







作者 | 终身学习者,大学教师。阿里云栖社区专家,北得克萨斯大学访问学者。喜爱鼓捣 Python 和数据。
来源 | 玉树芝兰(公众号id:nkwangshuyi)
责编 | Jane
【编者按】本文作者是 Python大本营的合作作者王树义老师。近日,王老师应主办方 TechMill 邀请,参加了在达拉斯公共图书馆举行的“达拉斯-沃斯堡开放数据日”(DFW Open Data Day)。利用 NCTCOG 提供的新 Waze 数据,王老师改进了之前在 HackNTX 2018 做的深度学习模型,取得了不小的进展。此外,老师还参加了这次活动的主题报告,给我们带来了现场报告的收获。老师还将方法换成用 Python 和数据分析包 Pandas 对该数据集进行分析和可视化。希望通过这个例子,让大家了解开放数据的获取、整理、分析和可视化。

前言
主题报告人是 Richard ,他给参会的部分人员讲解了开放数据的定义、用途和使用方法。虽然从2013年开始,我就在课程中为学生们讲解开放数据。但是从他的报告中,我依然收获了很多东西。例如说,美国联邦政府和地方当局为什么要在网站上开放这么多数据?要知道,一旦数据开放出来,普通人是可以对数据进行组织、包装和再分发,甚至是可以赚取经济利益的。

Richard 告诉我们,如果许多人都要求提供某一项数据,公务人员就有很大的动力把数据直接发布出来。因为这样,可以避免数据请求的巨大压力。我把 Richard 的报告幻灯放在了“延伸阅读”模块里。如果你感兴趣,可以在读过本文后访问浏览。
Richard 还当场带领大家,以 Denton 市的犯罪记录开放数据为例,用 Excel 加以分析。虽然“犯罪记录”听上去很让人不安。但是这种数据的公开,可以让大众了解到某个城市或者地区的治安情况。对于人们择业、选房、投资,甚至是日常出行和活动等决策,都可以提供辅助参考。从这个讲座中,我收获良多。
