





 博客介绍了算法在GraphLab中运行需定义gather、apply和scatter三个步骤,阐述了执行过程。还说明了图分区和分布式处理方法,以及分布式操作的必要条件。最后以KNN为例,介绍了其在图形信号处理中的应用,并对比了同步和异步引擎的特点。
博客介绍了算法在GraphLab中运行需定义gather、apply和scatter三个步骤,阐述了执行过程。还说明了图分区和分布式处理方法,以及分布式操作的必要条件。最后以KNN为例,介绍了其在图形信号处理中的应用,并对比了同步和异步引擎的特点。
1.GAS 步骤
为了算法在GraphLab中运行,需要定义gather, apply 和 scatter 三个步骤。GraphLab里的算法表达成vertex programs, 每个顶点并行执行并与临近点相交互。
- 第一步:点Y是中心点,scope代表邻接点。每个邻接点都会从计算中获得一个结果。
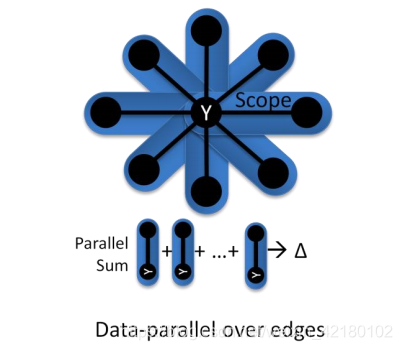
2. 执行
当Graph加载了一个顶点项目,每个顶点需要被赋值去执行程序。一些情况下,所有的顶点被赋值,另一些情况,图会被分为训练点和测试点,只有测试点会被赋值,完成此操作后,它们将被添加到执行队列中,根据使用的引擎,可以以两种不同的方式处理它们:
3. 图分区和分布式处理
而图通常是削减边缘,为了处理分布式机器,GraphLab削减基于顶点的图,创建副本相同的顶点分裂的双方,这样的一个副本节点存在于所有的机器需要特定的顶点。对于任何分裂顶点,使用存储在每台机器中的邻居,收集步骤将发生在该顶点具有副本的所有机器上。每台机器都将从它们可以访问的邻居集合中获得部分结果。这个部分结果将在网络上共享,以便每台机器可以对部分结果求和并得到一个公共值,该值将在应用步骤期间在每台机器上使用,如图所示。
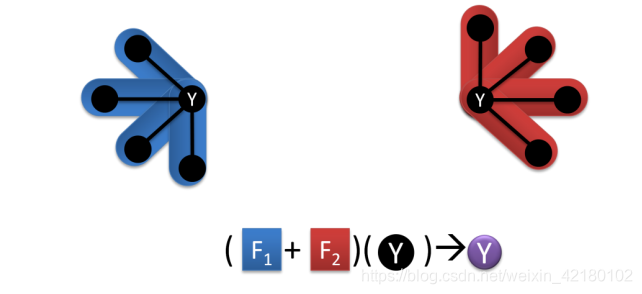 在本例中,图形在Y节点上进行切割,在每台机器上创建一个副本。节点Y有8个邻居节点,其中4个可以在左边的机器上找到,其他的可以在右边的机器上找到。每台机器从收集步骤计算它自己的和。对这两台机器的结果进行求和,以获得要应用的公共值。
在本例中,图形在Y节点上进行切割,在每台机器上创建一个副本。节点Y有8个邻居节点,其中4个可以在左边的机器上找到,其他的可以在右边的机器上找到。每台机器从收集步骤计算它自己的和。对这两台机器的结果进行求和,以获得要应用的公共值。
