







简介:XML是用于标记数据的语言,广泛应用于多个领域。本文详细探讨了处理XML文档的三种主要解析技术:SAX、PULL和DOM。SAX解析器基于事件驱动,占用内存较少,但代码可能复杂;PULL解析器提供更面向对象的API,适合资源受限环境;DOM解析器将XML文档加载为树形结构,适合小型至中型文件,但内存消耗较大。文章通过实例展示了每种解析方式的实现细节,并比较了它们的优势与适用场景。 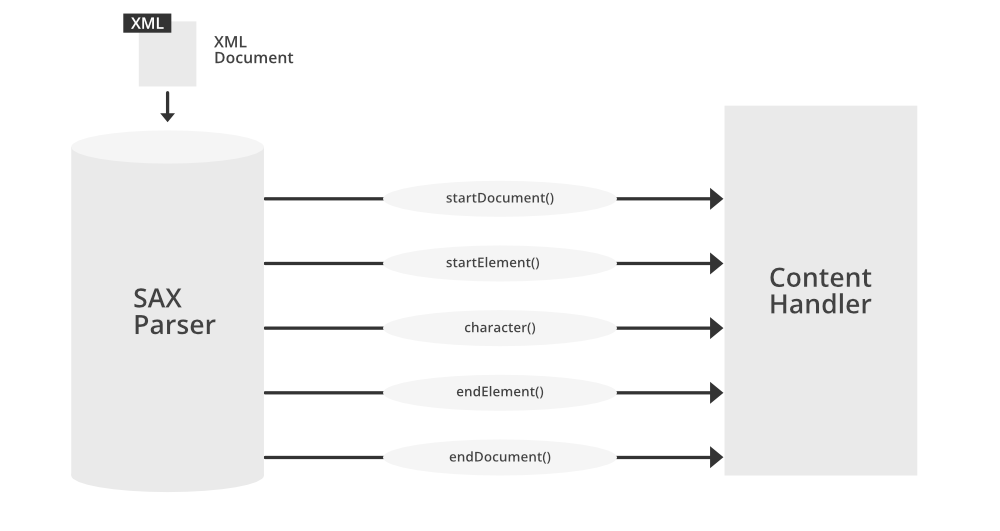
1. XML解析技术概述
可扩展标记语言(XML)是数据交换和存储的标准格式之一,广泛应用于网络通信和数据存储。解析XML文档是许多应用程序的核心功能,它允许我们有效地读取和处理XML格式的数据。XML解析技术主要分为流式解析和基于DOM的解析两大类。流式解析技术如SAX和PULL,通过逐行读取XML文档,能够处理大型文件,并且具有较低的内存占用。而基于DOM的解析技术则把整个XML文档加载到内存中,形成树状结构,便于随机访问和修改,适用于文件大小适中的场景。本章将对XML解析技术的概念、类型及其基本应用场景做概括性介绍。
2. SAX解析技术特点及Java实现示例
2.1 SAX解析技术概述
2.1.1 SAX解析技术的工作原理
SAX (Simple API for XML) 是一种基于事件的解析技术,它通过在解析XML文档时触发一系列的事件来工作。与DOM(文档对象模型)解析器一次性将整个文档加载到内存中不同,SAX解析器采取的是流式的读取方式,边读边解析,逐个处理文档的节点和内容。
SAX解析器在遍历XML文档时,会遇到开始标签、结束标签、文本内容等不同的事件。针对这些事件,SAX解析器会调用相应的事件处理器(Event Handlers),如 startElement 和 endElement 。这些事件处理器通常是开发者根据需要自行实现的,用来对XML文档的内容进行处理。
2.1.2 SAX解析技术的优势与局限性
SAX的主要优势在于它的解析效率高,特别是对于大型文件。由于不需要一次性加载整个文档到内存中,因此它的内存占用相对较小,速度也较快。此外,SAX解析器可以立即报告解析过程中遇到的错误,有助于快速定位问题。
然而,SAX的局限性也很明显。它是一种只读解析方式,不支持随机访问,且只能向前遍历文档,一旦某个事件处理完成,相关信息就会丢失。此外,SAX不支持对XML文档的修改或删除操作,如果需要这些操作,则必须通过其他方式来实现。
2.2 SAX解析器在Java中的应用
2.2.1 SAX解析器的核心组件介绍
在Java中使用SAX解析XML文档涉及到以下几个核心组件:
-
XMLReader:这是负责解析XML文档的类,负责触发事件并调用相应的事件处理器。通常通过工厂方法XMLReaderFactory.createXMLReader()来创建。 -
ContentHandler:这是一个接口,定义了处理XML文档各种事件的方法。实现此接口可以对XML文档进行自定义处理。 -
ErrorHandler:这个接口用于处理解析过程中遇到的错误,如parseError方法。 -
EntityResolver:此接口用于处理实体引用,解析外部实体。
2.2.2 Java中实现SAX解析的代码示例
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.InputSource;
import org.xml.sax.XMLReaderFactory;
import java.io.StringReader;
public class SaxExample {
public static void main(String[] args) throws Exception {
// 创建XMLReader
XMLReader reader = XMLReaderFactory.createXMLReader();
// 创建ContentHandler实例
MyContentHandler handler = new MyContentHandler();
// 设置内容处理器
reader.setContentHandler(handler);
// 设置错误处理器
reader.setErrorHandler(new MyErrorHandler());
// 解析XML文档
String xmlContent = "<example><item>Value</item></example>";
reader.parse(new InputSource(new StringReader(xmlContent)));
}
}
class MyContentHandler extends DefaultHandler {
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
// 当开始解析元素时,执行的操作
