







作者 | 老表
来源 | 简说Python(ID:xksnh888xksnh888)
【导语】在今天这篇文章中,作者分享给大家一个有趣又干货满满的 Python 项目。通过这份教程,大家不仅又多了一个动手项目,还可以用 Python 破解图片验证码里的文字识别,十足的技术范儿。
文章目录
前期准备
(1)安装包,直接在终端上输入pip指令即可:
(2)新建项目
知识
(1)Pillow 中的 Image
(2)基于 Tesseract-OCR 的 pytesseract
小项目:破解图片验证码登陆
(1)准备过程
(2)代码敲起来
(3)运行结果
总结
前期准备
(1)安装包,直接在终端上输入pip指令即可:
# 发送浏览器请求
pip3 install requests
# 文字识别
pip3 install pytesseract
# 图片处理
pip3 install Pillow(2)新建项目
需要的模块安装好后,新建一个项目wordsDistinguish,在项目包下新建三个.py文件——test_pytesseract 和 test_pillow、case_verification。
test_pytesseract:模块 pytesseract 的基本使用测试
test_pillow:模块 Pillow 的基本使用测试
case_verification:实战案例,破解网站图片验证码验证
知识知识
(1)Pillow 中的 Image
Python图像库中最重要的类是 Image,在模块中定义的具有相同名称的类。可以通过多种方式创建此类的实例; 通过从文件加载图像,处理其他图像或从头开始创建图像。
# -*- coding: utf-8 -*-
"""
@author = 老表
@date = 2019-08-16
@个人公众号 : 简说Python
"""
# 注意:print_function的导入必须在Image之前,否则会报错
from __future__ import print_function
from PIL import Image
