







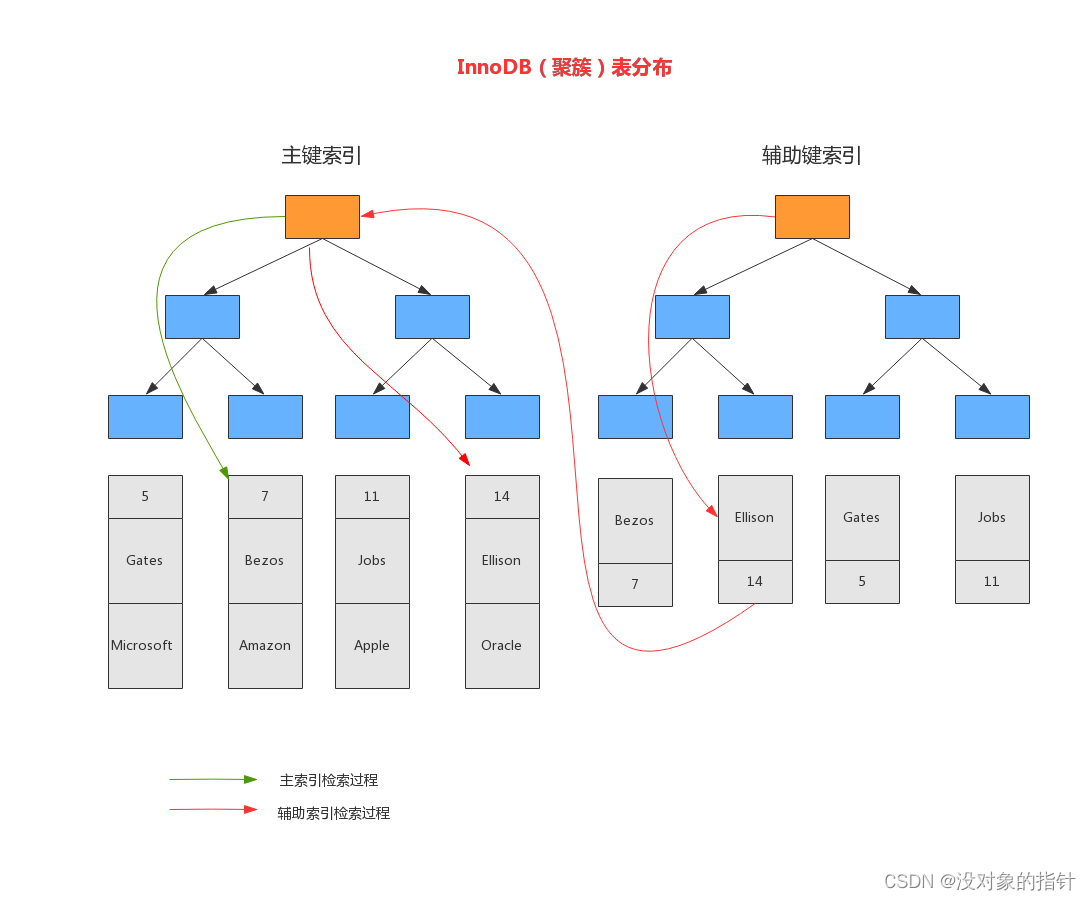
1. 聚簇索引
聚簇索引是一种数据存储方式:在 InnoDB 中,聚簇索引是通过将表的数据存储在按照索引键值排序的 B+ 树结构中来实现的。 B+Tree 的叶子节点就是行记录,行记录和主键值紧凑地存储在一起, 这也意味着 InnoDB 的主键索引就是数据表本身,它按主键顺序存放了整张表的数据,占用的空间就是整个表数据量的大小。通常说的主键索引就是聚集索引。
InnoDB 的表要求必须要有聚簇索引:
- 在 InnoBD中 通过主键来聚簇数据,也就是说聚簇索引的的 B+Tree 上的叶子节点所存储的 key 总是主键值
- 如果没有定义主键,InnoDB 会选择一个唯一的非空索引来代替
- 如果也没有这样的索引,InnoDB 会隐式地定义一个主键来聚簇数据,这个隐式的主键被称为 row-id
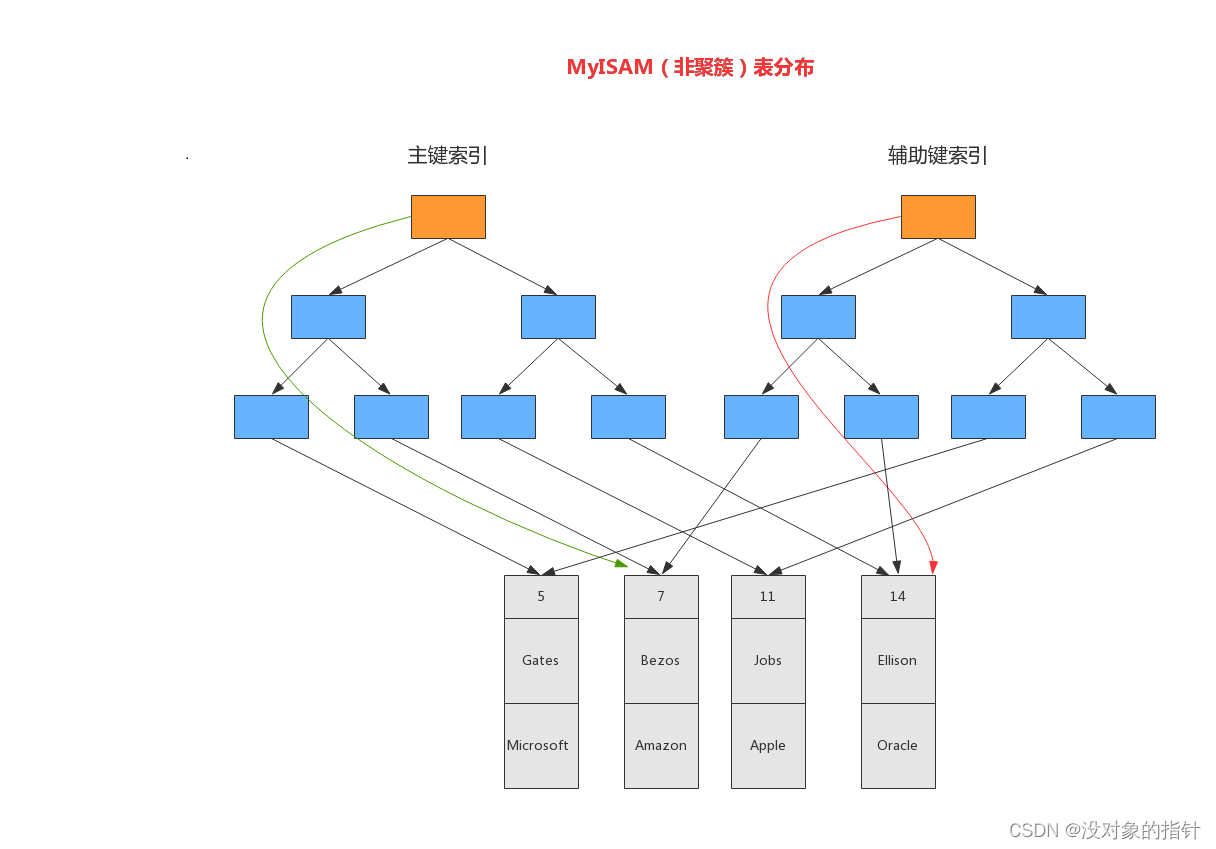
3. 非聚簇索引
非聚簇索引是一种数据结构,它可以帮助加快查询速度。非聚簇索引是通过将索引数据和实际数据分开存储来实现的。与聚簇索引不同,非聚簇索引不会改变表中数据的物理排序。
非聚簇索引的工作原理是在索引的叶子节点上存储指向实际数据行的指针。当使用非聚簇索引进行查询时,首先查找索引并获取对应的指针,然后使用指针找到实际数据行。
与聚簇索引相比,非聚簇索引有以下几个特点:
-
一个表可以有多个非聚簇索引,但只能有一个聚簇索引。
-
非聚簇索引不会改变表中数据的物理排序,而聚簇索引会根据索引顺序来存储数据行。
-
非聚簇索引通常比聚簇索引更小,因为它不需要存储实际数据行。
-
使用非聚簇索引进行查询时,MySQL需要进行两次查找:先查找索引,然后查找实际数据行。