接下来,王老师就带领大家如何用 Python 和数据分析包 Padas 对书籍进行分析与可视化。希望大家可以举一反三,把这种能力,应用到更多的数据集上,获得对数据的洞见。
数据
首先,访问 Denton 开放数据主页,地址是
http://data.cityofdenton.com/
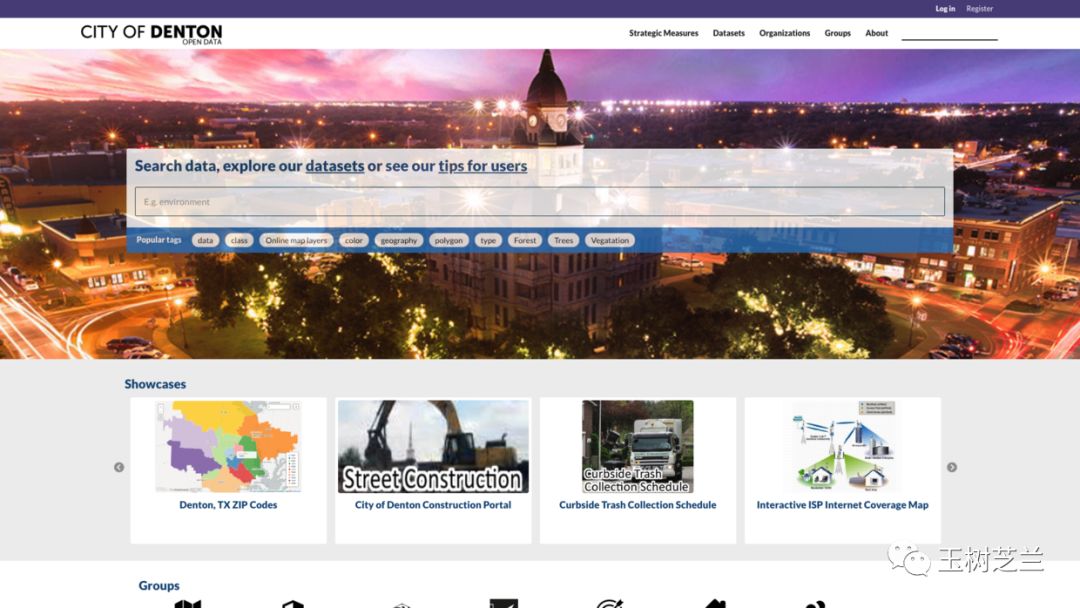
首页就有搜索栏,我们可以输入“crime”(犯罪)进行查询。
这是返回的搜索结果。
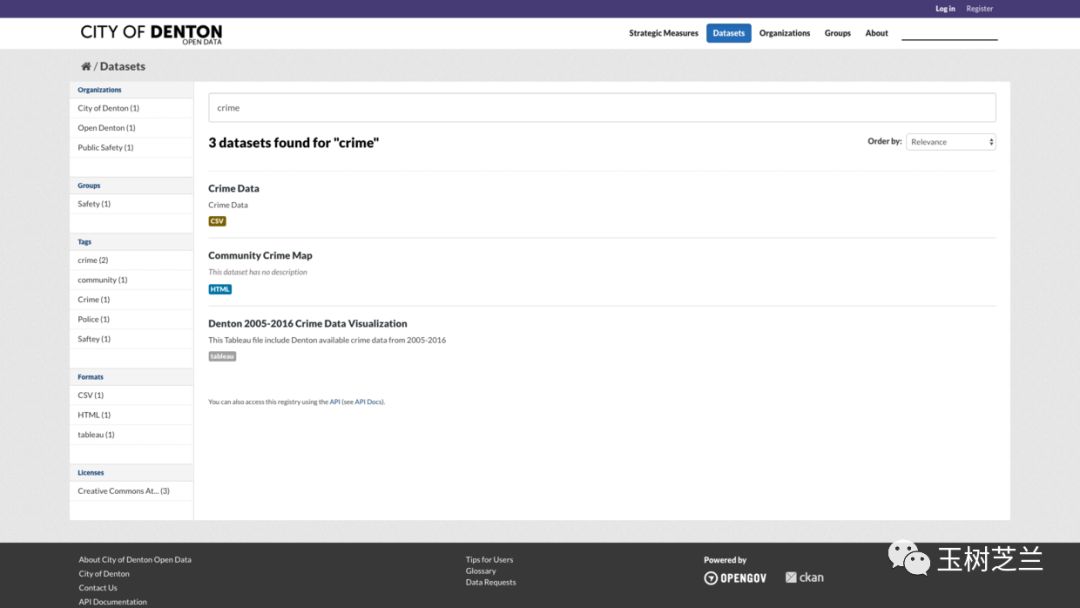
结果不仅包含数据名称,还有数据类型。第一条是 csv 格式,最符合我们分析的需求,因此我们点击第一项链接。
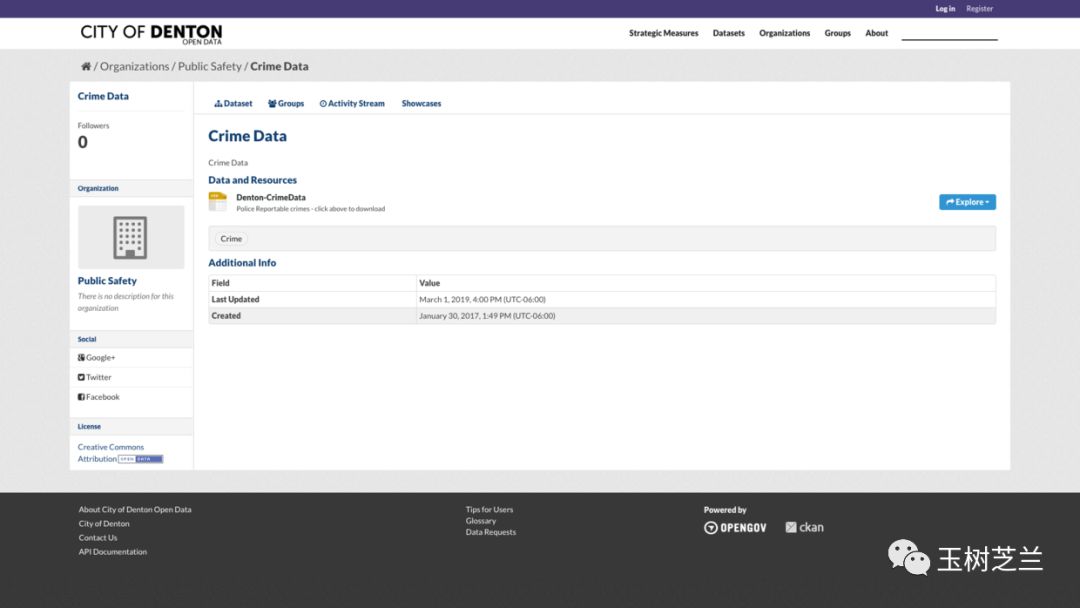
在这个页面,我们点击右侧蓝色“explore”旁边的下拉按钮,可以看到“预览”和“下载”选项。我们可以直接下载数据集。但此处请你复制下载链接,放到笔记软件或者编辑器里面,备用。
环境
本文的配套源代码,我放在了 Github 项目中。请你点击这个链接访问
http://t.cn/EIKS05O
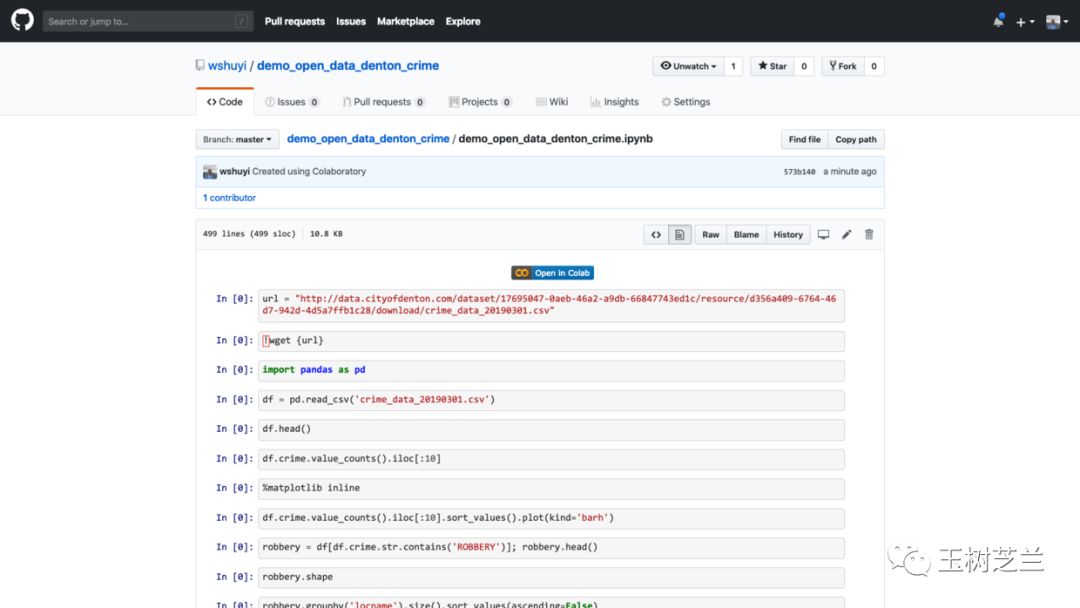
如果你对我的教程满意,欢迎在页面右上方的 Star 上点击一下,帮我加一颗星。谢谢!
注意这个页面的中央,有个按钮,写着“在 Colab 打开”(Open in Colab)。请你点击它。
然后,Google Colab 就会自动开启。
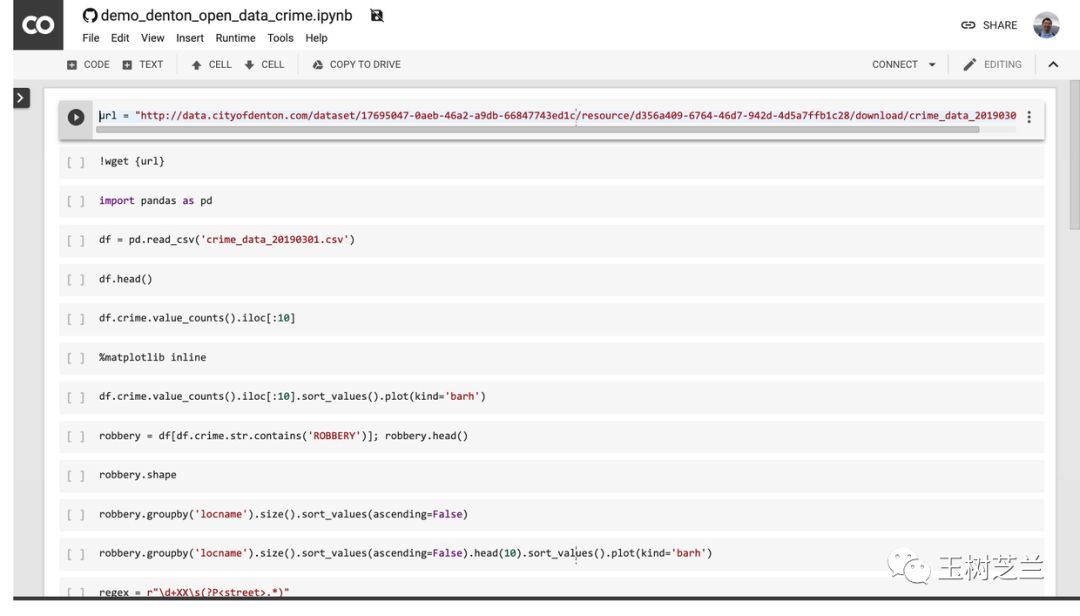
