






HubbleDotNet 的查询语法为类 SQL 语句,本文以示例的形式讲述HubbleDotNet 的各种查询方法。随着功能不断的增加,查询方法还会不断补充。
本文给出如下查询方法的示例:
对单个字段按或方式匹配
对单个字段按与方式匹配
对单个字段按部分与,部分或方式匹配
对多个字段匹配并分页
和Untokenized 类型字段组合查询
按多字段排序
在搜索结果中查找
搜索结果中不包含
对单个字段 GROUP BY
同时输出多个字段的Group by统计结果
对多字段组合进行Group by
Group By Limit 设置
同构表联合查询
异构表联合查询
采用UnionSelect 对海量数据分割为小表后联合查询
基本查询
对单个字段按或方式匹配
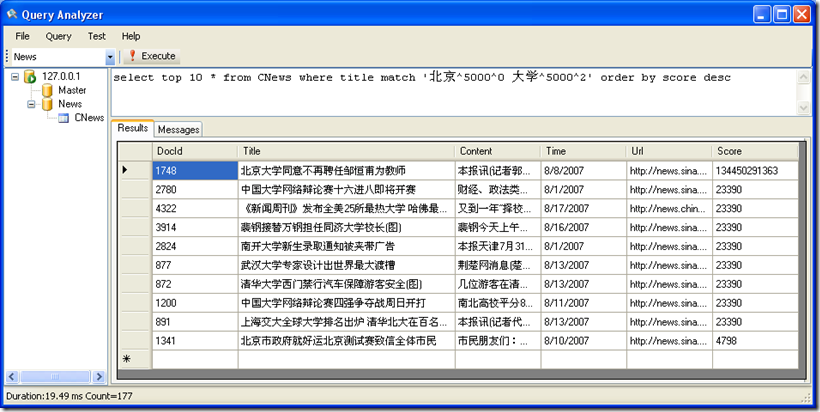
搜索标题中 包含 “北京” “大学” 两个关键字的所有记录,并按照得分的大小排倒序
SQL 语句:select top 10 * from CNews where title match '北京^5000^0 大学^5000^2' order by score desc
单词分量后面跟的参数^5000^0 含义如下
第一个参数表示这个单词分量的权值,这里为5000。
第二个参数表示这个单词分量在输入的被搜索的句子中的其实位置,如这里“北京”的位置为0,大学的起始位置为 2.
top 10 表示输出前10条匹配的记录
Score 为得分,这个是一个动态字段。
结果:
对单个字段按与方式匹配
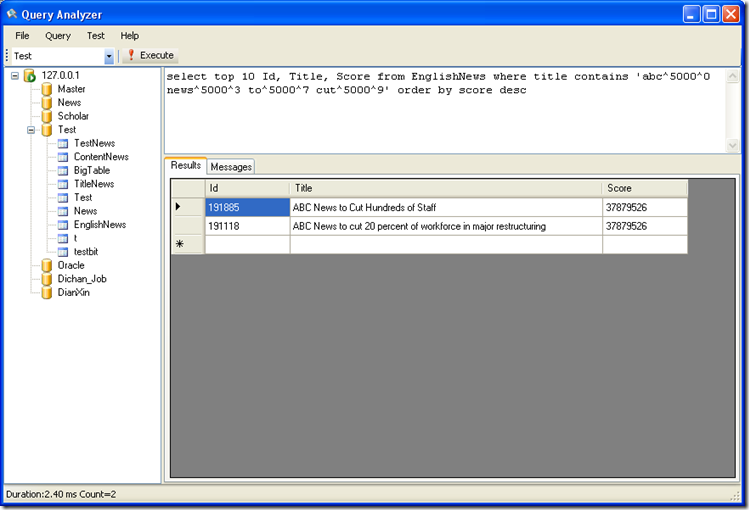
搜索标题包含 abc news to cut 这几个关键字中所有关键字的记录,并按匹配度排序
