







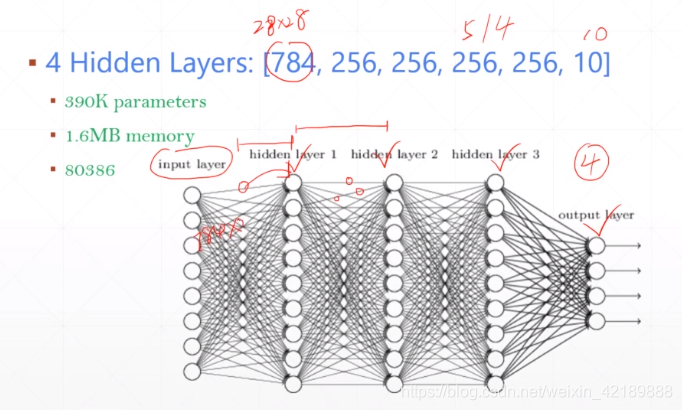
线性层的局限
图片通常输入维度较大,一个28*28的图片就有784个输入,一个有四个隐含层的网络,就有多达390K个参数。
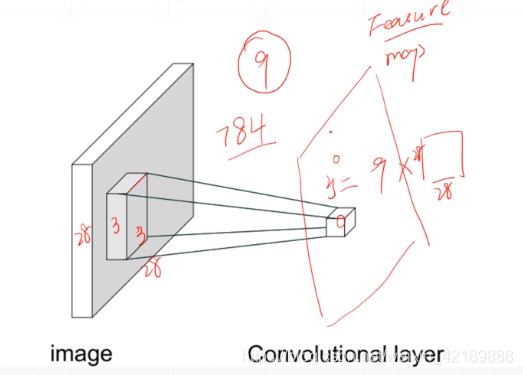
不一次性接收所有信息,而是只感受一部分。
用一个窗口扫描图片,这个窗口相当于权值,在扫描一张图片的时候始终不变,(weight sharing)
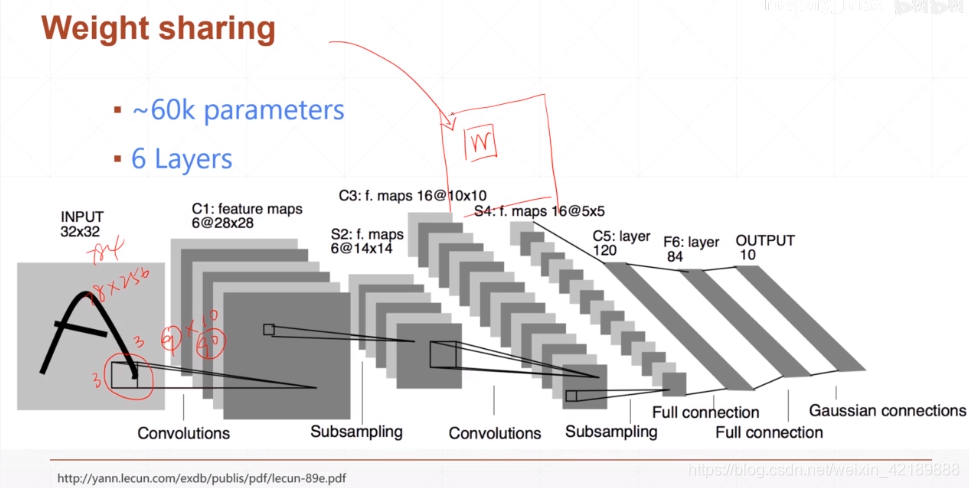
可以看到用此方法可以很好地降低参数规模
卷积:
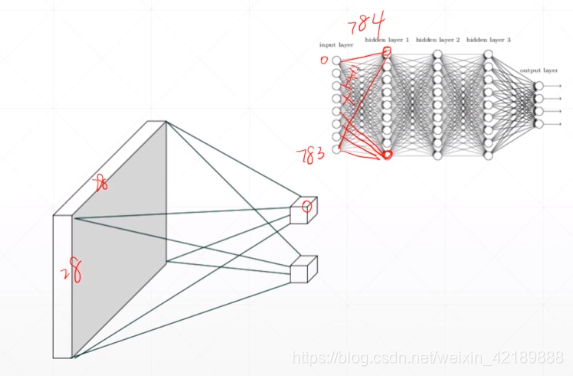
非卷积
卷积神经网络的运算
用一个卷积核kernel,对原图的每一个对应的区域作逐个相乘求和运算,得到一个新发feature map,即为一个卷积层
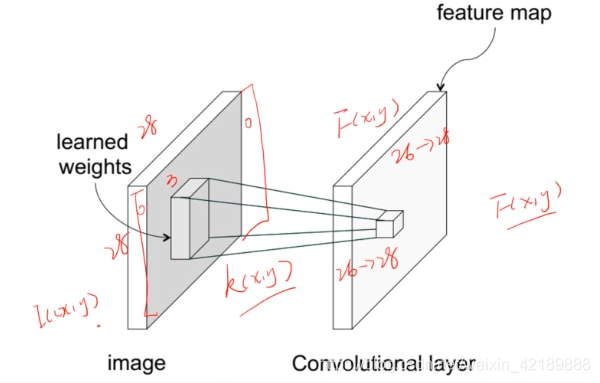
得到的feature map可以代表的信息和卷积核的结构有关
比如如果目标是边缘检测,kernel可以是边缘信息
有多个kernel即有多个“不同的观察角度”,就会生成多个feature map
input_channels:输入有多少个通道(图片的话黑白是1,彩色是3,等等)
