






这篇文章专注于图像补全任务,目的是补全给定上下文信息的不完整图像的缺失区域。深度生成模型的最新发展为图像合成和图像修复任务提供一个高效的端到端框架,但现有的基于生成模型的方法并没有利用分割信息来约束补全目标的形状,这通常会导致补全结果的边界模糊的情况。为了解决这一问题,我们提出引入语义分割信息,以分离图像嵌入过程中的类间差异和类内变化。这导致了语义不同区域之间更清晰的恢复边界,以及语义一致的段内更好的纹理。我们的模型将图像分割过程分解为分割预测(SP-NET)和分割引导(SG-NET)两个步骤,首先对缺失区域的分割标签进行预测,然后生成分割引导的补全结果。
在这项任务中,我们的目标不仅是用现实的细节来填充可信的上下文,而且要使所补全的区域与上下文和边界相一致(也就是边界清晰)。

我们的整个框架包含如图2所示的三个步骤,首先,我们使用Deeplabv3从输入待补全图像
I
0
I_{0}
I0开始生成语义分割图像
S
0
S_{0}
S0。然后利用分割预测网络(SP-Net)对
I
0
I_{0}
I0和
S
0
S_{0}
S0进行预测得到语义标签的补全结果
S
R
S_{R}
SR,让后将
S
R
S_{R}
SR传给分割指导网络(SG-Net)预测最终结果
I
I
I。
Segmentation Prediction Network (SP-Net)
网络结构
SP-Net的目标是对分割标签进行补全。SP-Net的输入是256×256×C的不完整语义分割标签 S 0 S_{0} S0和256×256×3的缺失图像 I 0 I_{0} I0,其中 C C C是标签类别的数量,输出是大小为256×256×C的分割标签映射 S S S的预测。SP-Net的生成器是基于FCN的,但用残差块代替了膨胀卷积,可以提供更好的学习能力。渐进扩张因子用于增加感受野,并提供更广泛的输入视图来捕捉图像的整体结构。更具体地说,我们的生成器由4个下采样卷积层、9个残差块和4个上采样卷积层组成。卷积核大小在第一层和最后一层为7,在其他层为3。9个残差块中,前三个的扩张因子为2,接下去3块为4,最后的3块为8。下采样层和上采样层的输出通道分别为64、128、256、512和512、256、128、64,而残差块的输出通道均为512。除了产生最终结果的最后一层外,每个卷积层之间都使用ReLU和Batch归一化层。最后一层使用一个softmax函数来生成一个概率映射,它可以预测每个像素的分割标签的概率。
损失函数
对抗性损失函数是由鉴别器网络给出的,用来判断生成的图像是否是真图。然而,一个单一的GAN鉴别器还不足以产生一个清晰且真实的结果,为它需要同时考虑全局视图和局部视图。为了解决这个问题,我们使用了类似【37】的多尺度鉴别器,他们具有相同的网络结构,但可以在三种不同的图像分辨率尺度上运行。每个鉴别器都是一个全卷积的PatchGAN【15】,有4个下采样层,然后是一个sigmoid函数产生一个real/fake预测向量,其中每个值对应于原始图像中的一个局部补丁。通过多尺度应用,鉴别器,即
{
D
1
,
D
2
,
D
3
}
\{D_{1},D_{2},D_{3} \}
{D1,D2,D3},将对应的输入分别从原始图像下采样1、2、4倍,能够对不同尺度下的全局和局部补丁进行分类,使生成器能够捕获全局结构和局部纹理。对抗损失可以定义为:

感知损失一般用来提高图像生成结果的分辨率,由于输入图像是带有
C
C
C通道的标签映射,我们不能将感知损失应用于预先训练的模型,该模型通常以图像作为输入。因此,一种更合理的方法是从生成器和鉴别器的多层中提取特征映射来匹配中间表示。具体来说,知觉损失被写成:
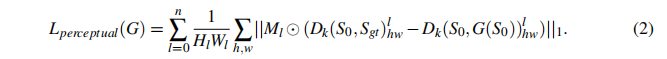
这里的
l
l
l代表特征层,
⊙
\odot
⊙代表像素级乘法,
M
l
M_{l}
Ml代表第
l
l
l层的掩膜。
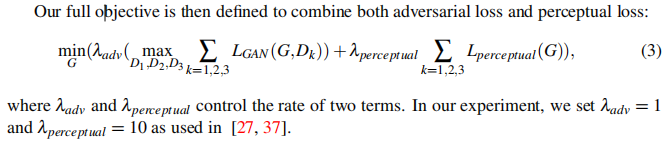
Segmentation Guidance Network (SG-Net)
网络结构
SG-Net的目标是预测256×256×3的图像的缺失区域的补全结果 I I I。它以一个256×256×3的不完整图像 I 0 I_{0} I0和SP-Net预测的分割标签图 S S S相结合作为输入。SG-Net与SP-Net共享类似的体系结构,有4个下采样卷积层、9个残差块和4个上采样层。与SP-Net不同的是,最后一个卷积层使用一个tanh函数生成一个像素值范围在[−1,1]的图像,然后将其重新缩放到正常图像值。
损失函数
除了SP-Net中的损失函数外,SG-Net还引入了一个额外的感知损失来稳定训练过程。 传统的感知损失通常使用VGG-Net,并计算不同特征层上的
l
2
l_{2}
l2距离。 【44】提出训练一个基于ALexNet的感知网络来测量两个图像补丁之间的感知差异,并表明AlexNet在反应人类感知判断方面的表现更好。这里,我们通过考虑局部补丁来扩展损失函数。基于AlexNet的新感知损失定义为:

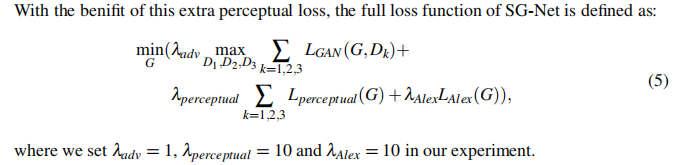
实现展示


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