System.out.println("Start element :" + qName);
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
// 当结束解析元素时,执行的操作
System.out.println("End element :" + qName);
}
// ... 其他必要的方法覆盖 ...
}
class MyErrorHandler implements org.xml.sax.ErrorHandler {
public void warning(SAXParseException spe) throws SAXException {
// 处理XML文档中的警告
}
public void error(SAXParseException spe) throws SAXException {
// 处理XML文档中的错误
}
public void fatalError(SAXParseException spe) throws SAXException {
// 处理XML文档中的严重错误
}
}
在上述代码中,我们创建了一个SAX解析器的实例,并定义了一个 MyContentHandler 类来处理XML文档中的开始元素和结束元素事件。同时,我们还实现了一个 MyErrorHandler 来捕获和处理解析过程中的错误。这种方式允许我们在读取XML文档时实时处理其内容。
3. PULL解析技术特点及Java实现示例
3.1 PULL解析技术概述
3.1.1 PULL解析技术的基本概念
PULL解析技术是一种基于事件的解析方式,与SAX类似,它也采用了事件驱动模型。不过,与SAX不同的是,PULL解析器是由应用程序驱动的,这意味着开发人员可以完全控制解析过程,决定何时开始解析和处理事件。PULL解析器的事件循环是通过调用 next() 方法实现的,这样开发者就可以在每次事件处理之间暂停解析过程,或根据需要回溯到之前的元素。
PULL解析器通常以流的形式进行处理,因此在处理大数据量的XML文档时,它的性能往往比SAX解析器更优。此外,由于PULL解析器是基于回调的,开发人员可以更容易地将解析过程集成到现有的代码框架中。
3.1.2 PULL解析技术的性能特点
PULL解析器的性能特点主要体现在以下几个方面:
- 内存占用低 :PULL解析器在解析XML文档时是逐个元素进行的,不需要将整个文档加载到内存中。这使得它在处理大型XML文件时,能够更有效地利用系统资源,显著降低内存的占用。
- 灵活的事件处理 :由于事件是由开发人员控制何时处理的,因此可以根据不同的业务需求定制事件处理逻辑,实现更加灵活的XML处理。
- 易于集成 :PULL解析器的回调机制使其可以更容易地与现有的应用程序逻辑集成,使得解析过程能够更好地嵌入到业务处理流程中。
3.2 PULL解析器在Java中的应用
3.2.1 PULL解析器的类结构分析
在Android平台上,PULL解析器的实现类位于 org.xmlpull.v1 包中。其中, XmlPullParser 接口定义了解析器的基本操作,而 XmlPullParserFactory 类则用于创建解析器实例。PULL解析器的类结构非常清晰,主要的类和接口如下:
-
XmlPullParser:核心接口,定义了解析XML文档所需的方法,如next()、getEventType()等。 -
XmlPullParserFactory:用于创建XmlPullParser实例的工厂类。 -
XmlSerializer:用于生成XML文档的接口,与XmlPullParser相对应。
3.2.2 Java中实现PULL解析的代码示例
以下是一个使用PULL解析技术解析XML文档的Java代码示例:
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserException;
import org.xmlpull.v1.XmlPullParserFactory;
import java.io.IOException;
import java.io.StringReader;
public class PullParserExample {
public static void main(String[] args) {
try {
// 创建XmlPullParserFactory实例
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
// 获取XmlPullParser实例
XmlPullParser parser = factory.newPullParser();
// XML文档字符串
String xmlString = "<note><to>Tove</to><from>Jani</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>";
