







一 YARN的概述
为克服Hadoop 1.0中HDFS和MapReduce存在的各种问题而提出的,针对Hadoop 1.0中的MapReduce在扩展性和多框架支持方面的不足,提出了全新的资源管理框架YARN.
Apache YARN(Yet another Resource Negotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序。
yarn被引入Hadoop2,最初是为了改善MapReduce的实现,但是因为具有足够的通用性,同样可以支持其他的分布式计算模式,比如Spark,Tez等计算框架。
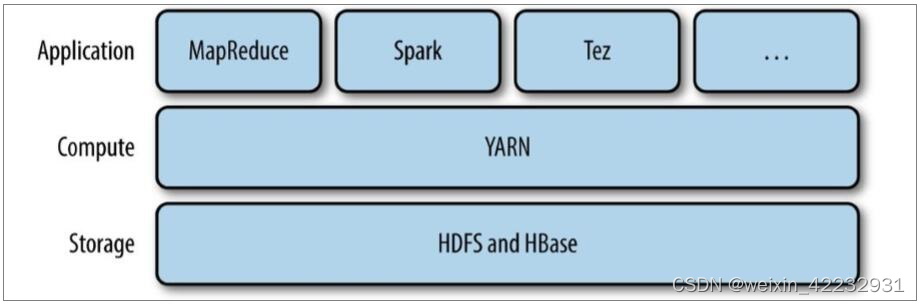
二 YARN的架构及组件
2.1. MapReduce 1.x的简介
第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中,HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成,对应Hadoop版本为Hadoop 1.x和0.21.X,0.22.x。
1) MapReduce1的角色
-1.Client :作业提交发起者。
-2.JobTracker :初始化作业,分配作业,与TaskTracker通信,协调整个作业。
-3.TaskTracker :保持JobTracker通信,在分配的数据片段上执行MapReduce任务。

2) MapReduce执行流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pIIwHyUh-1647038030045)(Hadoop.assets/image-20210414093407057.png)]
**步骤1)**提交作业
编写MapReduce程序代码,创建job对象,并进行配置,比如输入和输出路径,压缩格式等,然后通过JobClinet来提交作业。
**步骤2)**作业的初始化
客户端提交完成后,JobTracker会将作业加入队列,然后进行调度,默认的调度方法是FIFO调试方式。
**步骤3)**任务的分配
TaskTracker和JobTracker之间的通信与任务的分配是通过心跳机制完成的。
TaskTracker会主动向JobTracker询问是否有作业要做,如果自己可以做,那么就会申请到作业任务,这个任务可以是MapTask也可能是ReduceTask。
**步骤4)**任务的执行
申请到任务后,TaskTracker会做如下事情:
-1. 拷贝代码到本地
-2. 拷贝任务的信息到本地
-3. 启动JVM运行任务
**步骤5)**状态与任务的更新
任务在运行过程中,首先会将自己的状态汇报给TaskTracker,然后由TaskTracker汇总告之JobTracker。任务进度是通过计数器来实现的。
步骤6) 作业的完成
JobTracker是在接受到最后一个任务运行完成后,才会将任务标记为成功。此时会做删除中间结果等善后处理工作。
2.2. YARN的设计思想
yarn的基本思想是将资源管理和作业调度/监视功能划分为单独的守护进程。其思想是拥有一个全局ResourceManager (RM),以及每个应用程序拥有一个ApplicationMaster (AM)。应用程序可以是单个作业,也可以是一组作业

一个ResourceManager和多个NodeManager构成了yarn资源管理框架。他们是yarn启动后长期运行的守护进程,来提供核心服务。
ResourceManager,是在系统中的所有应用程序之间仲裁资源的最终权威,即管理整个集群上的所有资源分配,内部含有一个Scheduler(资源调度器)
NodeManager,是每台机器的资源管理器,也就是单个节点的管理者,负责启动和监视容器(container)资源使用情况,并向ResourceManager及其 Scheduler报告使用情况
container:即集群上的可使用资源,包含cpu、内存、磁盘、网络等
ApplicationMaster(简称AM)实际上是框架的特定的库,每启动一个应用程序,都会启动一个AM,它的任务是与ResourceManager协商资源,并与NodeManager一起执行和监视任务
**扩展)**YARN与MapReduce1的比较