SQL 语句:select top 10 Id, Title, Score from EnglishNews where title contains 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9'order by score desc
采用 Contains 搜索,可以进行精确匹配,这里我们发现采用 Contains 搜索出来的数据要比 Match 少很多。因为只有
同时包含abc news to cut 这四个单词的记录才会被输出出来。
结果:
对单个字段按部分与,部分或方式匹配
上面的例子,由于 to 这个词太常见,我们希望匹配同时包含 abc news cut 这三个单词的记录,并且记录中如果包含 to ,
则得分比不包含to 的得分高。这种搜索方法已经很解决 google 或 baidu 的搜索方法了,google 中如果输入关键字中包含停用词,
对非停用词采用与的方式匹配,对停用词采用或的方式匹配,但如果记录中包含要匹配的停用词,则得分比不包含的要高。
SQL 语句:select top 10 Id, Title, Score from EnglishNews where title contains 'abc^5000^0 news^5000^3 to^5000^7^1 cut^5000^9' order by score desc
这里我们看出,多出了一条记录,这条记录排在第三位,和前两条记录比起来,这条记录没有 to 这个单词。
to 这个单词分量后面跟的参数说明:
to^5000^7^1
前两个参数和其他单词的意思一样,一个为权重,一个为位置。
第三个参数为标志字段,1 表示可以为或。结果:
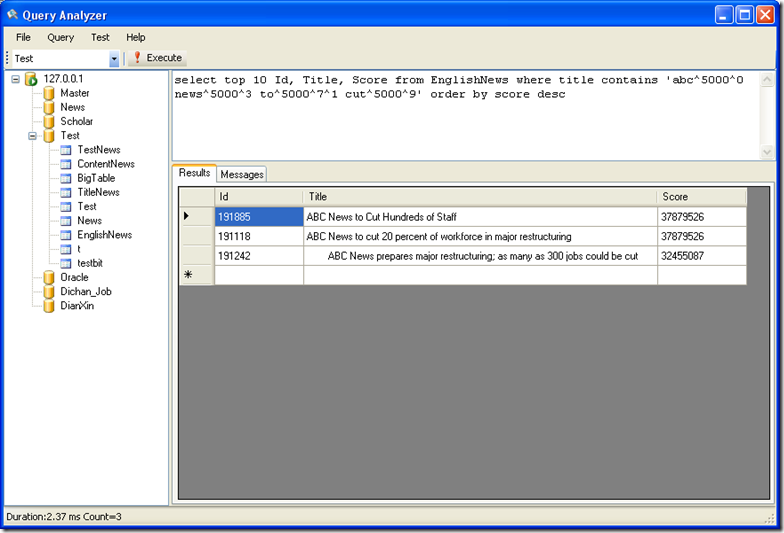
对多个字段匹配并分页
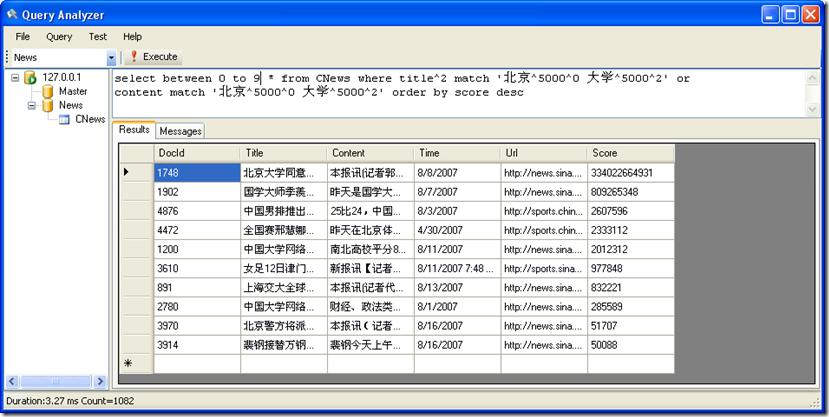