// 设置输入源
parser.setInput(new StringReader(xmlString));
// 开始解析
int eventType = parser.getEventType();
while (eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
case XmlPullParser.START_DOCUMENT:
System.out.println("Start document");
break;
case XmlPullParser.START_TAG:
System.out.println("Start tag: " + parser.getName());
break;
case XmlPullParser.TEXT:
System.out.println("Text: " + parser.getText());
break;
case XmlPullParser.END_TAG:
System.out.println("End tag: " + parser.getName());
break;
}
eventType = parser.next(); // 移到下一个事件
}
System.out.println("End document");
} catch (XmlPullParserException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
分析与参数说明
- XmlPullParserFactory :这个工厂类用于生成XmlPullParser的实例。调用
newInstance()方法可以获取XmlPullParserFactory的默认实现。 - XmlPullParser :这是核心接口,定义了解析事件和对XML文档的查询操作。
parser.setInput()方法用于设置解析的输入源,这里是一个StringReader,用来读取XML字符串。 - 解析循环 :通过
parser.getEventType()获取事件类型,然后根据不同的事件类型执行相应的逻辑。parser.next()方法用于移动到下一个事件,直到文档结束。
以上代码演示了如何使用PULL解析器逐个处理XML文档中的事件,例如开始标签、结束标签和文本。通过这种方式,开发人员可以根据实际需求处理每一个XML元素,灵活度很高。
4. DOM解析技术特点及Java实现示例
DOM解析技术是一种广泛使用的XML解析方法,它在内存中构建一个树状结构,代表XML文档的各个部分。开发者可以通过遍历这棵树来获取所需的数据。
4.1 DOM解析技术概述
4.1.1 DOM解析技术的原理及模型
DOM(Document Object Model)是一种以树形结构表示XML文档的接口。DOM解析器读取整个XML文档,并构建一个节点树(Node Tree),其中每个节点代表XML文档中的一个组件,例如元素、属性、注释等。文档中的每个元素都有一个特定的父元素(除了根元素),并且可以有多个子元素。
在DOM模型中,文档被视为一个整体,这意味着所有的数据都会被加载到内存中,这在处理大型文件时可能会成为瓶颈。然而,DOM解析技术的主要优势在于其灵活性,因为一旦文档被加载到内存中,开发者可以任意地访问、修改、删除或添加节点。
4.1.2 DOM解析技术的优势与挑战
DOM技术的一个主要优点是其易于使用。一旦文档被解析,开发者就可以像操作常规的树形结构一样自由地操作这个节点树。这种随机访问的能力非常适合于那些需要频繁修改XML文档的场景。
然而,DOM解析技术也存在挑战。由于DOM解析需要将整个文档加载到内存中,这就导致了显著的内存消耗。此外,对于大型文档,DOM解析可能会导致显著的性能问题,因为它需要等待整个文档加载完成才能开始处理。
4.2 DOM解析器在Java中的应用
4.2.1 DOM解析器的核心组件介绍
在Java中,DOM解析器由几个核心组件组成,包括 DocumentBuilderFactory 、 DocumentBuilder 和 Document 接口。 DocumentBuilderFactory 用于创建 DocumentBuilder 的实例,而 DocumentBuilder 实际进行解析操作,并返回一个 Document 对象。
4.2.2 Java中实现DOM解析的代码示例
以下是使用Java的DOM解析器来解析一个简单的XML文档的示例代码:
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
public class DOMParserExample {
public static void main(String[] args) throws Exception {
// 创建DocumentBuilderFactory实例
