







[C++ 基于Eigen库实现CRN前向推理]
第三部分:TransposedConv2d实现 (含dilation)
- 前言:(Eigen库使用记录)
- 第一部分:WavFile.class (实现读取wav/pcm,实现STFT)
- 第二部分:Conv2d实现
- 第三部分:TransposedConv2d实现 (mimo,padding,stride,dilation,kernel,outpadding)
- 第四部分:NonLinearity (Sigmoid,Tanh,ReLU,ELU,Softplus)
- 第五部分:LSTM
- GITHUB仓库
1. LSTM介绍
1.1 pytorch LSTM介绍
Lstm是RNN网络中最有趣的结构之一,不仅仅使得模型可以从长序列中学习,还创建了长短期记忆模块,模块中所记忆的数值在需要时可以得到更改。
-
遗忘门
遗忘单元可以将输入信息和隐藏信息进行信息整合,并进行信息更替,更替步骤如右图公式,其中与乘上权重矩阵后,加上偏置项后,经过激活函数,此时输出值为位于[0,1]之间,并将上一个时间步的与激活函数输出值相乘,更新为
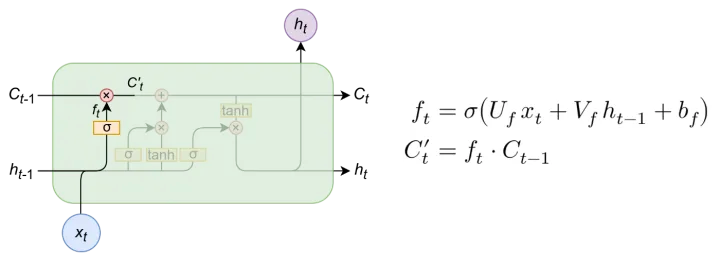
-
输入门
当有输入进入时,输入门会结合输入信息与隐藏信息进行整合,并对信息进行更替
过程与 过程类似,中间公式使用了tanh函数,可以将输出缩放到[-1,1]之间,再更新
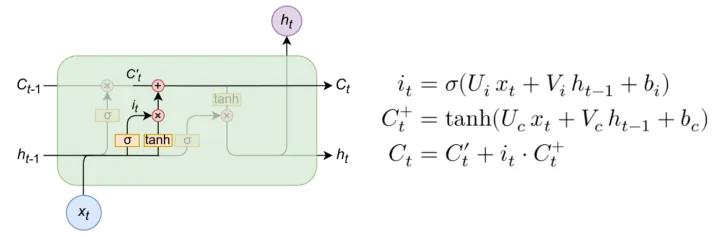
-
输出门
输出门也会对输出过程进行控制,与输入门不同的是,输出门使用tannh激活函数
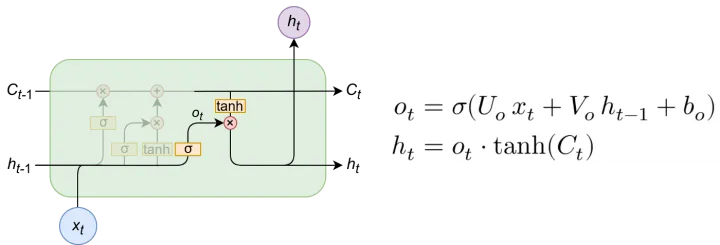
1.2 LSTM递推公式
pytorch的lstm递推公式如下图所示。
在pytorch中,4个权重矩阵Wii,Wif,Wig,Wio被合并为一个权重矩阵Wih,Whh也类似,方便一步计算。

1.3 python实现手动lstm
可以根据公式简单的写出手动实现的版本
这是一个两层的lstm,w和b都写死了,就是固定两层的参数。hidden为1024.