搜索标题或内容中 包含 “北京” “大学” 两个关键字的所有记录,并按照得分的大小排倒序
SQL 语句:select between 0 to 9 * from CNews where title^2 match '北京^5000^0 大学^5000^2' or
content match '北京^5000^0 大学^5000^2' order by score desc
这里 title 字段后跟了一个参数2,这个参数表示 title 字段的权值为2,也就是说通过这种方法对字段设置权值。
between 0 to 9 表示输出 0 到 9 范围内的记录,这种方法可以用于分页显示。
结果:
和Untokenized 类型字段组合查询
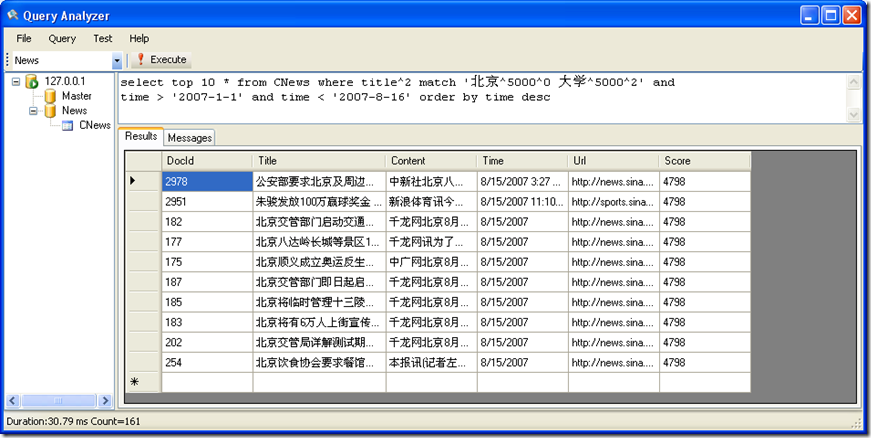
搜索标题中 包含 “北京” “大学” 两个关键字的,并且时间大于 2007 年 1月 1日 小于 2007 年8 月16 日的所有记录,并按照时间排倒序
SQL 语句:select top 10 * from CNews where title^2 match '北京^5000^0 大学^5000^2' and time > '2007-1-1' and
time < '2007-8-16' order by time desc
结果:
按多字段排序
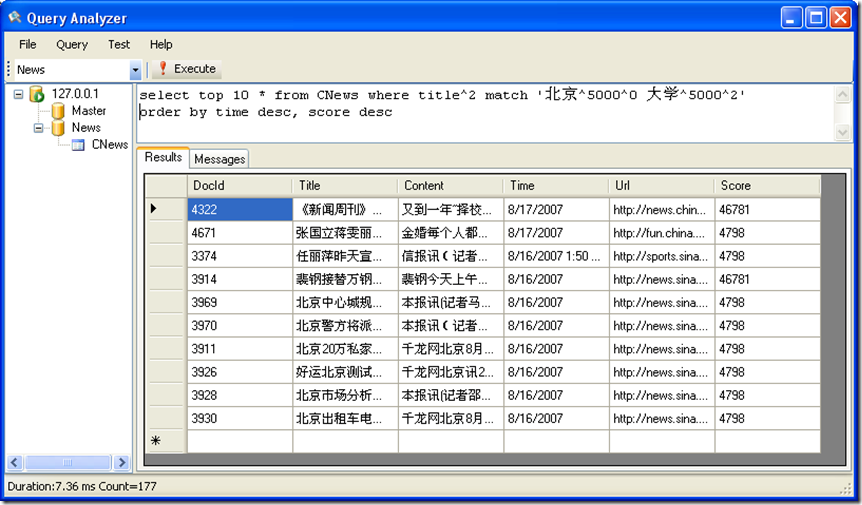
搜索标题中 包含 “北京” “大学” 两个关键字的,并且时间大于 2007 年 1月 1日 小于 2007 年8 月16 日的所有记录,并按照时间和得分同时排倒序
即先按时间排序,时间相同的记录,得分高的排前面。
SQL 语句:select top 10 * from CNews where title^2 match '北京^5000^0 大学^5000^2'