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 创建DocumentBuilder实例
DocumentBuilder builder = factory.newDocumentBuilder();
// 解析XML文件并返回Document对象
Document document = builder.parse("example.xml");
// 获取根节点
Element rootElement = document.getDocumentElement();
System.out.println("Root element: " + rootElement.getNodeName());
// 获取所有的<book>元素节点
NodeList bookNodes = rootElement.getElementsByTagName("book");
for (int i = 0; i < bookNodes.getLength(); i++) {
Node bookNode = bookNodes.item(i);
// 获取每个<book>元素的子元素<name>的文本内容
Element bookElement = (Element) bookNode;
String bookName = bookElement.getElementsByTagName("name").item(0).getTextContent();
System.out.println("Book name: " + bookName);
}
}
}
在这个代码示例中,首先创建了 DocumentBuilderFactory 和 DocumentBuilder 的实例,然后使用 DocumentBuilder 来解析名为 example.xml 的XML文件,并构建了DOM树。接着,代码遍历根节点下的所有 <book> 元素,并打印出每个 <book> 元素下 <name> 子元素的内容。
该示例展示了如何在Java中使用DOM解析器解析XML文档,并处理节点数据。需要注意的是,解析过程中可能会抛出异常,因此必须进行异常处理。在处理大型XML文件时,需要特别注意内存管理和异常处理策略。
5. 各解析技术内存使用及适用场景对比
5.1 解析技术的内存使用效率分析
5.1.1 内存使用评估标准与方法
在比较XML解析技术的内存使用效率时,我们需要确立一些评估标准和方法。评估标准通常包括:内存占用、垃圾回收频率、解析速度等。内存占用指的是解析过程中的常驻内存大小,这决定了处理大型文件的能力。垃圾回收频率则反映了内存管理的效率,较高的垃圾回收频率意味着内存泄漏或者效率低下。解析速度影响了整体性能,快速的解析能够减少处理时间,提高系统响应效率。
评估方法可以通过运行时监控和分析工具,如JProfiler、VisualVM等,来观察解析过程中的内存变化和垃圾回收情况。同时,可以设计一系列基准测试用例,通过比较不同技术解析相同数据量文件的内存消耗和执行时间,来进行客观的对比分析。
5.1.2 SAX、PULL和DOM内存使用对比
-
SAX(Simple API for XML) : SAX采用的是事件驱动模型,解析过程中不需要将整个XML文档加载到内存中,而是逐个读取元素,生成事件。因此,它对内存的要求很低,特别适合处理大型文件。然而,SAX缺乏随机访问能力,这限制了它在需要频繁查询的场景中的应用。
-
PULL(XML Pull Parsing) : PULL解析器同样基于事件驱动模型,它允许开发者通过循环调用解析器的next()方法来获取事件,与SAX类似,它在内存使用上也表现良好。PULL解析器的灵活性略高于SAX,因为它可以更方便地控制解析过程。
-
DOM(Document Object Model) : DOM解析器将整个XML文档加载为树状结构对象,存放在内存中。这意味着,对于大型文件,DOM的内存消耗将会显著增加。但它的优势在于提供了丰富的API来随机访问和修改文档,适用于需要对XML文档进行大量读写操作的应用场景。
从内存使用效率角度看,SAX和PULL解析器适合内存敏感的应用,而DOM解析器更适合需要频繁读写操作的场景。
5.2 解析技术的适用场景对比
5.2.1 大文件处理场景下的解析技术选择
对于大文件处理,内存占用是一个关键因素。 SAX 和 PULL 解析器由于其低内存占用的特性,是处理大型文件的首选。它们可以边读边处理,不需要一次性将整个文档加载到内存中。
DOM 解析器在处理大文件时可能会遇到内存不足的问题,因此通常不推荐使用。如果必须使用,应考虑将文件分割处理或优化DOM树的结构和管理方式,以减少内存占用。
5.2.2 需要频繁读写操作的场景比较
在需要频繁进行读写操作的场景下, DOM 解析器提供了便利的API来访问和修改XML文档的各个部分,使得读写操作变得简单。但需要注意的是,频繁操作可能会导致内存的大量消耗,因此可能需要更多的优化策略来管理内存使用。