kernel_channels:核通道,即有多少个卷积核,注意每一个input的channel都要有一个对应的channel。此channel是属于一个kernelcnannel内的。要注意区分
kernel_size:核大小
stride:卷积核的移动步长
padding:补上的空缺(层数)大小
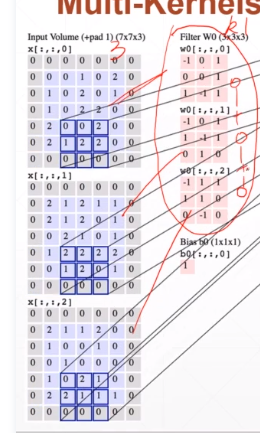
更一般的情况。输入map有三个通道,有16个核
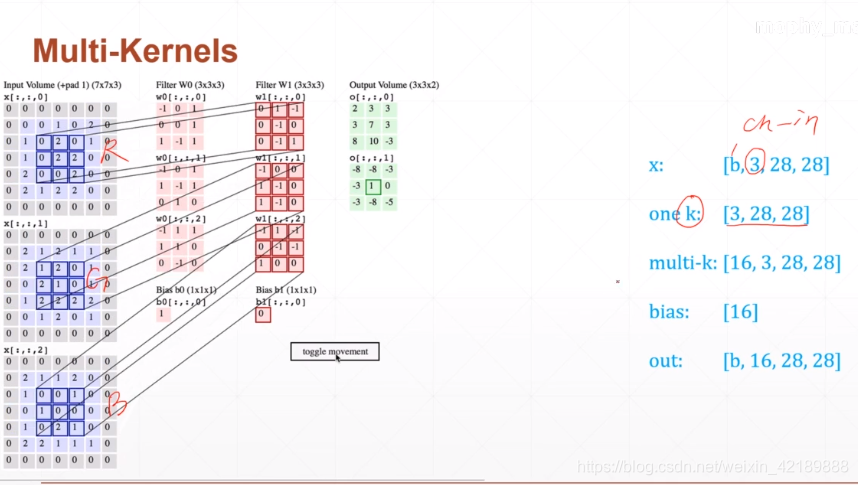
注意算的时候累加两次,看图:如下是一个kernelchannel的情况。
例子:LeNet-5
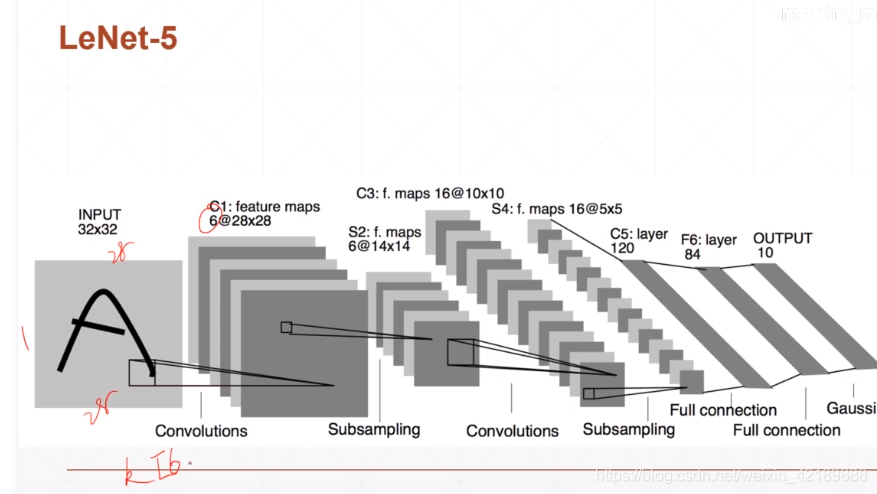
input是一个2828的图片,只有一个channel(黑白)
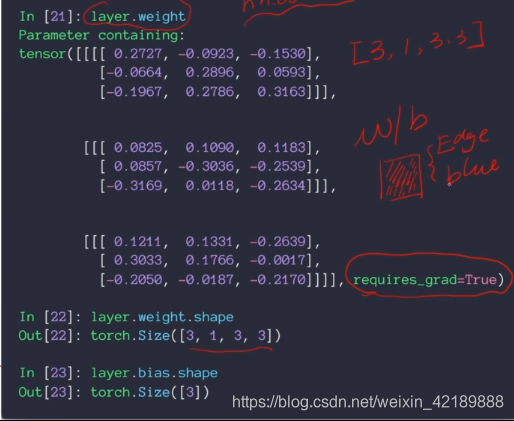
C1的output有6个,说明有6个kernel,每个kernel的channel数与input一致,为1;kernel的大小为33,所以其shape为(6,1,3,3)bias大小为kernel的数量[6]
经过一次下采样后得到6个14*14的feature。
第二层的kernel为16个(因为C3结果有十六个)每个kernel有6个channel,因为输入有6个channel。第二个kernel的shape为(16,6,3,3)
卷积层数越深,表达的概念越具体