order by time desc, score desc
结果:
在搜索结果中查找
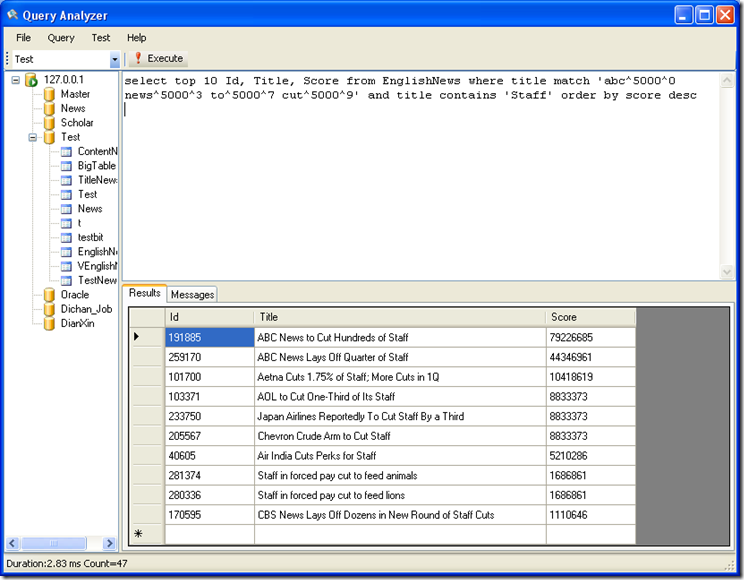
在 match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9' 的结果中再查找包含 Staff 这个词的记录
SQL 语句:select top 10 Id, Title, Score from EnglishNews where title match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9'and title contains 'Staff' order by score desc
结果:
搜索结果中不包含
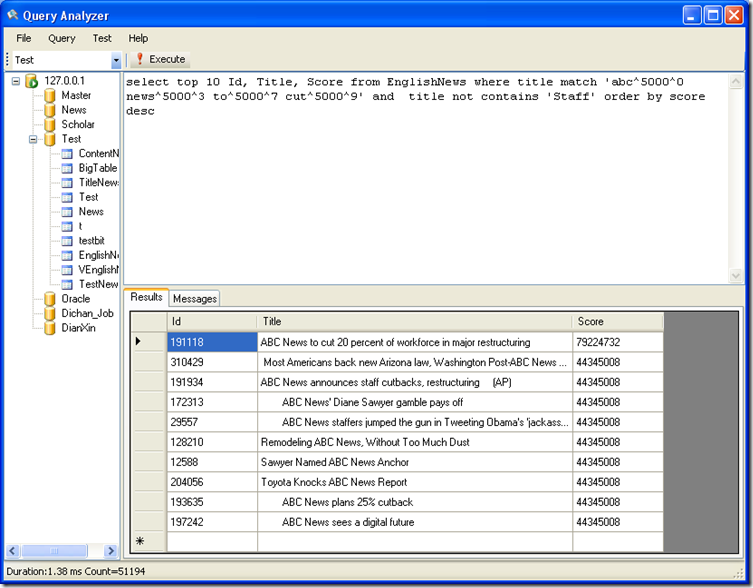
在 match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9' 的结果中再查找不含包含 Staff 这个词的记录
SQL 语句:select top 10 Id, Title, Score from EnglishNews where title match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9'and title not contains 'Staff' order by score desc
结果:
GROUP BY 功能
对单个字段 GROUP BY
搜索标题包含 abc news to cut 这几个关键字中任意一个关键字的记录,并按匹配度排序,同时按 GroupId 字段做统计,