Colab 为你提供了全套的运行环境。你只需要依次执行代码,就可以复现本教程的运行结果了。如果你对 Google Colab 不熟悉,没关系。我这里有一篇教程,专门讲解 Google Colab 的特点与使用方式。为了你能够更为深入地学习与了解代码,我建议你在 Google Colab 中开启一个全新的 Notebook ,并且根据下文,依次输入代码并运行。在此过程中,充分理解代码的含义。
这种看似笨拙的方式,其实是学习的有效路径。
代码
首先,将我们前面获取到的数据下载地址,存入到 url 变量中。
url = "http://data.cityofdenton.com/dataset/17695047-0aeb-46a2-a9db-66847743ed1c/resource/d356a409-6764-46d7-942d-4d5a7ffb1c28/download/crime_data_20190301.csv"
然后,利用 wget 命令,把 csv 格式的数据下载到本地。
!wget {url}
crime_data_20190301 100%[===================>] 9.22M 8.22MB/s in 1.1s
2019-03-04 02:31:39 (8.22 MB/s) - ‘crime_data_20190301.csv’ saved [9667384/9667384]
读入 Pandas 软件包。
import pandas as pd
用 Pandas 的 csv 数据格式读取功能,把数据读入,并且存入到 df 变量里面。
df = pd.read_csv('crime_data_20190301.csv')
让我们看看 df 的前几行。