4. 聚簇索引和非聚簇索引的区别及优缺点
4.1 区别
- 聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个
- 聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续
- 聚集索引:物理存储按照索引排序;聚集索引是一种索引组织形式,索引的键值逻辑顺序决定了表数据行的物理存储顺序。
非聚集索引:物理存储不按照索引排序;非聚集索引则就是普通索引了,仅仅只是对数据列创建相应的索引,不影响整个表的物理存储顺序。 - 索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
4.2 优缺点
聚集索引插入数据时速度要慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入),查询数据比非聚集数据的速度快。
5. 聚集索引需要搞清楚的几个问题
5.1 聚集索引的约束是唯一性,是否要求字段也是唯一的呢?
分析:如果认为是的朋友,可能是受系统默认设置的影响,一般我们指定一个表的主键,如果这个表之前没有聚集索引,同时建立主键时候没有强制指定使用非聚集索引,SQL会默认在此字段上创建一个聚集索引,而主键都是唯一的,所以理所当然的认为创建聚集索引的字段也需要唯一。
结论:聚集索引可以创建在任何一列你想创建的字段上,这是从理论上讲,实际情况并不能随便指定,否则在性能上会是恶梦。
5.2 为什么聚集索引可以创建在任何一列上,如果此表没有主键约束,即有可能存在重复行数据呢?
粗一看,这还真是和聚集索引的约束相背,但实际情况真可以创建聚集索引。