SAX 和 PULL 解析器在这种场景下不具备优势,因为它们更适合一次性的解析过程,而不是在已解析的内容上进行频繁的修改。
5.2.3 对响应时间要求极高的场景分析
对于那些对响应时间要求极高的场景,应考虑使用 PULL 解析器。由于其事件驱动的模型,PULL解析器能够更快速地响应解析事件,允许开发者在事件发生时即刻进行处理,减少了内存消耗的同时,也提升了响应速度。
SAX 解析器虽然也是事件驱动,但其API使用起来可能不如PULL解析器那么直观灵活,因此在对响应速度要求极高的场景下,PULL解析器是更合适的选择。
以下为实际的代码和工具使用示例,展示如何在实际开发中对不同解析技术的内存使用进行监控和评估。
代码示例:使用VisualVM监控SAX解析过程的内存使用
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.Attributes;
import org.xml.sax.SAXParser;
import org.xml.sax.SAXException;
public class SaxMemoryUsageExample extends DefaultHandler {
// 处理XML文件的SAX解析器
public void parseXMLFile(String filePath) throws Exception {
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser saxParser = spf.newSAXParser();
saxParser.parse(filePath, this);
}
// 其他handler方法根据需要实现...
}
在VisualVM中,首先需要添加应用程序进程,然后选择该进程,在监视标签页中,就可以看到内存使用图表了。通过这种方式,我们可以观察到解析过程中的内存使用和垃圾回收情况。
代码示例:使用JProfiler监控DOM解析过程的内存使用
import org.w3c.dom.Document;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
public class DomMemoryUsageExample {
public Document parseXMLFile(String filePath) throws Exception {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
return db.parse(filePath);
}
}
通过JProfiler对DOM解析器进行监控,同样是在应用程序进程上点击右键,选择启动JProfiler,然后在内存视图中分析具体的内存使用情况。
以上是使用XML解析技术时内存使用效率的分析。根据不同的应用场景和需求,选择合适的解析技术是提高系统性能和资源利用率的关键。
6. XML解析技术在实际项目中的应用案例
6.1 使用SAX解析技术的项目案例
6.1.1 案例背景与需求分析
在处理大型的XML文件时,对于内存的使用非常敏感。项目背景是处理电信行业中的账单数据,每个月产生的账单文件通常在数GB甚至数十GB大小。需要解析这些大型XML文件,并从中提取出关键信息,如用户ID、消费金额等,以供后续的账单处理和分析使用。
考虑到XML文件的大小和对内存使用的限制,我们选择了SAX解析技术。SAX采用事件驱动的模型,它在解析XML时,可以边读取边处理,不会将整个文档加载到内存中,这样可以有效避免内存溢出的问题。
6.1.2 SAX在项目中的实现与优化
在实际实现中,我们利用Java的SAX解析器来读取XML文件。SAX解析器的实现通过继承 DefaultHandler 类,并重写其中的几个方法,如 startElement 、 endElement 和 characters 方法,分别对应XML标签的开始、结束以及标签之间的文本信息。
下面是一个简单的代码示例,展示了如何使用SAX解析技术来解析XML并提取特定信息:
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.XMLReaderFactory;
import org.xml.sax.InputSource;
public class SAXExample extends DefaultHandler {
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if("record".equals(qName)) {
// 处理每个record元素的开始标签
// 例如获取属性值或记录起始位置等
}
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if("record".equals(qName)) {
// 处理每个record元素的结束标签
// 例如记录处理完毕或输出信息等
