




 文章介绍了TiDB在执行SQL查询时如何使用DAG(有向无环图)来描述查询计划,以及基于行的流式迭代模型——火山模型。TiKV中的Executor负责执行查询步骤,如扫表、选择和过滤。文章提到了向量化查询引擎的引入,以提高性能,减少单行处理的开销,并展示了BatchExecutor如何处理多行数据。最后,文章简要讨论了BatchTableScanExecutor、BatchSelectionExecutor和BatchFastHashAggregationExecutor的实现细节。
文章介绍了TiDB在执行SQL查询时如何使用DAG(有向无环图)来描述查询计划,以及基于行的流式迭代模型——火山模型。TiKV中的Executor负责执行查询步骤,如扫表、选择和过滤。文章提到了向量化查询引擎的引入,以提高性能,减少单行处理的开销,并展示了BatchExecutor如何处理多行数据。最后,文章简要讨论了BatchTableScanExecutor、BatchSelectionExecutor和BatchFastHashAggregationExecutor的实现细节。
什么是下推算子
以下边的 SQL为例子:
select * from students where age > 21 limit 2
TiDB 在解析完这条 SQL语句之后,会开始制定执行计划。在这个语句中, TiDB 会向 TiKV 下推一个可以用有向无环图(DAG)来描述的查询请求:
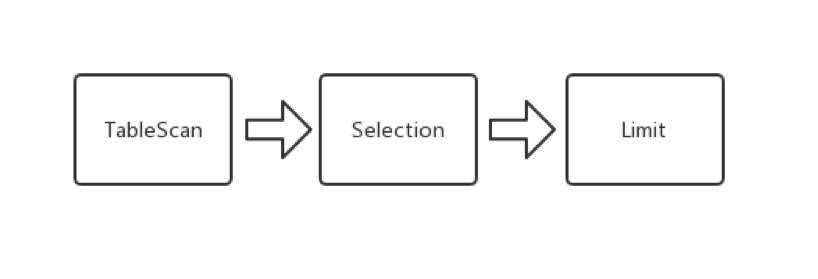
以上的 DAG是一个由一系列算子组成的有向无环图,算子在 TiKV 中称为 Executor。整个 DAG描述了查询计划在 TiKV 的执行过程。在上边的例子中,一条查询 SQL被翻译成了三个执行步骤:
-
扫表
-
选择过滤
-
取若干行
有了基本概念后,下面我们简单介绍一下这样的查询计划在 TiKV 内部的一个执行流程。
下推算子如何执行
绕不开的火山
TiKV 执行器是基于 Volcano Model (火山模型),一种经典的基于行的流式迭代模型。现在主流的关系型数据库都采用了这种模型,例如 Oracle,MySQL 等。
我们可以把每个算子看成一个迭代器。每次调用它的 next()方法,我们就可以获得一行,然后向上返回。而每个算子都把下层算子看成一张表,返回哪些行,返回怎么样的行由算子本身决定。举个例子:
假设我们现在对一张没有主键,没有索引的表 [1],执行一次全表扫描操作:
select * from t where a > 2 limit 2
表 [1]:
a (int) |
b (int) |
|---|---|
| 3 | 1 |
| 1 | 2 |
| 5 | 2 |
| 2 | 3 |
| 1 | 4 |
那么我们就可以得到这样的一个执行计划:
每个算子都实现了一个 Executor的 trait, 所以每个算子都可以调用 next()来向上返回一行。
pub trait Executor: Send {
fn next(&mut self) -> Result<Option<Row>>;
// ...
}
当以上的请求被解析之后,我们会在 ExecutorRunner 里边不断的调用最上层算子的 next() 方法, 直到其无法再返回行。
pub fn handle_request(&mut self) -> Result<SelectResponse> {
loop {
match self.executor.next()? {
Some(row) => {
// Do some aggregation.