为了将图分布到网络中的机器上,将进行分区,以使机器之间所需的网络通信最小化。为此目的,GraphLab构造了一个平衡的数据图分区,使跨机器的边数最小化。为了有效地平衡任意集群大小上的负载,采用了两阶段分区。在第一个阶段,图被过度分割成k个部分,其中k远远大于机器的数量,使用领域特定的知识,如平面嵌入。图的每个部分都存储在一个临时的分布式存储系统中。使用k个顶点(对应于初始分区)构建元图,然后通过执行快速平衡分区在物理机器上分布。每台机器使用分配的元图的分区和初始分区的信息构造自己的图的一部分。
4.分布式操作的必要条件
1)业务将需要本地化。正如在GAS模型中所看到的,对于每个顶点,只能访问相邻的顶点。
2)无法对每个顶点使用整个图的拉普拉斯矩阵。为了得到拉普拉斯矩阵,我们需要访问整个图。GraphLab不允许这样做。如果算法需要使用拉普拉斯矩阵(频率相关算法中常见的东西)来实现,我们将需要找到一个解决方案。可以使用局部拉普拉斯矩阵:如果操作允许,可以使用相邻顶点的值。如果想要一个图的傅里叶变换,这个限制会变得更严格。为此,需要拉普拉斯矩阵的奇异值分解(SVD),而不能用局部拉普拉斯矩阵得到:傅里叶变换的基不一样。一个单步图可以用于图的傅里叶变换,尽管这会导致不同的结果,因为拉普拉斯矩阵是不同的。
3)对于某些需要访问整个图的算法,只需要考虑图的一小部分就可以找到近似
5.例子:KNN(K近邻)
在图形信号处理方面,kNN是一种简单的插值算法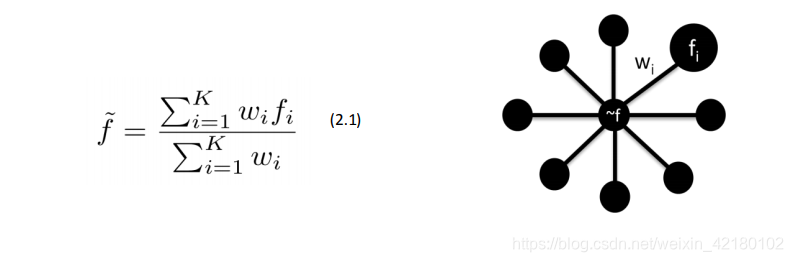
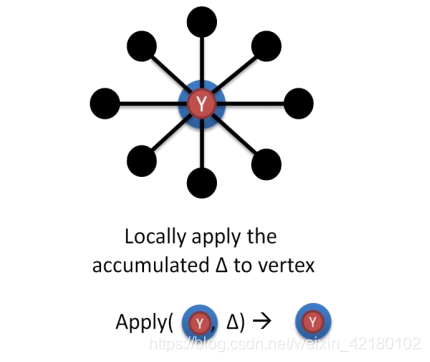
- 第二步:赋值
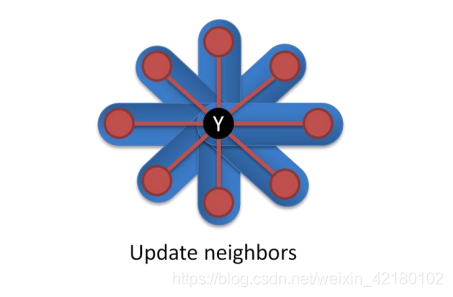
- 第三步:更新邻接点
- 同步引擎:在这种模式下,对于顶点程序的每次迭代,引擎将等待所有顶点的处理。所有顶点的处理操作完成后,将开始下一个迭代。这将确保相邻顶点值的一致性。这种模式对于处理多个步骤的算法非常有用,其中每个步骤算法都将使用前一个步骤的结果。
- 异步引擎:在这种模式下,程序的迭代将在每个顶点上处理,而不等待其他顶点完成。在这种情况下,算法可能在图的特定部分提前结束。这种模式对于PageRank等收敛算法非常有用,其中每个顶点的值都使用相邻的顶点值进行更新,直到它们达到稳定状态。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









