







导读
本文介绍了使用 Coze 平台搭建 TiDB 文档助手的过程。通过比较不同 AI Bot 平台,突出了 Coze 在插件能力和易用性方面的优势。文章深入讨论了实现原理,包括知识库、function call、embedding 模型等关键概念,最后成功演示了如何在 Coze 平台上快速创建 TiDB Help Bot。
引言
目前市面上有很多搭建 AI Bot 的平台和应用,开源的有 langchain、flowise、dify、FastGPT 等等。字节之前也推出了 Coze,之前试过 Dify 和 FastGPT,目前感觉 Coze 的插件能力有很多,且易用性方面、搭建效率方面也强于其他平台(例如 langchain 或 flowise 需要搭建相对复杂的编排逻辑才能实现大模型调用互联网信息的拓展能力,但是 Coze 则是直接添加 plugin 且不指定任何参数就能实现)。
于是想尝试用 Coze 搭建一个 TiDB 文档助手,顺便研究厘清 Coze 平台是如何抽象一些大模型和其他能力来提高易用和搭建效率的。
实现原理
首先我们先抛开 Coze 平台,在大模型提供能力的基础上如何实现调用文档数据?
这里给出两种模式:知识库和 function call。知识库的优点在于对非实时数据有一个相对准确的近似查询,function call 的优点在于可以实时获得最新的数据,当然也包括文档数据。
Coze 平台中的 plugins 实现了 function 模式,同时也提供了 knowledge 知识库可以管理本地和在线的文档。
embedding + 向量库
我们先来介绍基于文本表示模型 (embedding model) + 向量数据库 (vector db) 增强大模型能力的方式。主要分为两个任务:
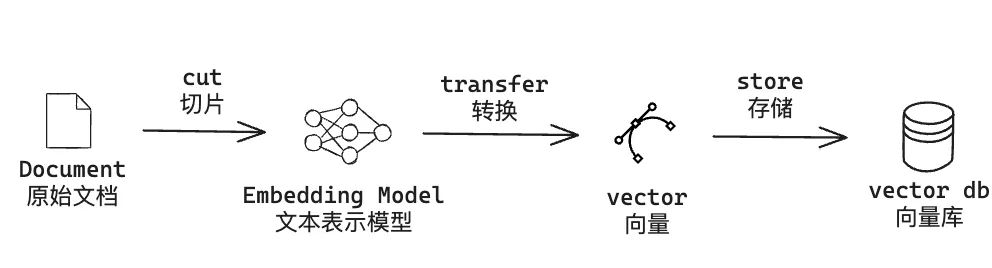
● 离线任务(同步原始文档到向量库):
i. 因为大模型本身会有 token 长度限制,所以需要现将原始文档进行切片(coze 平台的知识库能力,自动分割模式下将每块分片内容限制在最大 800 tokens)。
ii. 使用 embedding model 文本表示模型对每个分片进行 embedding,将其转换为 向量的形式
iii. 将向量存储在向量数据库中特定的 collection
● 在线任务(用户提问):
i. 使用 embedding model 对用户的问题做向量化
ii. 通过用户问题的向量数据,请求向量数据库做 ANN 近似近邻查询,并指定返回 topK
iii. 拿到对应 topK 分片后,我们需要结合分片内容和用户问题,拼凑完整的 prompt。示例如下, quote 为文档的分片内容, question 为用户的实际问题
-
使用标记中的内容作为你的知识:
-
{ {quote}}
-
回答要求:
- 如果你不清楚答案,你需要澄清。
- 避免提及你是从获取的知识。
- 保持答案与中描述的一致。
- 使用 Markdown 语法优化回答格式。
- 使用与问题相同的语言回答。
-
问题: "{ {question}}"
iv. 最后请求大模型,拿到结果即可
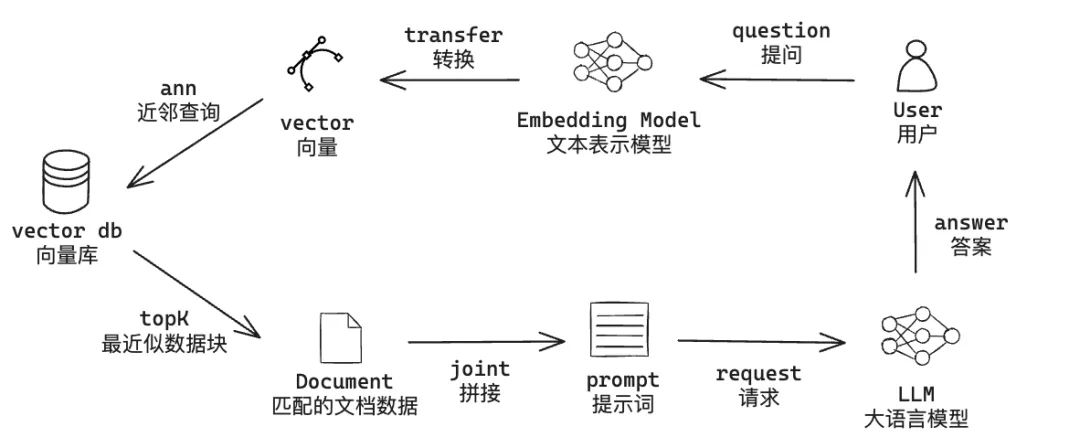
在这种以知识库为主的模式下,比较关键的是 embedding model 、向量数据库和 prompt。下面我们重点说一下 embedding model 和向量库。
embedding
如果是自己尝试的话,embedding model 建议选 huggingface 开源模型,具体的排名 huggingface 上也有,可以看 Massive Text Embedding Benchmark (MTEB) Leaderboard ( https://huggingface.co/spaces/mteb/leaderboard )。中文长文本目前排名比较高的是 tao-8k,向量化后的维度是 1024,具体的调用示例如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