df.head()
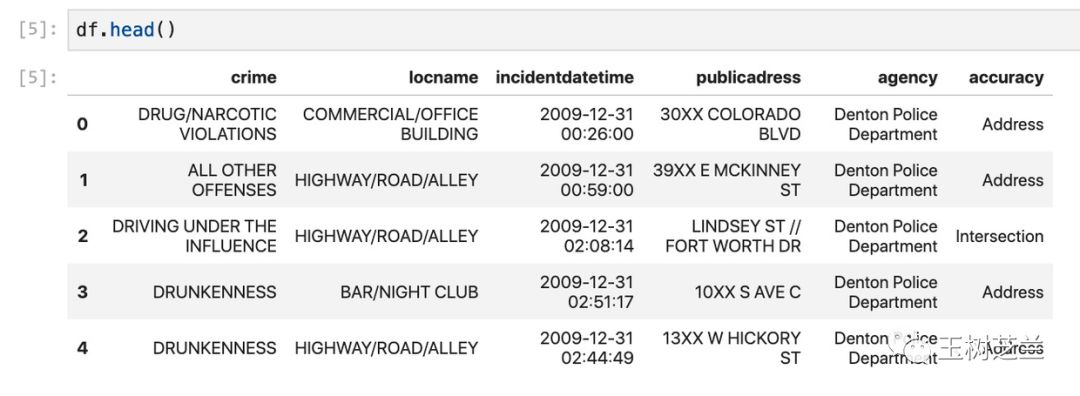
好的,数据已经成功读取。
下面我们来着重分析一下,都有哪些犯罪类型,每种类型下,又有多少记录。
这里我们使用的是 Pandas 中的 value_counts 函数。它可以帮助我们自动统计某一列中不同类别出现的次数,而且还自动进行排序。为了显示的方便,我们只要求展示前10项内容。
df.crime.value_counts().iloc[:10]
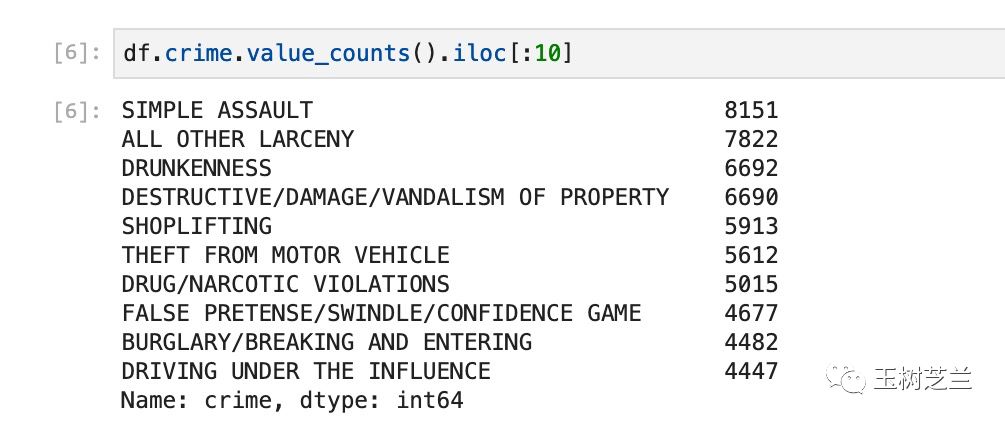
看来, Denton 最主要的犯罪类型,是“轻微人身攻击”(Simple Assault)。“酒醉”(Drunkenness)的次数也不少,排名第三位。
为了更直观查看数据统计结果,我们调用 Pandas 内置的绘图函数 plot ,并且指定绘图类型为“横向条状图”(barh)。
df.crime.value_counts().iloc[:10].sort_values().plot(kind='barh')
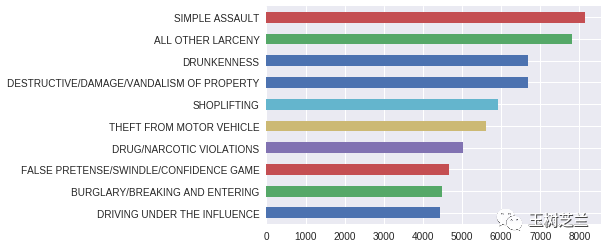
这样看起来,一目了然。
下面,我们着重了解某一种犯罪的情况。因为犯罪类型五花八门,所以我们从中选择一种严重的暴力犯罪——抢劫(Robbery)。
这里,为了后续分析的便利。我们首先把抢劫类型的犯罪单独提炼出来,存储在 robbery 这样一个新的数据框里。
robbery = df[df.crime.str.contains('ROBBERY')]; robbery.head()

我们来看看 robbery 数据框的大小。
robbery.shape
(660, 6)
一共是660条记录,每条记录有6列。