输出记录最多的10个groupid
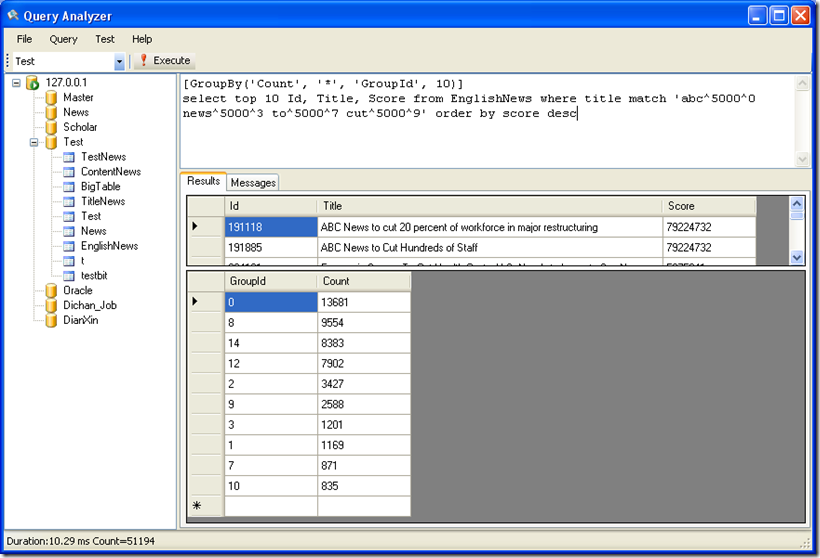
SQL 语句:[GroupBy('Count', '*', 'GroupId', 10)]
select top 10 Id, Title, Score from EnglishNews where title match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9'order by score desc
第一个参数表示采用什么统计函数,目前只支持 Count,以后还会增加 Sum, AVG 等等。
第二个参数为统计函数参数,填* ,相当于 count(*)
第三个参数为要统计的字段名,Group By 字段必须为 untokenized 类型索引字段且不能是字符串类型。
最后一个参数 10 是可选参数,表示返回前10个最多的分组统计结果,如果不填,返回所有分组统计结果。
这个语句执行后,会输出2个DataTable 第一个是 select 语句的结果集,第二个是group by 的结果集。也就是说在全文搜索时同时进行分组统计,
这样使用起来更方便,而且速度更快。
GroupBy 部分的伪SQL 语句是
select top 10 GroupId, count(*) as count from englishnews where title match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9'group by GroupId order by count desc
结果:
同时输出多个字段的Group by统计结果