分析其原因是:如果未使用 UNIQUE 属性创建聚集索引,数据库引擎将向表自动添加一个四字节 uniqueifier 列。必要时,数据库引擎将向行自动添加一个 uniqueifier 值,使每个键唯一。此列和列值供内部使用,用户不能查看或访问。
5.3 是不是聚集索引就一定要比非聚集索引性能优呢?如果想查询学分在60-90之间的学生的学分以及姓名,在学分上创建聚集索引是否是最优的呢?
答:否。既然只输出两列,我们可以在学分以及学生姓名上创建联合非聚集索引,此时的索引就形成了覆盖索引,即索引所存储的内容就是最终输出的数据,这种索引在比以学分为聚集索引做查询性能更好。
5.4 在数据库中通过什么描述聚集索引与非聚集索引的?
索引是通过二叉树的形式进行描述的,我们可以这样区分聚集与非聚集索引的区别:聚集索引的叶节点就是最终的数据节点,而非聚集索引的叶节仍然是索引节点,但它有一个指向最终数据的指针。
5.5 在主键是创建聚集索引的表在数据插入上为什么比主键上创建非聚集索引表速度要慢?
有了上面第四点的认识,我们分析这个问题就有把握了,在有主键的表中插入数据行,由于有主键唯一性的约束,所以需要保证插入的数据没有重复。我们来比较下主键为聚集索引和非聚集索引的查找情况:聚集索引由于索引叶节点就是数据页,所以如果想检查主键的唯一性,需要遍历所有数据节点才行,但非聚集索引不同,由于非聚集索引上已经包含了主键值,所以查找主键唯一性,只需要遍历所有的索引页就行(索引的存储空间比实际数据要少),这比遍历所有数据行减少了不少IO消耗。这就是为什么主键上创建非聚集索引比主键上创建聚集索引在插入数据时要快的真正原因。
















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