我们查看一下“犯罪位置”(locname)类型,以及每种类型对应的记录条目数。
这次,我们使用 groupby 函数,先把犯罪位置进行分类,然后用 size 函数来查看条目统计。
这里,我们指定排序为从大到小。
robbery.groupby('locname').size().sort_values(ascending=False)
作为练习,希望你可以用 value_counts 函数,自己改写上面的语句。
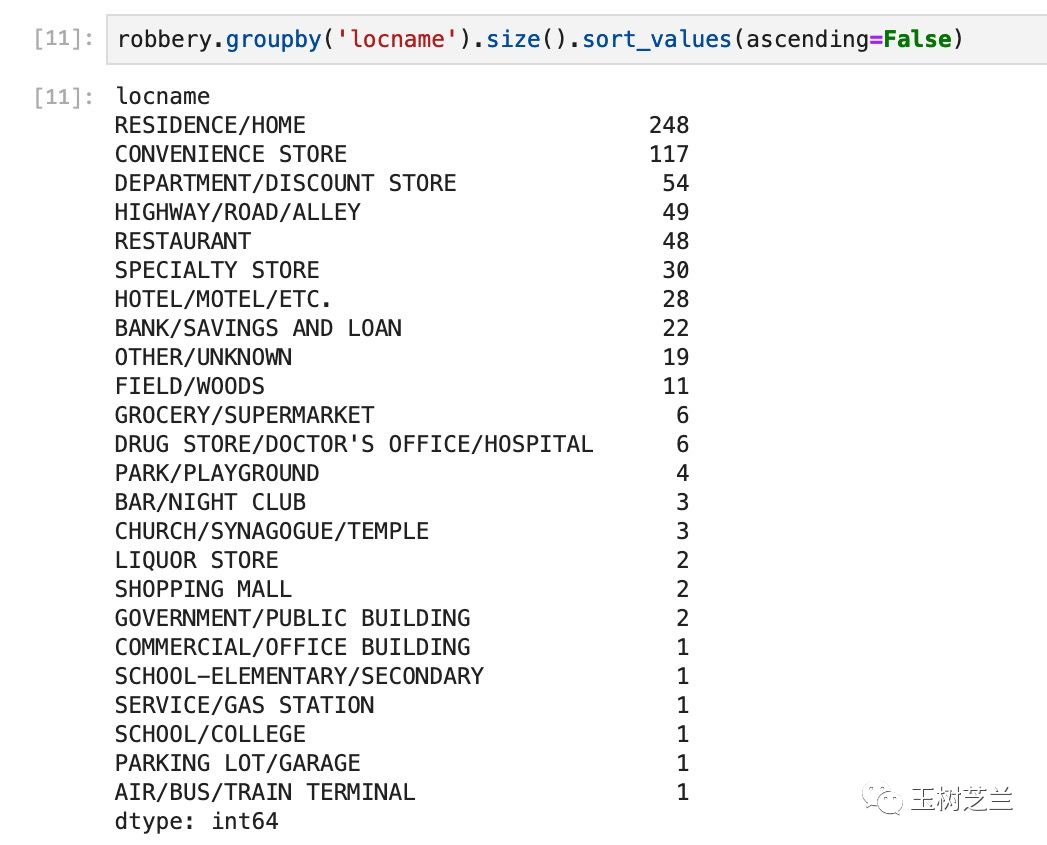
根据结果显示,入室抢劫次数最多,在学校、公交车上发生的次数最少。
下面还是用 plot 函数,把结果可视化呈现。
robbery.groupby('locname').size().sort_values(ascending=False).head(10).sort_values().plot(kind='barh')
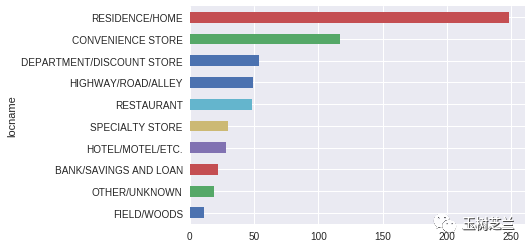
下一步,我们尝试把分析的粒度做得更加细致——研究一下,哪些街区比较危险。
回顾上图中,地址信息都表示为类似“19XX BRINKER RD”这样的方式。把具体地址的后两位隐藏,是为了保护受害者的隐私。
我们如果要统计某一条街道的犯罪数量,就需要把前面的数字忽略,并且按照街道名称加总。
这个处理起来,并不困难,只要用正则表达式即可。
regex = r"\d+XX\s(?P<street>.*)"
subst = "\\g<street>"
这里,我们用括号把需要保留的内容,赋值为 street 分组。然后替换的时候,只保留这个分组的信息。于是前面的具体地址数字就忽略了。
