







如需转载,请加原文链接pca(princomp)函数详细介绍–墙推
https://blog.csdn.net/weixin_42187898/article/details/103702101
1.背景了解
在涉及有多个因素对系统的影响时,一种常见的方法是主成分分析,也就是pca方法。
pca的函数改进声明:
在matlab2019B中,已经将princomp函数改为了pca函数,功能相同,函数名改变,所以如果要使用,记得将老版本的代码中的princomp改为pca。
供献率: 每一维数据对于区分全部数据的供献,供献率最大的显然是主成分,第二大的是次主成分…
2.pca函数
matlab中的pca函数主要是实现主成分分析的功能,有1个或3个输入参数,返回参数常见的为4个,帮助文档中涉及到的形式如下:
coeff = pca(X)
coeff = pca(X,Name,Value)
[coeff,score,latent] = pca(___)
[coeff,score,latent,tsquared] = pca(___)
[coeff,score,latent,tsquared,explained,mu] = pca(___)
总结:
1,四个输出是(特征向量_每一列为原始数据组合成主成分的系数,新的坐标_中心化的坐标,特征值_主成分的系数,观察量到中心的距离);
2,切记:行为元组,列为属性
输入:
X: 为一个M * N维矩阵原始数据,即共有M个样本,每个样本的维度是N维,带入princomp函数,将会生成新的N维加工后的数据(即score)。此数据与之前的N维原始数据一一对应。
输出:
coef: N * N维矩阵,即是系数矩阵,通过coef可以知道X是怎样转成score的,此处的转换,是对输入X的主成分进行了零均值化(参考《模式识别 第三版 张学工》P164) 的处理的,即:
score = (X - miu(X)) * coef
coef 矩阵中,每一列都是Sigma的一个特征向量,Sigma是输入X的协方差矩阵
score: M * N维矩阵,是经过主成分分析变换(即KL变换)后的数据,是对原始数据的解析,进而在新的坐标系下生成的数据,并且将这N维数据按贡献率由大到小排列
latent: N * 1维矩阵,每一个数据对应score里相应维的贡献率,因为每个样本有N维数据,所以latent有N维,也是由大到小排列的(因为score也是按供献率由大到小分列)。
Tsquared: 观察量到中心的距离
则模型为从原始数据出发:
score= bsxfun(@minus,x,mean(x,1))coef;(感化:可以把测试数据经由过程此办法改变为新的坐标系)
逆变换:
x= bsxfun(@plus,scoreinv(coef),mean(x,1))
3.例子
下面来看个例子:
%%
%清屏
clear
%%
%初始化数据
a=[-14.8271317103068,-3.00108550936016,1.52090778549498,3.95534842970601;-16.2288612441648,-2.80187433749996,-0.410815700402130,1.47546694457079;-15.1242838039605,-2.59871263957451,-0.359965674446737,1.34583763509479;-15.7031424565913,-2.53005662064257,0.255003254103276,-0.179334985754377;-17.7892158910100,-3.32842422986555,0.255791146332054,1.65118282449042;-17.8126324036279,-4.09719527953407,-0.879821957489877,-0.196675865428539;-14.9958877514765,-3.90753364293621,-0.418298866141441,-0.278063876667954;-15.5246706309866,-2.08905845264568,-1.16425848541704,-1.16976057326753;];
x=a;
%%
%调用princomp函数
[coef,score,latent,t2] = pca(x);
score
%测试score是否和score_test一样
score_test=bsxfun(@minus,x,mean(x,1))*coef;
score_test
latent=100*latent/sum(latent)%将latent总和同一为100,便于调查供献率
pareto(latent);%调用matla画图
View Code
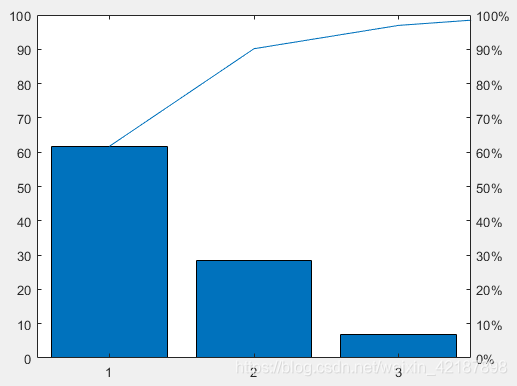
上图是经由过程自带函数绘制,当供献率累加至95%,今后的维数会不在显示,最多只显示10维。
做出的图像:
4.深入理解