很多应用,特别是电子商务类应用,查询时需要输出多个分类的统计结果,HubbleDotNet 可以在一次查询中同时输出多个分类的统计结果,极大的方便了这方面的应用。而且HubbleDotNet 的 GroupBy 功能是在底层进行统计的,比Lucene 的统计需要在结果输出后再通过程序进行过滤统计要简单快速很多。
[GroupBy('Count', '*', 'GroupId', 10)]
[GroupBy('Count', '*', 'SiteId', 10)]
select top 10 Id, GroupId, SiteId, Title, Score from EnglishNews where title match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9'order by score desc
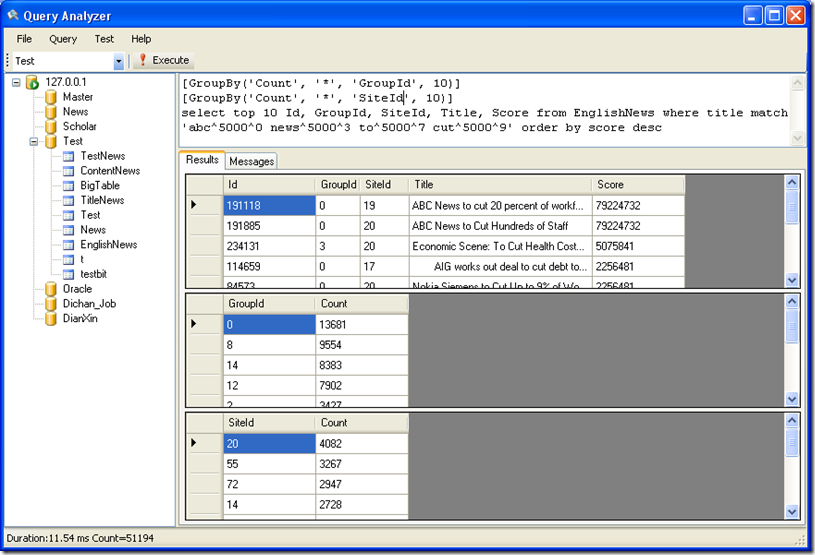 这个语句同时输出针对 GroupId 和SiteId 两个字段的统计结果。
这个语句同时输出针对 GroupId 和SiteId 两个字段的统计结果。
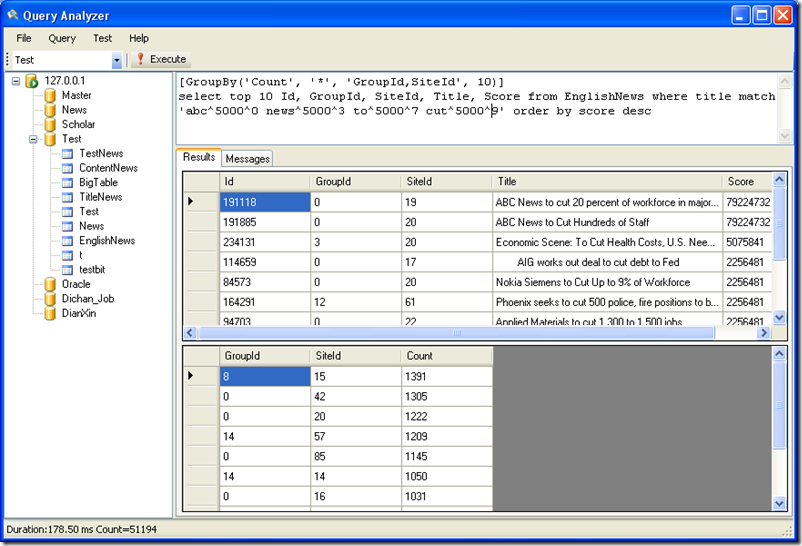
对多字段组合进行Group by本例对 GroupId 和 SiteId 的组合进行Group by[GroupBy('Count', '*', 'GroupId,SiteId', 10)]
select top 10 Id, GroupId, SiteId, Title, Score from EnglishNews where title match 'abc^5000^0 news^5000^3 to^5000^7 cut^5000^9'order by score desc
上述语句可以针对多个字段进行分组统计。要注意的是多字段 GroupBy 时,多个字段的占用字节数总和不可以超过8字节。及最多2个int类型,
