracle用户/oracle密码 control=/data/bak/ht_user.ctl log=/data/bak/ bad=log=/data/bak/ errors=1000;
如下命令
sqlldr unionpay/123456 control=/data/bak/ht_user.ctl log=/data/bak/ bad=/data/bak/ errors=1000
- sqlldr 命令无效,检查自己的oracle客户端是否已安装并配置了环境变量,这里不再赘述;
- ctl文件需事先编辑好,放到对应路径下(格式见第2点);
- log 和bad是用于打印执行日志和错误日志,执行时间和报错信息都会记录下来,可自定义文件名,无则默认同ctl文件名,如ht_user.log ,ht_user.bad ;
- errors=1000 表示可忽略的最多的报错行数,默认50行,超过则会中断执行
- 密码如带有特殊字段,会报错:-bash: !123456@: envent not found
- 命令行密码部分需用单引号,如 '!123456@',执行会提示手动输入用户名和密码
2.ctl文件格式
options(skip=1,ROWS=1000) --跳过第一行,每次提交1000数据
load data
CHARACTERSET UTF8 --导入文件编码
infile '/home/oracle/ht_users.csv' --文件
insert into table "HT_USERS" --表名,必须双引号
fields terminated by ',' --分割符
trailing nullcols --将所有不在纪录中的指定位置的列当作空值
(
TRANS_SEQ,
USER_ACCTNO,
USER_ACCTTYPE,
TRANS_AMT float external,
TRANS_DATE DATE "YYYY-MM-DD hh24:mi:ss",
TRANS_DATETIME TIMESTAMP "YYYY-MM-DD hh24:mi:ss:ff",
USER_CODE,
USER_NAME,
USER_STATE,
USER_PASSWORD
)
- 表字段为普通的字符格式,不需要特别转化
- number类型,需字段后加 float external
- date类型,需加 DATE "YYYY-MM-DD hh24:mi:ss",日期格式根据csv文件实际情况转换
- TIMESTAMP 需加 TIMESTAMP "YYYY-MM-DD hh24:mi:ss:ff" 时间格式根据csv文件实际情况转换
3.实际效率 3小时
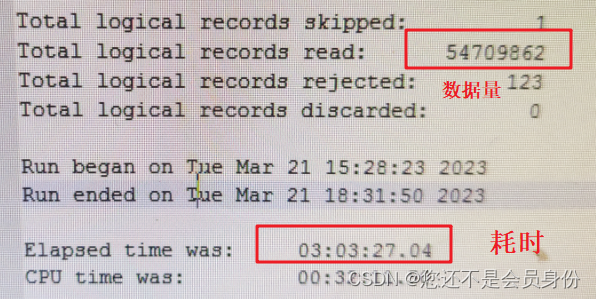
三、据说使用数据泵(expdp/impdp)导出导入dump文件格式效率更高,因笔者没有Root权限,所以没有用该方式;如果简单的数据迁移,也可使用navicat中的数据同步,简单快捷;至于其他导数据的姿势,还没学会,也欢迎评论赐教。














 3167
3167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