能够深入理解三点:
1.认为主成分解析中latent显示的供献值是原始数据的,其实是加工后的数据的。申明:对原始数据既然选择PCA办法,那么策画机认为原始数据每维之间可能存在接洽关系,你想去掉接洽关系、降落维数。所以采取这种办法的。所以策画机并不关怀原始数据的供献值,因为你不会去用了,用的是加工后的数据(这也是为什么当把输入数据每一维的次序改变后,score、latent不受影响的原因)。
2.认为PCA解析后主动降维,不合错误。PCA后会有供献值,是输入者按照本身想要的供献值进行维数的改变,进而生成数据。(一般大师会取供献值在85%以上,请求高一点95%)。
3.PCA解析,只按照输入数据的特点进行主成分解析,与输出有几许类型,每个数据对应哪个类型无关。若是样本已经分好类型,那PCA后势必对成果的正确性有必然影响,我认为对于此类数据的PCA,就是在降维与正确性间找一个均衡点的题目,让数据即不会维数多而使运算错杂,又有较高的辨别率。
5.帮助理解的例子
这是matlab中文论坛里面一个大神写的,帮助理解
% 关于matlab中princomp的使用说明讲解小例子 by faruto
% 能看懂本程序及相关注释讲解的前提是您对PCA有一定的了解~O(∩_∩)O
% 2009.10.27
clear;
clc
%% load cities data
load cities
% whos
% Name Size Bytes Class
% categories 9x14 252 char array
% names 329x43 28294 char array
% ratings 329x9 23688 double array
%% box plot for ratings data
% To get a quick impression of the ratings data, make a box plot
figure;
boxplot(ratings,'orientation','horizontal','labels',categories);
grid on;
print -djpeg 1;
%% pre-process
stdr = std(ratings);
sr = ratings./repmat(stdr,329,1);
%% use princomp
[coef,score,latent,t2] = princomp(sr);
%% 输出参数讲解
% coef:9*9
% 主成分系数:即原始数据线性组合生成主成分数据中每一维数据前面的系数.
% coef的每一列代表一个新生成的主成分的系数.
% 比如你想取出前三个主成分的系数,则如下可实现:pca3 = coef(:,1:3);
% score:329*9
% 字面理解:主成分得分
% 即原始数据在新生成的主成分空间里的坐标值.
% latent:9*1
% 一个列向量,由sr的协方差矩阵的特征值组成.
% 即 latent = sort(eig(cov(sr)),'descend');
% 测试如下:
% sort(eig(cov(sr)),'descend') =
% 3.4083
% 1.2140
% 1.1415
% 0.9209
% 0.7533
% 0.6306
% 0.4930
% 0.3180
% 0.1204
% latent =
% 3.4083
% 1.2140
% 1.1415
% 0.9209
% 0.7533
% 0.6306
% 0.4930
% 0.3180
% 0.1204
% t2:329*1
% 一中多元统计距离,记录的是每一个观察量到中心的距离
%% 如何提取主成分,达到降为的目的
% 通过latent,可以知道提取前几个主成分就可以了.
figure;
percent_explained = 100*latent/sum(latent);
pareto(percent_explained);
xlabel('Principal Component');
ylabel('Variance Explained (%)');
print -djpeg 2;
% 图中的线表示的累积变量解释程度.
% 通过看图可以看出前七个主成分可以表示出原始数据的90%.
% 所以在90%的意义下只需提取前七个主成分即可,进而达到主成分提取的目的.
%% Visualizing the Results
% 结果的可视化
figure;
biplot(coef(:,1:2), 'scores',score(:,1:2),...
'varlabels',categories);
axis([-.26 1 -.51 .51]);
print -djpeg 3;
% 横坐标和纵坐标分别表示第一主成分和第二主成分
% 红色的点代表329个观察量,其坐标就是那个score
% 蓝色的向量的方向和长度表示了每个原始变量对新的主成分的贡献,其坐标就是那个coef.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