2.3. YARN的配置
yarn属于hadoop的一个组件,不需要再单独安装程序,hadoop中已经存在配置文件的设置,本身就是一个集群,有主节点和从节点。
注意<value></value>之间的值不能有空格
在mapred-site.xml中的配置如下:
<!--用于执行MapReduce作业的运行时框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--历史任务的内部通讯地址-->
<property>
<name>MapReduce.jobhistory.address</name>
<value>zrclass01:10020</value>
</property>
<!--历史任务的外部监听页面-->
<property>
<name>MapReduce.jobhistory.webapp.address</name>
<value>zrclass01:19888</value>
</property>
在yarn-site.xml中的配置如下:
<!--配置resourcemanager的主机-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>zrclass01</value>
</property>
<!--配置yarn的shuffle服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定shuffle对应的类 -->
<property>
<name>yarn.nodemanager.aux-services.MapReduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--配置resourcemanager的scheduler的内部通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>zrclass01:8030</value>
</property>
<!--配置resoucemanager的资源调度的内部通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>zrclass01:8031</value>
</property>
<!--配置resourcemanager的内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>zrclass01:8032</value>
</property>
<!--配置resourcemanager的管理员的内部通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>zrclass01:8033</value>
</property>
<!--配置resourcemanager的web ui 的监控页面-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>zrclass01:8088</value>
</property>
1) 日志位置
jps:当启动进程时出错了解决步骤:可以查看日志
如果是hdfs上的问题,则查看对应的日志
less 或 tail -1000 $HADOOP_HOME/logs/hadoop-{user.name}-{jobname}-{hostname}.log
如果是yarn,则查看
less 或 tail -1000 $HADOOP_HOME/logs/yarn-{user.name}-{jobname}-{hostname}.log
2) 历史服务
如果需要查看YARN的作业历史,需要打开历史服务:
1. 停止当前的YARN进程
stop-yarn.sh
2. 在yarn-site.xml中添加配置
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志信息保存在文件系统上的最长时间,单位为秒-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
3. 分发到其他节点
4. 启动YARN进程
start-yarn.sh
5. 开启历史服务
mr-jobhistory-server.sh start historyserver
三 YARN的执行原理
在MR程序运行时,有五个独立的进程:
- YarnRunner:用于提交作业的客户端程序
- ResourceManager:yarn资源管理器,负责协调集群上计算机资源的分配
- NodeManager:yarn节点管理器,负责启动和监视集群中机器上的计算容器(container)
- Application Master:负责协调运行MapReduce作业的任务,他和任务都在容器中运行,这些容器由资源管理器分配并由节点管理器进行管理。
- HDFS:用于共享作业所需文件。
整个过程如下图描述:

1. 调用waitForCompletion方法每秒轮询作业的进度,内部封装了submit()方法,用于创建JobCommiter实例,并且调用其的submitJobInternal方法。提交成功后,如果有状态改变,就会把进度报告到控制台。错误也会报告到
控制台
2. JobCommiter实例会向ResourceManager申请一个新应用ID,用于MapReduce作业ID。这期间JobCommiter也会进行检查输出路径的情况,以及计算输入分片。
3. 如果成功申请到ID,就会将运行作业所需要的资源(包括作业jar文件,配置文件和计算所得的输入分片元数据文件)上传到一个用ID命名的目录下的HDFS上。此时副本个数默认是10.
4. 准备工作已经做好,再通知ResourceManager调用submitApplication方法提交作业。
5. ResourceManager调用submitApplication方法后,会通知Yarn调度器(Scheduler),调度器分配一个容器,在节点管理器的管理下在容器中启动 application master进程。
6. application master的主类是MRAppMaster,其主要作用是初始化任务,并接受来自任务的进度和完成报告。
7. 然后从HDFS上接受资源,主要是split。然后为每一个split创建MapTask以及参数指定的ReduceTask,任务ID在此时分配
8. 然后Application Master会向资源管理器请求容器,首先为MapTask申请容器,然后再为ReduceTask申请容器。(5%)
9. 一旦ResourceManager中的调度器(Scheduler),为Task分配了一个特定节点上的容器,Application Master就会与NodeManager进行通信来启动容器。
10. 运行任务是由YarnChild来执行的,运行任务前,先将资源本地化(jar文件,配置文件,缓存文件)
11. 然后开始运行MapTask或ReduceTask。
12. 当收到最后一个任务已经完成的通知后,application master会把作业状态设置为success。然后Job轮询时,知道成功完成,就会通知客户端,并把统计信息输出到控制台
四 YARN的案例测试
MapReduce:
[root@zrclass01 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.7.6.jar wordcount /input /output
INFO client.RMProxy: Connecting to ResourceManager at zrclass01/192.168.10.101:8032
INFO input.FileInputFormat: Total input paths to process : 1
INFO mapreduce.JobSubmitter: number of splits:1
INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1617775349214_0003
INFO impl.YarnClientImpl: Submitted application application_1617775349214_0003
INFO mapreduce.Job: The url to track the job: http://zrclass01:8088/proxy/application_1617775349214_0003/
INFO mapreduce.Job: Running job: job_1617775349214_0003
INFO mapreduce.Job: Job job_1617775349214_0003 running in uber mode : false
INFO mapreduce.Job: map 0% reduce 0%
INFO mapreduce.Job: map 100% reduce 0%
INFO mapreduce.Job: map 100% reduce 100%
INFO mapreduce.Job: Job job_1617775349214_0003 completed successfully
INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=111
FILE: Number of bytes written=245331
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=218
HDFS: Number of bytes written=69
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3359
Total time spent by all reduces in occupied slots (ms)=3347
Total time spent by all map tasks (ms)=3359
Total time spent by all reduce tasks (ms)=3347
Total vcore-milliseconds taken by all map tasks=3359
Total vcore-milliseconds taken by all reduce tasks=3347
Total megabyte-milliseconds taken by all map tasks=3439616
Total megabyte-milliseconds taken by all reduce tasks=3427328
Map-Reduce Framework
Map input records=3
Map output records=21
Map output bytes=203
Map output materialized bytes=111
Input split bytes=99
Combine input records=21
Combine output records=9
Reduce input groups=9
Reduce shuffle bytes=111
Reduce input records=9
Reduce output records=9
Spilled Records=18
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=126
CPU time spent (ms)=1250
Physical memory (bytes) snapshot=451137536
Virtual memory (bytes) snapshot=4204822528
Total committed heap usage (bytes)=282591232
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=119
File Output Format Counters
Bytes Written=69
五 YARN的Web UI查看
使用8088端口,可以查看YARN任务的WebUI















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