"""
pillow 模块 中 Image 的基本使用
"""
# 1.打开图片
im = Image.open("../wordsDistinguish/test1.jpg")
print(im)
# 2.查看图片文件内容
print("图片文件格式:"+im.format)print("图片大小:"+str(im.size))
print("图片模式:"+im.mode)
# 3.显示当前图片对象
im.show()
# 4.修改图片大小,格式,保存
size = (50, 50)
im.thumbnail(size)
im.save("1.jpg", "PNG")
# 5.图片模式转化并保存,L 表示灰度 RGB 表示彩色
im = im.convert("L")
im.save("test1.jpg")(2)基于 Tesseract-OCR 的 pytesseract
Python-tesseract是python的光学字符识别(OCR)工具。也就是说,它将识别并“读取”嵌入图像中的文本。
Python-tesseract是Google的Tesseract-OCR引擎的包装器。它作为独立的调用脚本也很有用,因为它可以读取Pillow和Leptonica成像库支持的所有图像类型,包括jpeg,png,gif,bmp,tiff等。此外,如果用作脚本,Python-tesseract将打印已识别的文本,而不是将其写入文件。
要在你的电脑上使用pytesseract模块,你还需要安装 Tesseract-OCR ,Mac上安装该工具我比较建议使用Homebrew,安装好后,直接在终端输入下面指令即可:
Windows下安装的话直接下载包即可,然后把其加入系统环境变量(即加入Path里),比较傻白甜,可以百度一下。
# -*- coding: utf-8 -*-
"""
@author = 老表
@date = 2019-08-16
@个人公众号 : 简说Python
"""
# 从 Pillow 中导入图片处理模块 Image
from PIL import Image