},
None => {
// ...
return result;
}
}
}
}
大概的逻辑就是:Runner调用 Limit算子的 next()方法,然后这个时候 Limit实现的 next()方法会去调用下一层算子 Selection的 next()方法要一行上来做聚合,直到达到预设的阀值,在例子中也就是两行,接着 Selection实现的 next()又会去调用下一层算子的 next()方法, 也就是 TableScan, TableScan的 next()实现是根据请求中的 KeyRange, 向下边的 MVCC要上一行,然后返回给上层算子, 也就是第一行 (3, 1),Selection收到行后根据 where字句中的表达式的值做判断,如果满足条件向上返回一行, 否则继续问下层算子要一行,此时 a == 3 > 2, 满足条件向上返回, Limit接收到一行则判断当前收到的行数时候满两行,但是现在只收到一行,所以继续问下层算子要一行。接下来 TableScan返回 (1,2), Selection发现不满足条件,继续问 TableScan要一行也就是 (5,2), Selection发现这行满足条件,然后返回这一行,Limit接收到一行,然后在下一次调用其 next()方法时,发现接收到的行数已经满两行,此时返回 None, Runner会开始对结果开始聚合,然会返回一个响应结果。
引入向量化的查询引擎
当前 TiKV 引入了向量化的执行引擎,所谓的向量化,就是在 Executor间传递的不再是单单的一行,而是多行,比如 TableScan在底层 MVCC Snapshot中扫上来的不再是一行,而是说多行。自然的,在算子执行计算任务的时候,计算的单元也不再是一个标量,而是一个向量。举个例子,当遇到一个表达式:a + b的时候, 我们不是计算一行里边 a列和 b列两个标量相加的结果,而是计算 a列和 b列两列相加的结果。
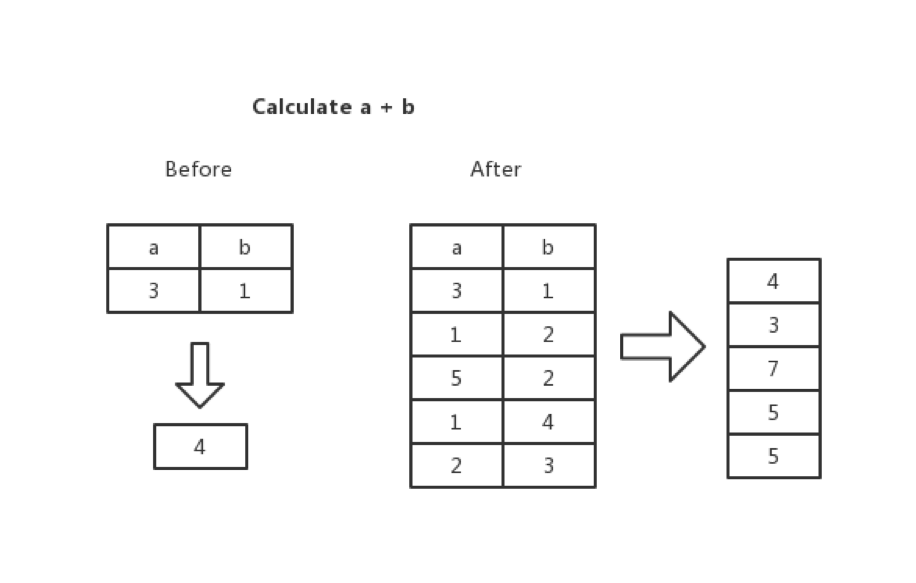
为什么要引入向量化模型呢,原因有以下几点:
-
对于每行我们至少得调用 1 次
next()方法,如果DAG的最大深度很深,为了获取一行我们需要调用更多次的next()方法,所以在传统的迭代模型中,虚函数调用的开销非常大。如果一次next()方法就返回多行,这样平均下来每次next()方法就可以返回多行,而不是至多一行。 -
由于迭代的开销非常大,整个执行的循环无法被
loop-pipelining优化,使得整个循环流水线被卡死,IPC 大大下降。返回多行之后,每个算子内部可以采用开销较小的循环,更好利用loop-pipelining优化。
当然向量化模型也会带来一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