或者8个tinyint类型。
Group By Limit 设置
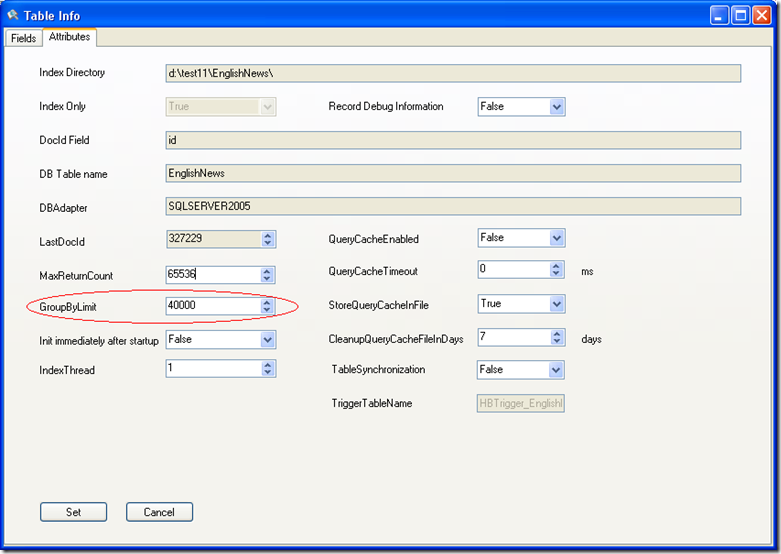
HubbleDotNet 的表属性中有一个 GroupByLimit 设置,这个设置的意思是在做Group by 时只针对前 GroupByLimit 条记录进行统计,如果查询的返回结果集的记录行数大于这个数值,则统计结果为约数,不是实数,在界面上应显示为 类似 (2500+) 这样的形式。这个设置的目的是提高分组统计的效率,默认为40000,如果觉得这个值比较小,可以调大。
多表联合查询功能
HubbleDotNet 提供类似 SQL Union 这样的多表联合查询的功能,用于分布式查询,异构表联合查询。
同构表联合查询
本例为两个相同结构的表联合查询
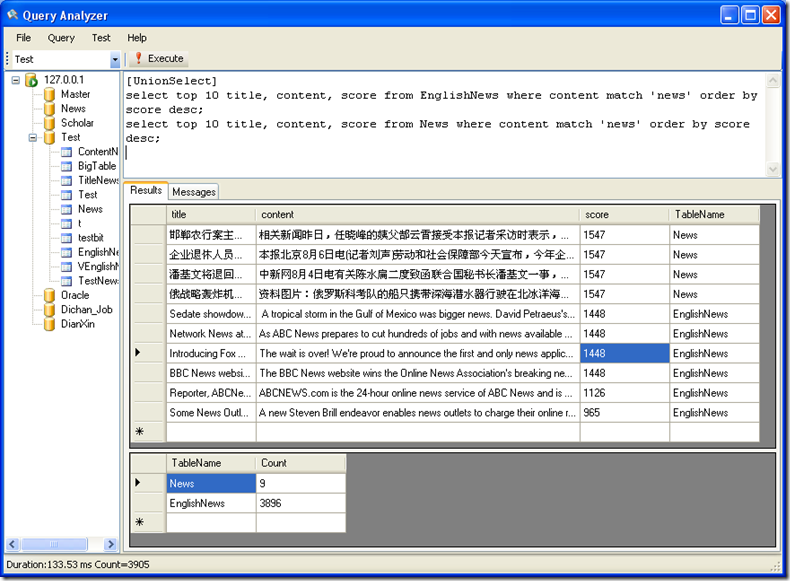
SQL 语句:[UnionSelect]
select top 10 title, content, score from EnglishNews where content match 'news' order by score desc;
select top 10 title, content, score from News where content match 'news' order by score desc;
这个语句对EnglishNews 和 News 这个两个表联合查询匹配 News 这个词的记录,按匹配相关度排序,并返回前10条记录。
这里要注意的是:
联合查询的多条SQL语句必须有 top 或者 between 关键字来指明实际输出多少结果集。每条语句指定的结果集数量必须相当,
比如这里都指定为10。这里实际返回的结果集数量小于等于10,而不是小于等于20.
