






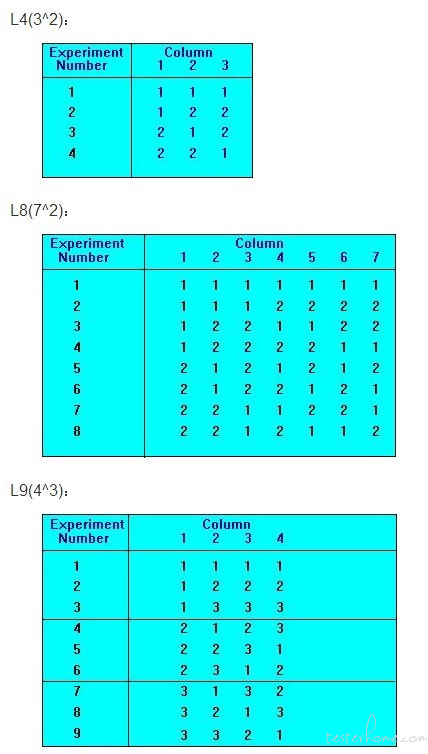
先给大家简单介绍两个重要的算法:“ OATS(Orthogonal Array Testing Strategy)” 和 “Pairwise/All-Pairs Testing”,简称 “正交表法” 和 “配对测试法”。
正交表法
正交表法有两个重要的特性,大家尝试着理解一下:
1.每列中不同数字出现的次数相等
备注:这一特点表明每个因素的每个水平与其它因素的每个水平参与试验的几率是完全相同的,从而保证了在各个水平中最大限度地排除了其它因素水平的干扰,能有效地比较试验结果并找出最优的试验条件。
2.在任意两列其横向组成的数字对中,每种数字对出现的次数相等
备注:这个特点保证了试验点均匀地分散在因素与水平的完全组合之中,因此具有很强的代表性。
举个例子:有三个字段,每个字段可以取三个值,设字段表现为 A(A1,A2,A3)、B(B1,B2,B3)、C(C1,C2,C3),可以组成的集合恰好可以表现为一个三维空间图,如下图所示:
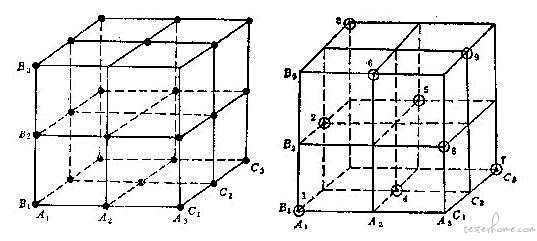
图中的正方体中每个字段的每个水平代表的是一个面,共九个面,任意两个字段的水平之间都存在交点,共 27(3x3x3)个,这就是笛卡尔积。按照两大特性设计出的正交表如右图所示,试验点用⊙表示。我们看到,在 9 个平面中每个平面上都恰好有三个点而每个平面的每行每列都有一个点,而且只有一个点,总共九个点。这样的试验方案,试验点的分布很均匀,试验次数也不多。
国外有一个网站能查询正交表的结果案例:http://www.york.ac.uk/depts/maths/tables/orthogonal.htm
配对测试法
配对测试法(Pairwise)是 L. L. Thurstone( 1887 – 1955) 在 1927 年首先提出来的。他是美国的一位心理统计学家。Pairwise 是基于数学统计和对传统的正交分析法进行优化后得到的产物。
定义:Most field faults were caused by either incorrect single values or by an interaction of pairs of values." If that's generally correct, we ought to focus our testing on the risk of single-mode and double-mode faults. We can get excellent coverage by choosing tests such that 1) each state of each variable is tested, and 2) each variable in each of its states is tested in a pair with every other variable in each of its states. This is called pairwise testing or all-pairs testing.
大概意思是:缺陷往往是由一个参数或两个参数的组合所导致的,那么我们选择比较好的测试组合的原则就是:
1)每个因子的水平值都能被测试到;
2)任意两个因子的各个水平值组合都能被测试到,这就叫配对测试法。
参看:http://www.developsense.com/pairwiseTesting.html
Pairwise 基于如下 2 个假设:
每一个维度都是正交的,即每一个维度互相都没有交集。
根据数学统计分析,73% 的缺陷(单因子是 35%,双因子是 38%)是由单因子或 2 个因子相互作用产生的。19% 的缺陷是由 3 个因子相互作用产生的。
因此,基于覆盖所有 2 因子的交互作用产生的用例集合性价比最高而产生的。国外也有一份类似的数学统计:
我们通过一个订飞机票的实际例子来看一下,配对测试法是怎样从笛卡尔积中提炼出局部最优解的。
依然是三个字段的组合,分别是 Destination(Canada, Mexico, USA),Class(Coach, Business Class, First Class), Seat Preference(Aisle, Window),所对应的笛卡尔积共有 3x3x2=18 中测试组合,如下表所示。
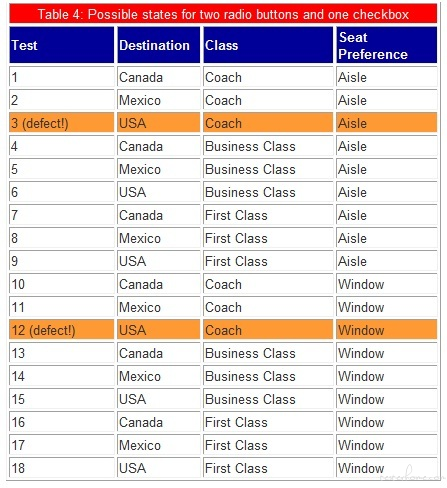
经过配对测试法筛选后,结果如下:
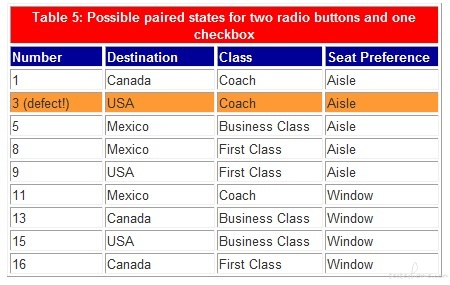
经过筛选以后,我们的测试用例变成了 9 条,case 数量精简了 50%。简单总结 pairwise 的筛选原理就是,发现两两配对在全集中有重复的就去掉其中之一,这样筛选也有副作用,每次筛选完了条数是固定的,但是结果却不尽相同。但是通过上面的介绍我们不难比较出两种算法的差异。
备注说明:
该文应该是搜集整理过来的,只是觉的定义和解释的比较规范,非本人原创.若有不当,请联系我,更新援引说明.














 2174
2174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









