







懂点python爬虫的博主,不知道拿什么练手。竟然打起了CSDN的注意(真是初生牛犊不怕虎)没办法啊。淘宝反爬太厉害(其实是自己水平问题)再看NIKE官网的Robots吓到我了
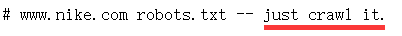
这是不是翻译成----给爷爬?-----😂好了废话不多说,开始搞起
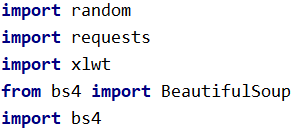
本次爬虫用到:
首先看下CSDN的君子协议
在网页的输入框中输入–https://www.csdn.net/robots.txt

额…额…管他呐,反正是君子协议。咱只动手。
写一下框架
import random
import requests
import xlwt
from bs4 import BeautifulSoup
import bs4
#获取页面信息
def getHTMLText(url):
return
#提取信息
def extractInfo(infoList, html):
print
#保存信息
def saveInfo(infoList):
print
#入口
def main():
main()
推荐(大学慕课)北理工嵩天老师的爬虫课
填充内容
- 获取页面【用户代理,IP代理(直接百度就有免费的)可以不用。但是爬虫要有仪式感,博主就写一下(其实是怕被CSDN追到)】
#获取页面信息
def getHTMLText(url):
#用户代理
headers =[
{"User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36"},
{"User-Agent" : "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0"},
{"User-Agent" : "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)"}
]
head = random.choice(headers)
#ip代理
proxies = [
{"http" : "123.206.25.108:808"},
{"http" : "61.150.96.27:36880"},
{"http" : "1.198.73.42:9999"},
]
proxie = random.choice(proxies)
try:
r = requests.request("GET", url, timeout = 30, headers = head, proxies = proxie)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
- 提取信息
def extractInfo(infoList, html):
soup = BeautifulSoup(html, "html.parser")
articleList = soup.find("div", "article-list").children
for info in articleList:
if isinstance(info, bs4.element.Tag):
info.prettify()
a = info.h4.a.contents
# 标题
title = a[2].strip()
ps = info.div('p')
# 日期 去掉空格以及替换掉回车换行
date = ps[0].contents[1].string.strip().replace("\n", "")
# 阅读量
pageview = ps[2].contents[1].contents[1].string.strip()
# 评论数
comments = ps[4].contents[1].contents[1].string.strip()
infoList.append([title, date, int(pageview), int(comments)])
- 保存信息
def saveInfo(infoList):
# 1.新建工作簿
newWorkbook = xlwt.Workbook()
# 2.添加表单
workSheet = newWorkbook.add_sheet('myCsdnInfo')
# 3.写入数据(行,列,数据)
workSheet.write(0, 0, '标题')
workSheet.write(0, 1, '发布日期')
workSheet.write(0, 2, '阅读量')
workSheet.write(0, 3, '评论数')
for row in range(1, len(infoList) + 1):
u = infoList[row - 1]
for col in range(0, 4):
workSheet.write(row, col, u[col])
# 4.保存文件
newWorkbook.save('./test.xls')
- 主函数
def main():
#自己的CSDN--我的博客主页的网址
url = "https://blog.csdn.net/weixin_42190209"
infoList = []
html = getHTMLText(url)
extractInfo(infoList, html)
saveInfo(infoList)
main()
运行结果(让人泪目的运行结果,让人泪目的阅读量和评论数😭我太难了!)
















 53万+
53万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