用pytorch进行卷积运算

用nn.Conv2d函数,第一个参数为输入的channel,第二个参数为kernel的数量(如果输入为[batch_size,1,28,28],kernel的shape为[3,1,3,3])
这样就定义好了一个卷积层的输入和kernel,有了这两个参数就可以得到输出结果。

如果padding设置为1,输出的图片大小不变:

如果直接用layer(x)输出结果,而不是用layer.forward(x)可以利用layer函数中封装的一些hooks。因此可以首选用layer函数:

layer中的weight:kernel是要在神经网络中优化的参数 之一,因此有requies_grad=True
卷积神经网络中的pooling层等
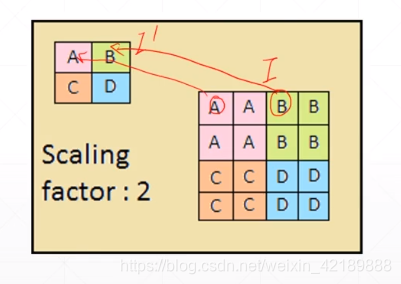
下采样 downsample
比如隔行采样
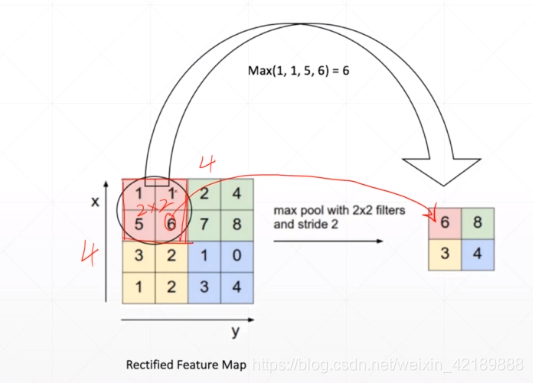
max pooling:取窗口区域中最大值
avg pooling:取区域的平均值
用pytorch完成pooling操作:
x的size如下,16个channel,大小为1414

指定pooling的窗口大小和移动步长:
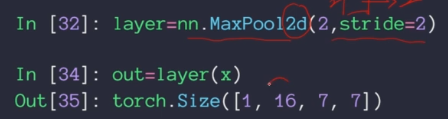
大小是22,步长是2,结果为长宽各减半:

上采样:

参数是输入图片,要放大的倍数,以及插值方法
relu函数:过滤掉负值:
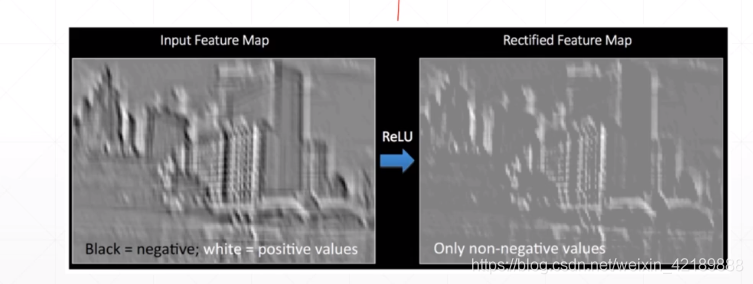
常见的卷积单元如下:
conv2d-Batch Norm-Pooling-ReLU
举例:
有一个经过了conv2d和一个pooling层的Tensor
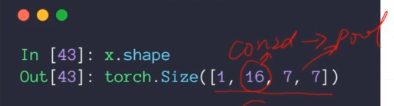
经过ReLU,由于经过ReLU后大小不变,可以设置inplace=True,这样可以使用原来x的内存
Batch Norm
sigmoid函数的倒数接近零,可能会出现梯度为0的情况:
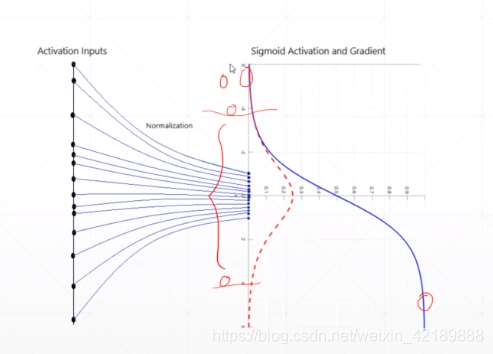
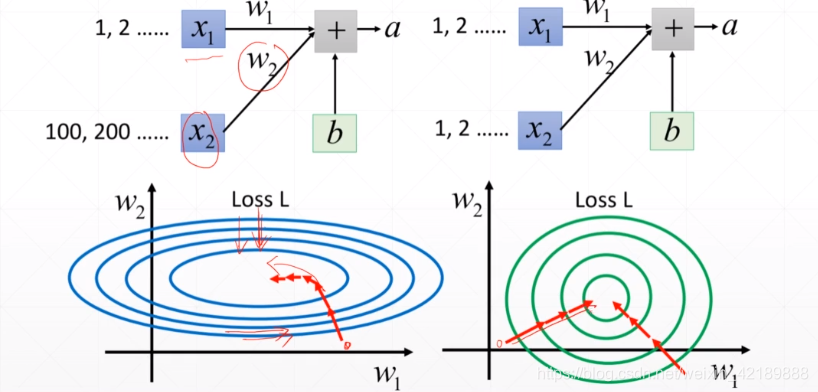
在输入到sigmoid函数之前,先将输入进行标准化,比如使其以0为均值,以1为方差
如果x1和x2的范围差别较大,搜索路径会较为曲折;如果x1和x2的范围被标准化到同一个范围,搜索路径会相对一致,不确定性小。
用途:
1、Image Normalization:
normalize=transform.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
这些数字是依据实际RGB图片统计得出的。图片经过这种标准化处理之后,会符合(0,1)的正态分布
2、Batch Normalization
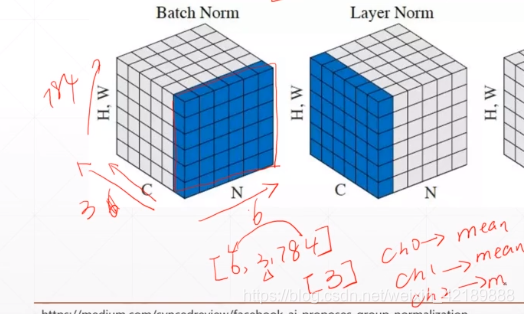
一个Batch:[N,C,H,W](N张图片,C个channel,H,W为长和宽)H和W相乘,组为一个维度。举例,6张图片,3个channel,784个HW
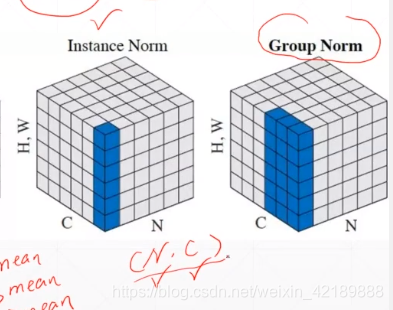
可以在CN上作Normalization,比如取均值,那么就变成3个数据,是在三个不同的通道上取得的标准化值
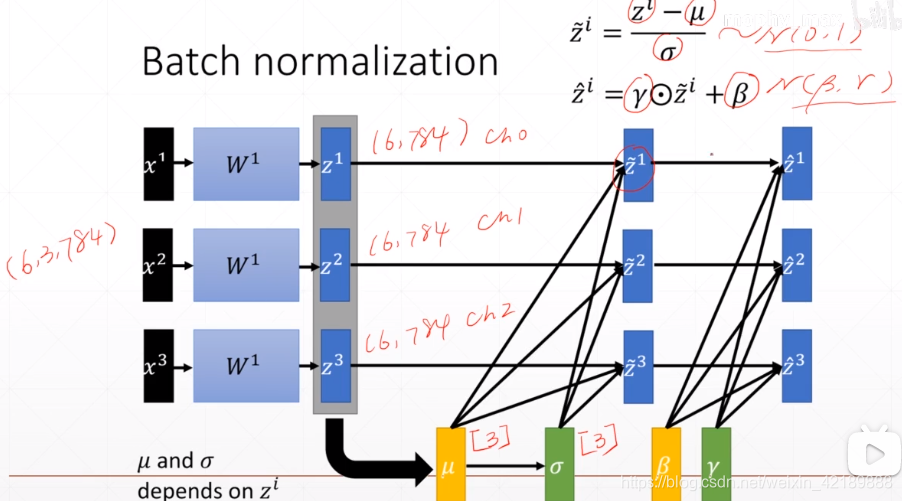
批标准化的过程如下:
在pytorch中作批标准化:















 6570
6570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