每条SQL语句的返回字段名必须相同
必须有order by 语句,指明按什么字段进行排序
联合查询的SQL 语句必须以分号“;” 分割
联合查询的SQL语句数量没有限制
查询后返回两个 DataTable ,第一个表是联合查询的结果集,第二个表是联合查询中各个语句实际匹配的记录数。这里News表匹配了9条记录
而EnglishNews 表匹配3896条记录。
结果:
异构表联合查询
很多网站的应用中,要全文查询的表不止一种,比如一个网站有博客,有新闻,这些表的字段名都不相同,如果我们希望通过一个统一的入口来查询所有博客和新闻的全文,过去的方法是把博客和新闻的数据整合到一个全文索引结构中,然后进行查询,这样做是对资源的严重浪费。HubbleDotNet 通过UnionSelect 功能,可以对这种异构表联合查询的需求进行支持,你可以通过SQL语句任意动态组合不同的异构数据表进行查询,而不需要重新建立索引。
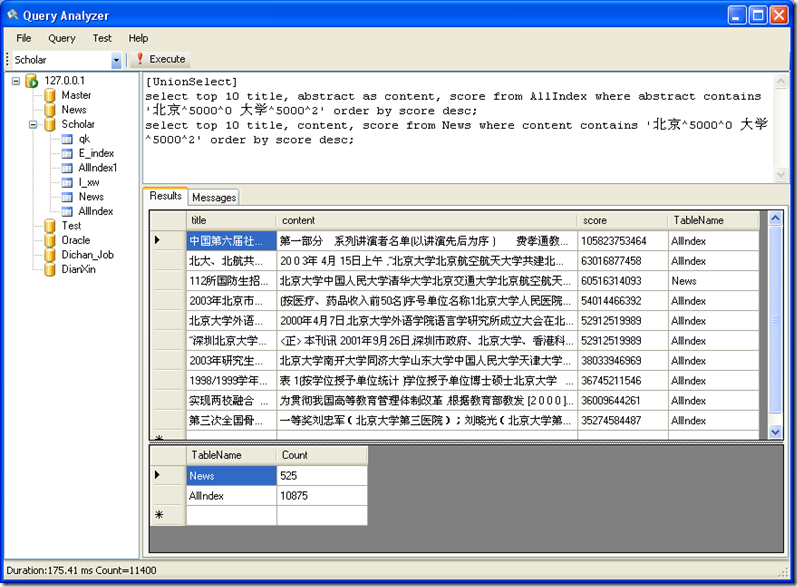
SQL 语句:[UnionSelect]
select top 10 title, abstract as content, score from AllIndex where abstract contains '北京^5000^0 大学^5000^2' order by score desc;
select top 10 title, content, score from News where content contains '北京^5000^0 大学^5000^2' order by score desc;
这个语句对AllIndex 和 News 这个两个表联合查询匹配 北京大学 这个词的记录,按匹配相关度排序,并返回前10条记录。
由于 AllIndex 和 News 表结构不同,AllIndex 中没有 content 字段,而是 abstract 字段,所以在这个联合查询语句中,我们将 abstract 字段通过 as 关键字改名为 content 字段输出,这样两个查询语句返回的字段名就相同了,就可以实现异构表的联合查询了。
结果:
采用UnionSelect 对海量数据分割为小表后联合查询
对于 5000万行以上的海量数据,可以通过分割为多个小表然后联合查询的方式来提高查询效率,由于UnionSelect 查询时,多条SQL语句是并行执行的,在多核计算机上,并行查询可以大大提高查询速度,海量数据分割后查询的速度也会比单个大表的查询速度要快。另外分割成小表还有一个好处是提高了索引和优化的效率,如果一个大表的索引文件大小为600G,那么每次优化都会生成一个600G这么大的索引文件,其耗时是巨大的。但如果分割为10个60G的表,则优化只要生成60G大小的索引文件,耗时要小10倍。而且很多应用是只有增量和删除,这种情况下很多历史表一旦生成就不需要再重新索引了,比如我们每天生成一个索引表,那么只要每天对当天的索引表索引就可以了,不需要将当天的索引和历史索引合并,这样索引的效率就大大提高了。
HubbleDotNet 海量数据测试报告 这篇文章中的海量数据就是分割为8个小表联合查询来做的。
对于2000万行一下的数据,如果索引文件不是特别大,可以单表索引,联合查询对性能的提升有限。














 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









