







 本文探讨了AI应用中向量数据库的重要性,解释了向量数据库与传统关系型数据库的区别,并通过实例展示了它们在实际项目中的结合使用。同时,提到了Serverless技术在提升开发效率方面的贡献。
本文探讨了AI应用中向量数据库的重要性,解释了向量数据库与传统关系型数据库的区别,并通过实例展示了它们在实际项目中的结合使用。同时,提到了Serverless技术在提升开发效率方面的贡献。
TiDB Hackathon 2023 刚刚结束,我仔细地审阅了所有的项目。在并未强调项目必须使用人工智能(AI)相关技术的情况下,引人注目的项目几乎一致地都使用了 AI 来构建自己的应用。大规模语言模型(LLM)的问世使得个人开发者能够在短短 5 分钟内为程序赋予推理能力,而这在以往,几乎只有超大型团队才能胜任。从应用开发者的角度来看,AI 时代也已经到来了。
在这些 AI 应用中,向量数据库的身影是无处不在的。尽管这些项目大多仍在使用关系型数据库,但它们似乎不再发挥一个显而易见的作用。关系型数据库究竟还值不值得获得应用开发者们的关注呢?
为了解答清楚这个问题,我们需要了解一下向量数据库到底跟传统的关系型数据库有什么不同。
什么是向量数据库
为了搞清楚这个问题,我花了一些时间研究了一下向量数据库。接下来我将用最简单的语言来解释什么是向量数据库。
这个世界上的大多数事情都是多特征的,比如你描述一个人可以用身高、体重、性格、性别、穿衣风格、兴趣爱好等等多种不同类型的维度。通常如果你愿意的话,你可以无限扩展这个维度或者特征去描述一个物体,维度或者特征越多,对于一个物体或者事件的描述就是越准确的。
现在,假如开始用一个维度来表达 Emoji 表情的话,0 代表快乐,1 代表悲伤。从 0 - 1 的数字大小就可以表达对应表情的悲欢程度,如下 x 轴所示:

但是你会发现,如果只有一个维度来描述情绪 Emoji 的话,这是笼统的,也是不够准确的。例如开心,会有很多种类型的 Emoji 可以表达。那么这个时候我们通常是加入新的维度来更好地描述它。例如我们在这里加入 Y 轴,通过 0 表示黄色,1 表示白色。加入之后表达每个表情在坐标轴上的点变成了 (x, y) 的元组形式。
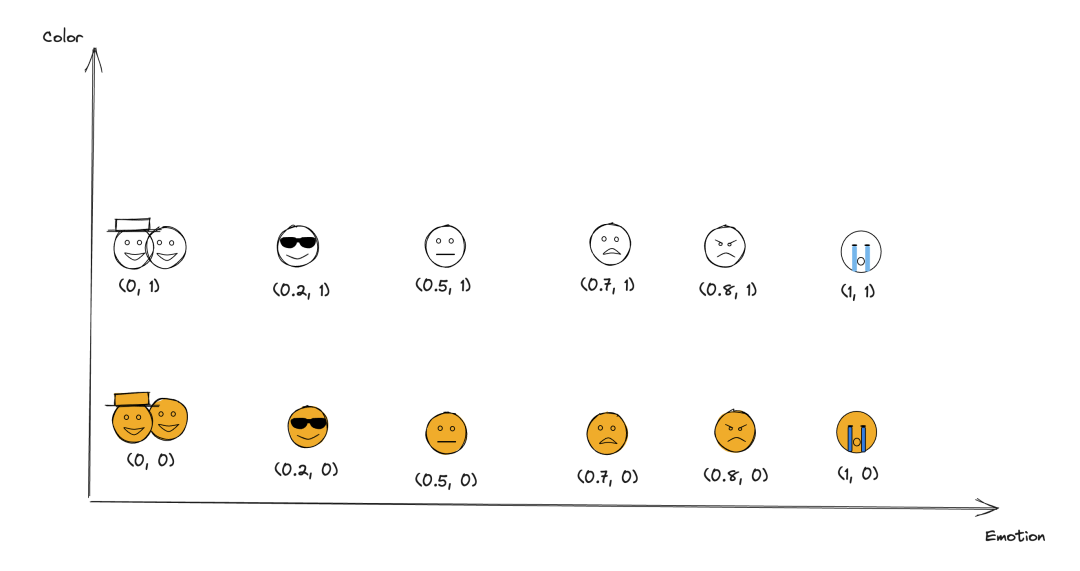
聪明的你一定发现了,即使我们加入 Y 轴这个新的描述维度,依然还有 Emoji 我们是没办法区分开的。比如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