调用 Pandas 的 str.replace 函数,我们可以让它自动将每一个地址都进行解析替换,并且把结果存入到了一个新的列名称,即 street 。
robbery["street"] = robbery.publicadress.str.replace(regex, subst)
看看此时新的 robbery 数据框样子。
robbery.head()
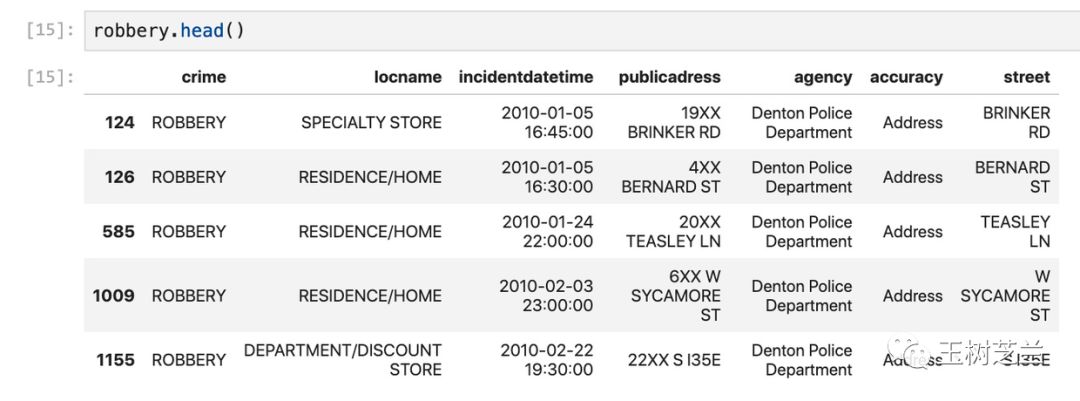
注意最后多出来的一列,确实已经变成了我们希望转换的形式。
依然按照前面的方法,我们分组统计每一条街道上的犯罪数量,并且进行排序。
robbery.groupby('street').size().sort_values(ascending=False).head(10)

看来,大学西道(W University DR)抢劫频发,没事儿最好少去瞎转悠。我住的街道还好,没有出现在前10名的范畴。
注意,我们其实是在分析10年的犯罪信息汇总。如果更进一步,想要利用时间数据,进行切分,我们就得把日期信息做一下转换处理。
这里,请你安装一个特别好用的时间分析软件包 python-dateutil 。我第一次使用的时候,立即决定弃用 datetime 包了。
!pip install python-dateutil
我们从 dateutil 里面的 parser 模块,载入全部内容。
from dateutil.parser import *
下面,我们抽取年度信息。因为目前的日期时间列(incidentdatetime)是个字符串,因此我们可以直接用 parse 函数解析它,并且抽取其中的年份(year)项。
robbery["year"] = robbery.incidentdatetime.apply(lambda x: parse(x).year)