def test_lstm(input, wih0, bih0, whh0, bhh0, wih1, bih1, whh1, bhh1):
# 手动模拟
B, T, F = input.shape
hidden_size = 1024
inp_pointer = input
for layer in range(2):
h_t, c_t = (torch.zeros(B, hidden_size).cuda(), torch.zeros(B, hidden_size).cuda())
output = torch.zeros(B, T, hidden_size).cuda()
batch, time, freq = output.shape
if layer == 0:
cur_w_ih = wih0
cur_w_hh = whh0
cur_b_ih = bih0
cur_b_hh = bhh0
else:
cur_w_ih = wih1
cur_w_hh = whh1
cur_b_ih = bih1
cur_b_hh = bhh1
for t in range(time):
x_t = inp_pointer[:, t, :]
gates = x_t @ cur_w_ih.T + cur_b_ih + h_t @ cur_w_hh.T + cur_b_hh
i_t, f_t, g_t, o_t = (
torch.sigmoid(gates[:, :hidden_size]), # input
torch.sigmoid(gates[:, hidden_size:hidden_size * 2]), # forget
torch.tanh(gates[:, hidden_size * 2:hidden_size * 3]),
torch.sigmoid(gates[:, hidden_size * 3:]), # output
)
c_t = f_t * c_t + i_t * g_t
h_t = o_t * torch.tanh(c_t)
output[:, t, :] = h_t
inp_pointer = output
return inp_pointer
另外,还实现了一个双向LSTM的版本,用了一个小样本进行测试,同样参数都是写死了。
def test_lstm():
input_size = 4
hidden_size = 6
num_layer = 2
bidirectional = True
direction = 2 if bidirectional else 1
input = torch.Tensor([[[[0.896227, 0.713551],
[0.605188, 0.0700275],
[0.827175, 0.186436]],
[[0.872269, 0.032015],
[0.259925, 0.517878],
[0.224867, 0.943635]]],
[[[0.290171, 0.0767354],
[0.251816, 0.31538],
[0.828251, 0.730255]],
[[0.24641, 0.757985],
[0.354927, 0.694123],
[0.990138, 0.946459]]]]).float().transpose(1, 2).reshape(2, 3, 4)
B, T, F = input.shape
lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layer, batch_first=True,
bidirectional=bidirectional)
state = OrderedDict()
state['weight_ih_l0'] = torch.ones([4 * hidden_size, input_size])
state['weight_hh_l0'] = torch.ones([4 * hidden_size, hidden_size]) * 2
state['bias_ih_l0'] = torch.zeros(4 * hidden_size) + 0.5
state['bias_hh_l0'] = torch.zeros(4 * hidden_size) + 1.0
state['weight_ih_l1'] = torch.ones([4 * hidden_size, hidden_size * direction]) * 2
state['weight_hh_l1'] = torch.ones([4 * hidden_size, hidden_size]) * 3
state['bias_ih_l1'] = torch.zeros(4 * hidden_size) + 0.5
state['bias_hh_l1'] = torch.zeros(4 * hidden_size) + 1.0
state['weight_ih_l0_reverse'] = torch.ones([4 * hidden_size, input_size])
state['weight_hh_l0_reverse'] = torch.ones([4 * hidden_size, hidden_size]) * 2
state['bias_ih_l0_reverse'] = torch.zeros(4 * hidden_size) + 0.5
state['bias_hh_l0_reverse'] = torch.zeros(4 * hidden_size) + 1.0
state['weight_ih_l1_reverse'] = torch.ones([4 * hidden_size, hidden_size * direction]) * 2
state['weight_hh_l1_reverse'] = torch.ones([4 * hidden_size, hidden_size]) * 3
state['bias_ih_l1_reverse'] = torch.zeros(4 * hidden_size) + 0.5
state['bias_hh_l1_reverse'] = torch.zeros(4 * hidden_size) + 1.0
lstm.load_state_dict(state, strict=False)
# 手动模拟
inp_pointer = input
for layer in range(num_layer):
h_t, c_t = (torch.zeros(B, hidden_size), torch.zeros(B, hidden_size))
h_t_reverse, c_t_reverse = (torch.zeros(B, hidden_size), torch.zeros(B, hidden_size))
output = torch.zeros(B, T, hidden_size)
output_reverse = torch.zeros(B, T, hidden_size)
batch, time, freq = output.shape
cur_w_ih = state['weight_ih_l{}'.format(layer)]
cur_w_ih_reverse = state['weight_ih_l{}_reverse'.format(layer)]
cur_w_hh = state['weight_hh_l{}'.format(layer)]
cur_w_hh_reverse = state['weight_hh_l{}_reverse'.format(layer)]
cur_b_ih = state['bias_ih_l{}'.format(layer)]
cur_b_ih_reverse = state['bias_ih_l{}_reverse'.format(layer)]
cur_b_hh = state['bias_hh_l{}'.format(layer)]
cur_b_hh_reverse = state['bias_hh_l{}_reverse'.format(layer)]
for t in range(time):
x_t = inp_pointer[:, t, :]
r_t = inp_pointer[:, time - t - 1, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