# 导入基于 Tesseract 的文字识别模块 pytesseract
import pytesseract
"""
@pytesseract:https://github.com/madmaze/pytesseract
"""
# 打开图片
im = Image.open("../wordsDistinguish/Resources/1.jpg")
# 识别图片内容
text = pytesseract.image_to_string(im)
print(text)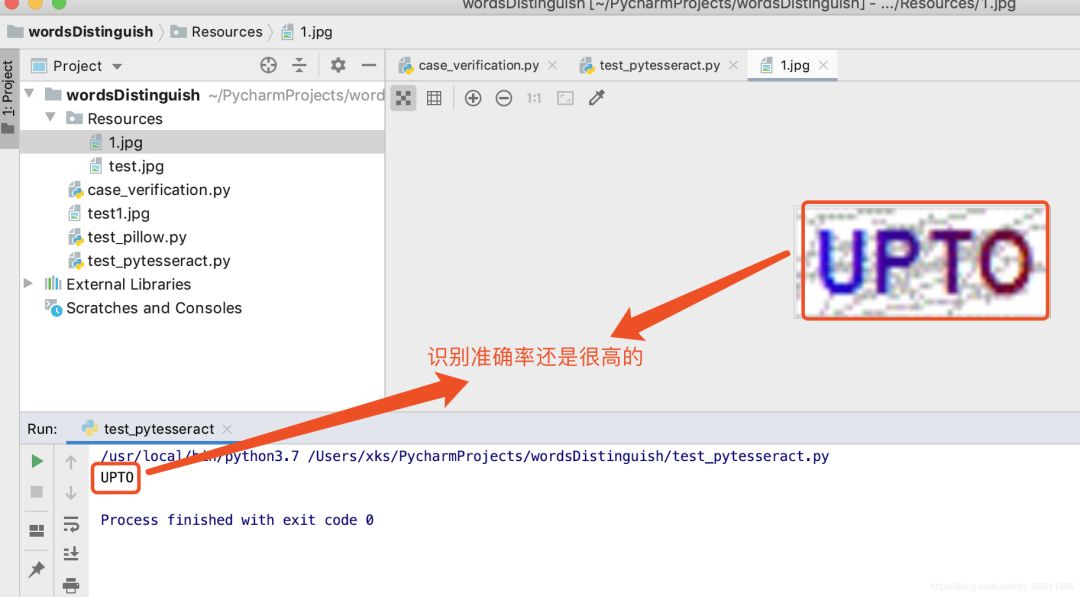
小项目:破解图片验证码登陆
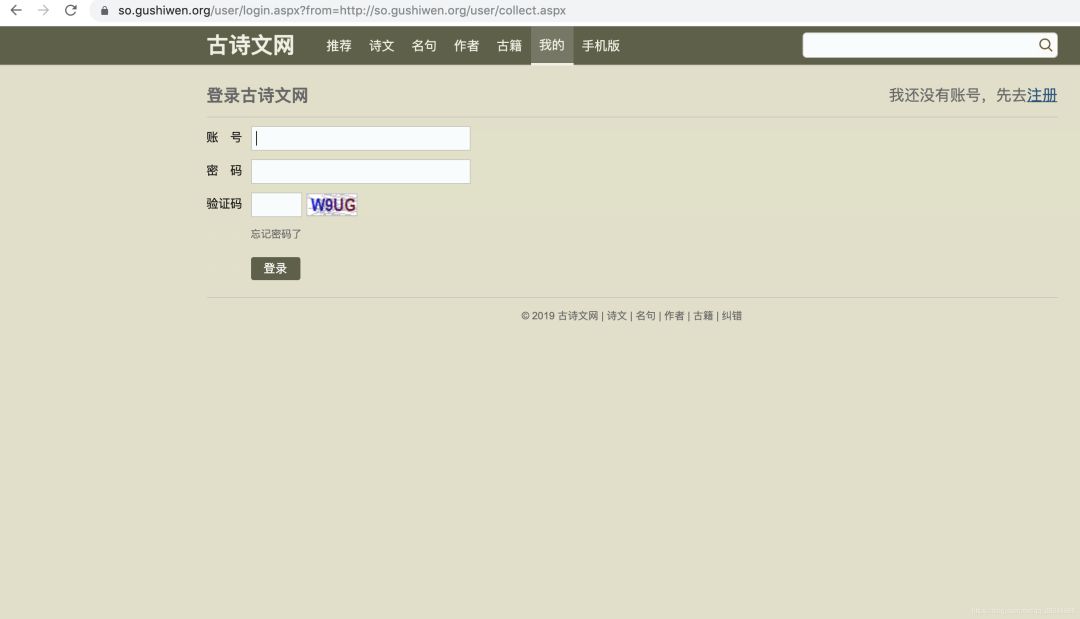
目标网站:
https://so.gushiwen.org
(1)准备过程
登录过程中需要输入三个数据:账号、密码、验证码,首先在浏览器内实际登录一次,按F12查看登录流程。
输入账号密码,和验证码,点击登录,注意Network内的变化。
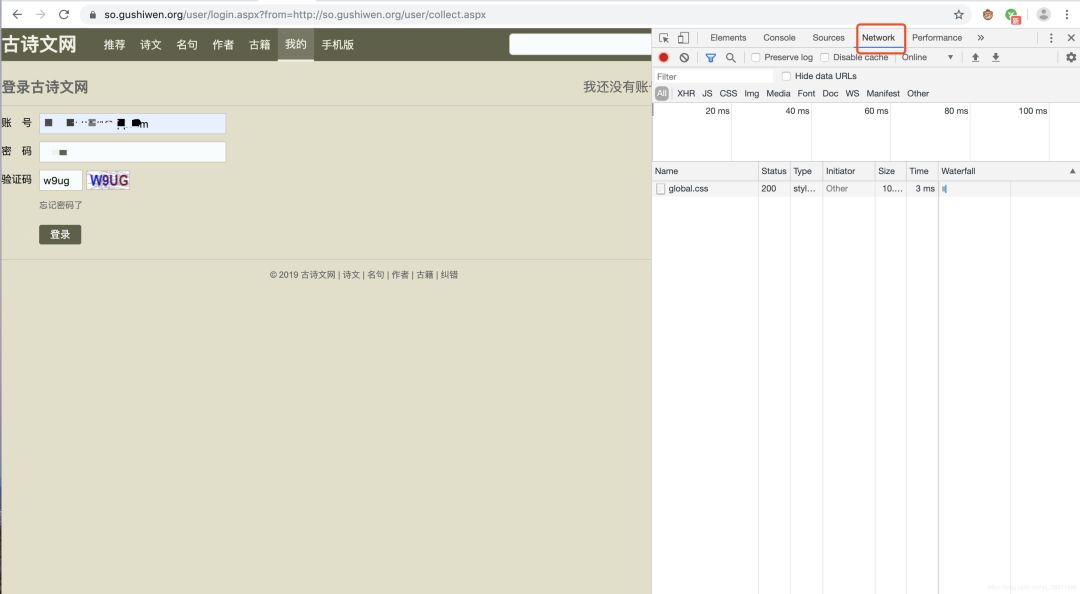
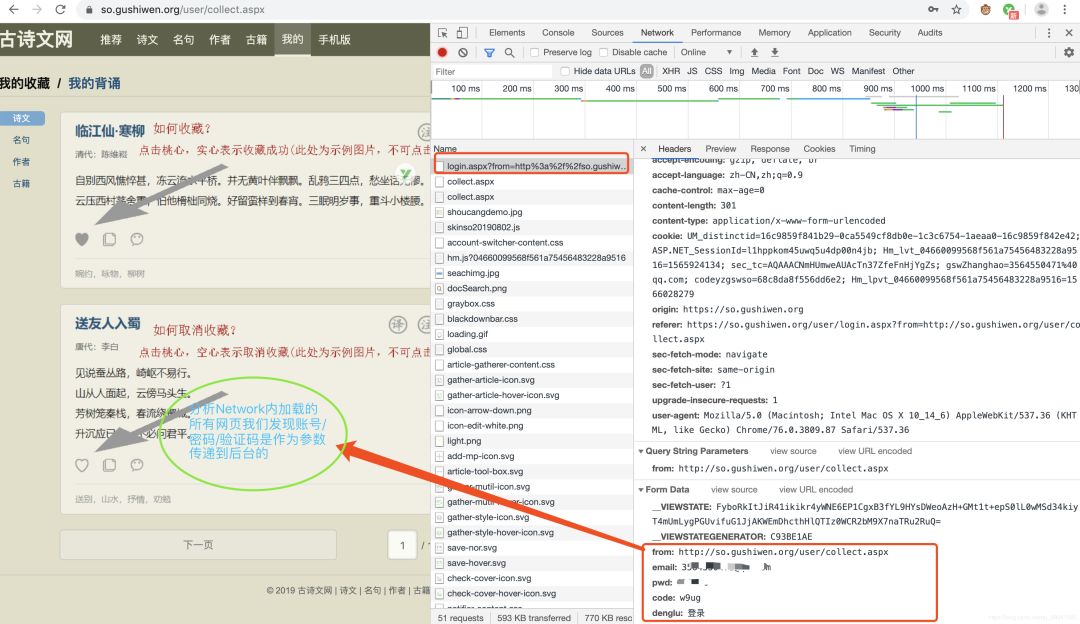
登录后,分析Network内加载的网页我们发现,在login.aspx里,传递了我们的登录信息,这是关键,意味着我们只要把数据通过这个地址传递给服务器就可以实现登录了。
(2)代码敲起来
现在模拟登录过程的难点主要有:验证码的识别和传递。
a.验证码识别我们根据前面的知识知识里的,直接采用pytesseract模块。
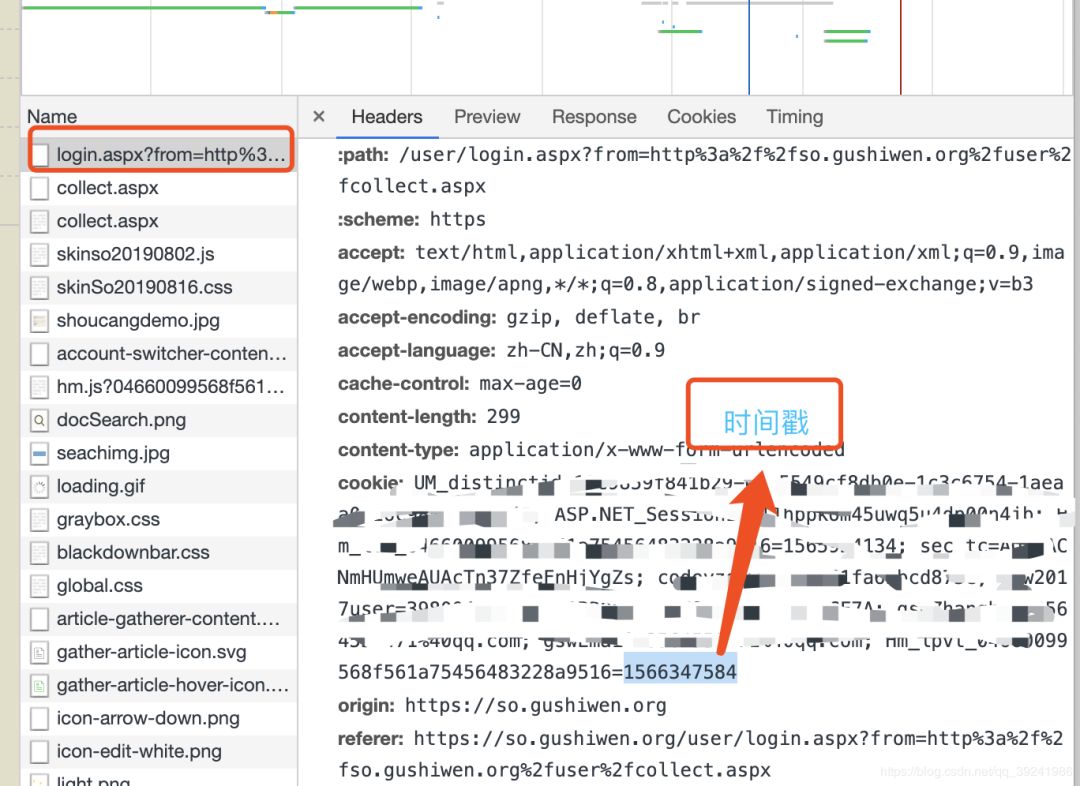
b.登录参数传递,利用requests库发送post请求即可,问题是如何把验证码和登录联系起来,通过前面分析我们知道验证码是在“https://so.gushiwen.org/RandCode.ashx”里生成的,而登录页面是“https://so.gushiwen.org/user/login.aspx”,分析发现,正常浏览器登录这两个网址的cookie是一致的,并且都带有时间戳,所以,只要在代码请求时保证两者的cookie一致即可,这里我们利用requests库的session方法可以实现。