以此类推,我们抽取“月”和“小时”的信息。
robbery["month"] = robbery.incidentdatetime.apply(lambda x: parse(x).month)
robbery["hour"] = robbery.incidentdatetime.apply(lambda x: parse(x).hour)
好了,来看看此时的 robbery 数据框。
robbery.head()

注意后三列是我们刚刚生成的。
我们先按照年度来看看抢劫犯罪数量的变化趋势。
robbery.groupby('year').size()

注意这里,数量最少的是 2019 年。看似是很喜人的变化。可惜我们分析数据的时候,一定要留心这种细节。我们读取的数据,统计时间截止到 2019 年的 3 月初。因此,2019年数据并不全。
所以,比较稳妥的方法,是干脆去掉所有2019年的条目。
robbery = robbery[~(robbery.year == 2019)]
去除后,看看此时的 robbery 数据框。
robbery.shape
(643, 10)
数量没错,恰好少了 17 行。
好了,我们来绘制一下抢劫犯罪数量变化趋势折线图。
Pandas 的 plot 函数,默认状态下,就是绘制折线图。因此我们不需要加入参数。
robbery.groupby('year').size().plot()
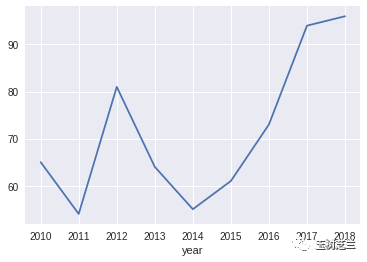
看来,从 2013 到 2016 年的抢劫犯罪形成了一个低谷。近两年的数据,又有上行的趋势。
但是,我们能否就此得出结论,说 Denton 这两年的治安,越来越差了呢?