}
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
// 处理元素内的文本内容
// 例如收集文本数据并处理等
}
// 其他方法可以根据需要重写
}
// 使用示例
public class SAXExampleUsage {
public static void main(String[] args) throws Exception {
XMLReader xmlReader = XMLReaderFactory.createXMLReader();
SAXExample handler = new SAXExample();
xmlReader.setContentHandler(handler);
InputSource input = new InputSource("path/to/large.xml");
xmlReader.parse(input);
}
}
在这个示例中,我们定义了一个 SAXExample 类,通过重写 startElement 、 endElement 和 characters 方法来处理XML文件的相应部分。SAX解析器不会加载整个文件到内存,而是在读取文件的过程中进行处理,这使得它非常适合处理大型XML文件。
优化方面,可以通过在 startElement 中进行条件判断,只处理我们感兴趣的元素,从而减少不必要的事件处理。在 characters 方法中,可以避免使用大量临时字符串对象来提高性能。同时,确保在解析过程中及时释放资源,以防止内存泄漏。
7. XML解析技术的未来发展趋势及挑战
随着互联网技术的快速发展,XML解析技术作为数据交换和存储的重要手段,正面临着许多新的挑战与机遇。在本章节中,我们将深入探讨XML解析技术未来的发展趋势、可能出现的新标准,以及当前技术所面临的挑战,并提出相应的解决方案和未来的技术发展方向。
7.1 XML解析技术的新标准与趋势
7.1.1 新一代XML解析技术介绍
随着业务需求的日益复杂化,新一代XML解析技术正逐步引入更加高效、灵活的方式来处理XML文档。这些新技术包括但不限于:
- XQuery : 这是一种强大的查询语言,用于从XML文档中检索信息。它允许用户以声明式方式对XML数据进行复杂的查询。
- XSLT 3.0 : 可扩展样式表语言转换(XSLT)的最新版本,支持更高的性能和模块化,提供了更好的灵活性和表达能力。
- JSONiq : 虽然不是XML技术,但JSONiq提供了类似XQuery的语法,用于处理JSON数据。它被设计为支持XML和JSON的双向转换。
7.1.2 技术发展趋势的预测与分析
预测未来,XML解析技术的发展趋势将可能包括以下方面:
- 性能优化 : 随着大数据和物联网技术的发展,XML解析器将更加注重性能优化,以支持更快的数据处理速度和更低的资源消耗。
- 集成和互操作性 : 解析技术将更好地与其他数据格式和系统集成,例如与NoSQL数据库结合,提供更加流畅的数据交换机制。
- 云计算与分布式处理 : 云平台的普及要求XML解析技术能够更好地支持分布式计算环境,实现跨服务器的高效数据处理。
7.2 面临的挑战与解决方案
7.2.1 当前XML解析技术面临的主要挑战
当前,XML解析技术主要面临以下挑战:
- 效率问题 : 对于大型XML文档,传统的XML解析技术如SAX和DOM可能面临效率低下的问题,尤其是在内存使用和处理速度上。
- 安全性问题 : XML在互联网上的广泛使用使得它成为恶意攻击的目标,XML解析器必须能够有效地防范注入攻击和拒绝服务攻击。
- 移动与物联网 : 在移动和物联网设备上,资源受限,传统XML解析技术可能无法提供足够轻量级和高性能的解决方案。
7.2.2 应对挑战的策略与技术发展方向
为了应对上述挑战,XML解析技术需要采取以下策略和方向:
- 轻量级解析器 : 开发更加轻量级、响应快速的解析器,以适应资源受限的设备和环境。
- 安全性增强 : 在解析器中引入更安全的解析机制,比如严格的XML模式验证、防止XML外部实体攻击(XXE)等。
- 标准化与优化 : 推动XML解析的标准化进程,并持续对现有的解析技术进行性能优化,比如通过多线程处理和并行计算来提升性能。
随着技术的不断进步,我们可以预见XML解析技术将不断演进,以满足未来互联网技术发展的需要。
简介:XML是用于标记数据的语言,广泛应用于多个领域。本文详细探讨了处理XML文档的三种主要解析技术:SAX、PULL和DOM。SAX解析器基于事件驱动,占用内存较少,但代码可能复杂;PULL解析器提供更面向对象的API,适合资源受限环境;DOM解析器将XML文档加载为树形结构,适合小型至中型文件,但内存消耗较大。文章通过实例展示了每种解析方式的实现细节,并比较了它们的优势与适用场景。

















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