# -*- coding: utf-8 -*-
"""
@author = 老表
@date = 2019-08-16
@个人公众号 : 简说Python
"""
# 从 Pillow 中导入图片处理模块 Image
from PIL import Image
# 导入基于 Tesseract 的文字识别模块 pytesseract
import pytesseract
# 导入发送网络请求的库 requests
import requests
# 导入正则库 re
import re
"""
模拟登录,破解字母数字图片验证码
目标网站:https://so.gushiwen.org
"""
# 请求头
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36"
}
# 通过requests 创建一个 session 会话,保持两次访问 cookie 值相同
session = requests.session()
# 下载识别验证码图片函数
def get_verification():
# 生成验证码图片url
url = "https://so.gushiwen.org/RandCode.ashx"
# 通过session发送get请求,获取验证码
resp = session.get(url, headers=headers)
# 将验证码保证到本地
with open(r"../wordsDistinguish/Resources/test.jpg", 'wb') as f:
f.write(resp.content)
# 打开验证码图片文件
im = Image.open(r"../wordsDistinguish/Resources/test.jpg")
# 基本处理,灰度处理,提升识别准确率
im = im.convert("L")
# 保存处理后的图片
im.save("test.jpg")
# 利用pytesseract进行图片内容识别
text = pytesseract.image_to_string(im)
# 去除识别结果中的非数字/字母内容
text = re.sub("\W", "", text)
# 返回验证码内容
return text
def do_login():
i = 0 # 识别错误次数
# 获取验证码
captcha = get_verification()
# 基本检验,验证码位数必须为四位
while len(captcha) != 4:
captcha = get_verification()
i = i + 1 # i+=1
print("第%d次识别错误" % i)
print("开始登录,验证码为:"+captcha)
# 传递的登录参数
data = {
"from": "http://so.gushiwen.org/user/collect.aspx",
"email": "你的注册邮箱",
"pwd": "你的登录密码",
"code": captcha,
"denglu": "登录"
}
# 登录地址
url = "https://so.gushiwen.org/user/login.aspx"
# 利用 session 发送post请求
response = session.post(url, headers=headers, data=data)
# 打印登录后的状态码
print(response.status_code)
# 保存登录后的页面内容,进一步确认是否登录成功
with open("gsww.html", encoding="utf-8", mode="w") as f:
f.write(response.content.decode())
# 开始程序
if __name__ == "__main__":
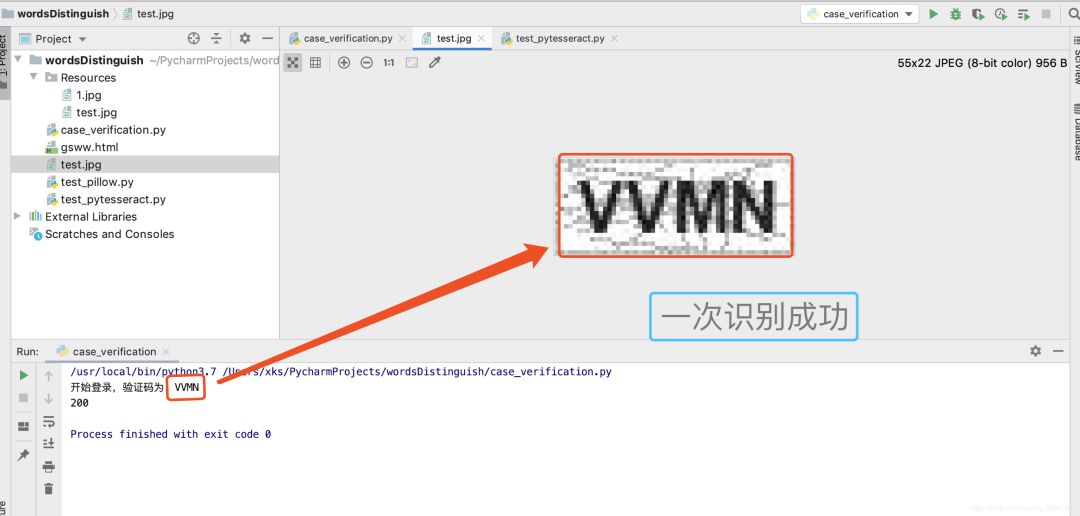
do_login()a.控制台显示一次验证成功,返回状态码为:200,访问正常。
b.进一步检查,对获取到的源码进行检查