还不行。
因为考虑犯罪,不能只看绝对数值,还要看相对比例。我这里给你提供一个数据源,请你参考它,进行比例数值计算,修正上面的折线图。
下面,我们比较一下,不同月份之间,是否有明显的抢劫犯罪发生数量差别。
robbery.groupby('month').size().plot(kind='bar')
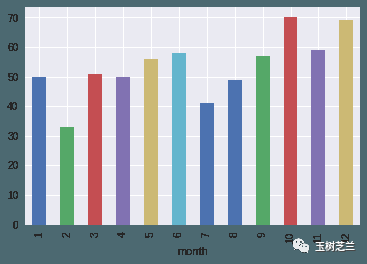
从上图中,可以看到,从 2010 到 2018 年,10月和12月犯罪数量较多,2月和7月相对好一些。
但是,我们可能更加关心近年的情况。因为扔掉了2019年的不完整数据,此时我们能使用的最近年份,是2018。
我们就把2018年的月份犯罪记录统计做可视化。
robbery[robbery.year==2018].groupby('month').size().plot(kind='bar')
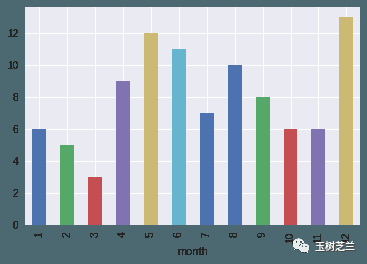
2018年的10月,犯罪数量相对不算高,但12月看来确实是需要注意安全的。
下面我们来看看,抢劫一般发生在什么时间。这次我们用的,是小时(hour)数据。
robbery.groupby('hour').size().plot(kind='bar')
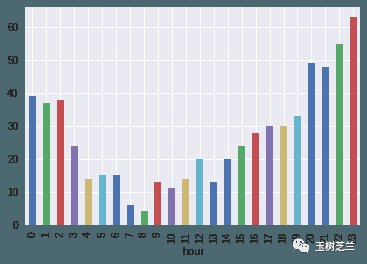
从总体数据看来,每天早上8点,你是不用太担心抢劫的;晚上23点嘛……
我们再看看2018年的情况。
robbery[robbery.year==2018].groupby('hour').size().plot(kind='bar')
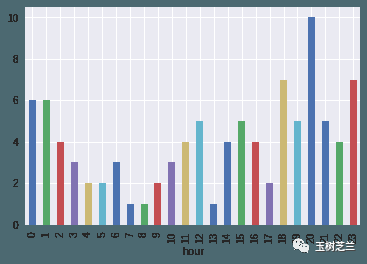
8点依然比较安全。但是最危险的时段,变成了晚上8点多。莫非劫匪们也打算早点儿休息?
如果我们更加小心谨慎,还可以根据不同月份,来查看不同时段的抢劫案件发生数量。
这里,我们把 groupby 里面的单一变量,换成一个列表。于是 Pandas 就会按照列表中指定的顺序,先按照月份分组,再按照小时分组。
robbery[robbery.year==2018].groupby(['month', 'hour']).size()

但是这样的统计结果,无法直接绘制。我们需要做一个变换。这里用的是 Pandas 中的 unstack 函数,把内侧的分组索引(hour)转换到列上。
robbery[robbery.year==2018].groupby(['month', 'hour']).size().unstack(0)

因为许多时间段,本来就没有抢劫案件发生,所以这个表中,出现了许多空值(NaN)。我们根据具体情况,采用0来填充。Pandas 中数据填充的函数是 fillna。
robbery[robbery.year==2018].groupby(['month', 'hour']).size().unstack(0).fillna(0)

好了,这下就可以可视化了。
我们希望绘制的,不是一张图,而是 12 张。分别代表 12 个月。这种图形,有个专门的名称,叫做“分面图”(facet plot)。 Pandas 的 plot 函数有一个非常方便的参数,叫做 subplots ,可以帮助我们轻松达成目标。
每张图,我们依然采用柱状图的方式。因为默认方式绘制的图像,尺寸可能不符合我们的预期。因此我们显式指定图片的长宽。
robbery[robbery.year==2018].groupby(['month', 'hour']).size().unstack(0).fillna(0).plot(subplots=True, kind='bar', figsize=(5,30))

你看了这张图以后,作何感想?
我觉得,每个月份,这张图对于哪个时段最好不要出门,都具备比较高的指导意义。因此……可以当成黄历来使用。
开个玩笑啦,别当真。
如果你对于图像的品质有追求,我建议你学用 Matplotlib 或者 seaborn 来重绘上图。这也作为今天的最后一道练习题,留给你解决。欢迎你把答案用留言的方式和大家分享。
小结
通过本文的学习,希望你已掌握了以下内容:
如何检索、浏览和获取开放数据;
如何用 Python 和 Pandas 做数据分类统计;
如何在 Pandas 中做数据变换,以及缺失值补充;
如何用 Pandas 中的 plot 函数做折线图、柱状图,以及分面图(facet plot)。
(本文为Python大本营转载文章,转载请联系作者)
-- 【本文完】 --
Python大本营诚邀优秀 Python 作者、文章

推荐阅读:
10行Python,搭建一个游戏AI
如何用Python搭建可以画风迁移的人工智能
用Python搭建单样本学习的手写字体分类器
70个NumPy分级练习题:用Python一举搞定机器学习矩阵运算
在家想远程公司电脑?Python+微信一键连接!

❤Python大本营“号内搜”功能全新升级
搜索功能更强大,请在公众号菜单栏体验















 694
694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