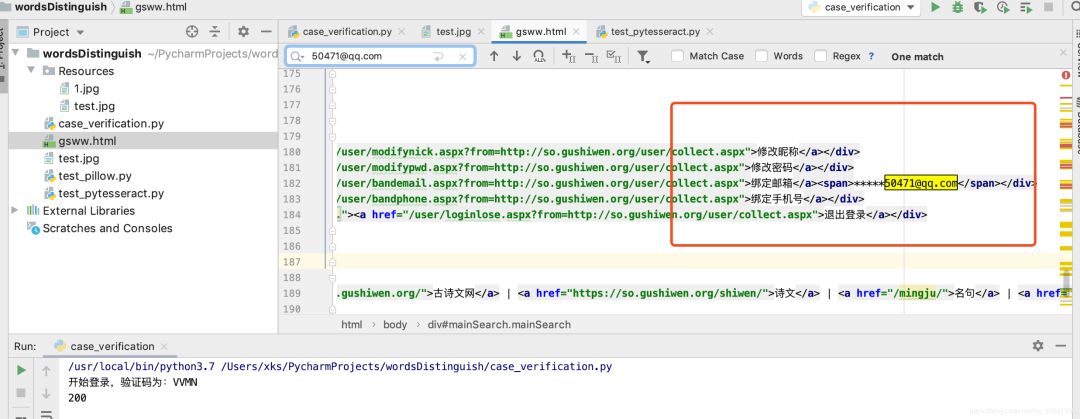
我们在浏览器观察登录后的页面发现,只有登录后的页面才有账号管理模块,其中有用户的唯一标识:绑定邮箱的后几位,我的是50471@qq.com。
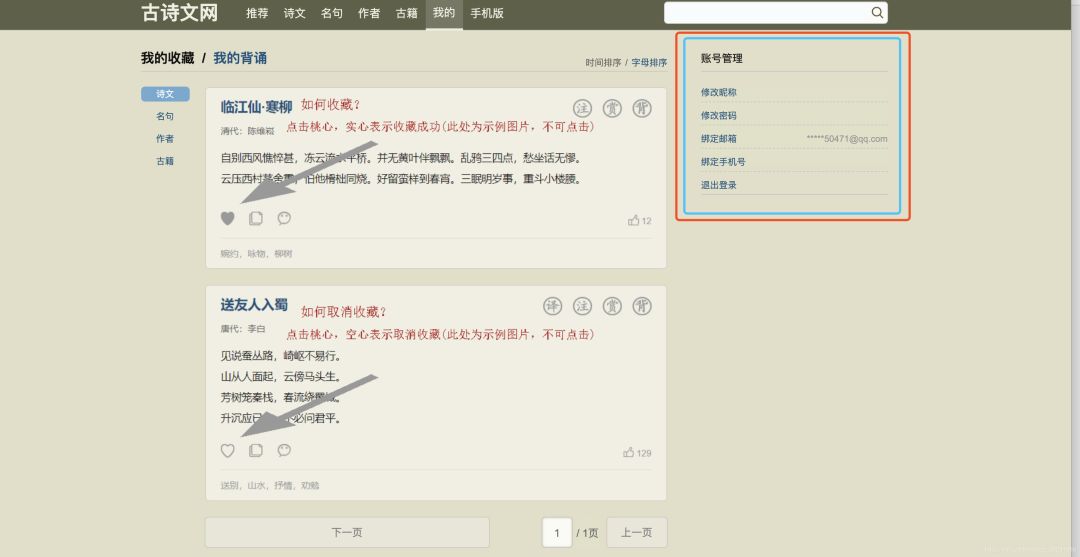
所以在我们获取的源码里直接搜索50471@qq.com即可查明是否登录成功,我们发现可以查询到,即模拟登录成功了。
总结
(1)本文核心在于给大家介绍文字识别模块pytesseract,希望大家多多查看官方文档,仔细了解该模块,大有用处,后面有涉及项目我也会再次写文介绍。
(2)选择的实战案例网站,我是多方询问网友后从十多个网站中选出来的,这个网站看着比较简单,验证码图片加密难度也不是特别高,所以比较适合做为初次相见的实战案例。
(3)图片识别再往难一点,需要进行图片的细节处理,在案例中我只对图片进行了基本的灰度处理,使深色更容易别识别,一定程度可以提高识别准确率,依然会出现识别错误情况,可以去除噪声点,根据图片中的色素来,去掉部分低色素点,进一步提高识别准确率,还可以多下载图片验证码,取训练模型等方法。
最后希望大家能跟着作者的方法和代码,自己也上手一把,如果有问题可以在评论区留言~
(*本文为 Python大本营转载文章,转载请联系微信 1092722531)
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!

AI ProCon 2019 邀请到了亚马逊首席科学家@李沐,在大会的前一天(9.5)亲授「深度学习实训营」,通过动手实操,帮助开发者全面了解深度学习的基础知识和开发技巧。还有 9大技术论坛、60+主题分享,百余家企业、千余名开发者共同相约 2019 AI ProCon!距离5折优惠票结束还有5天!

推荐阅读

你点的每个“在看”,我都认真当成了喜欢















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









