






逻辑回归是一个二分类的模型,标签为0或者1,通常模型的输出通过sigmoid函数,输出一个概率值,表示预测正样本的可能性。
函数如下:

图像
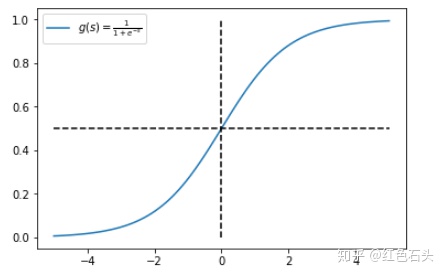
预测样本标签为 1 的概率:

样本标签为 0 的概率为:

综合起来:

当真实样本标签 y = 0 时,上面式子第一项就为 1,概率等式转化为:

当真实样本标签 y = 1 时,上面式子第二项就为 1,概率等式转化为:

我们希望函数值越大越好,就是预测正确的概率越大越好。方便计算引入log
要求函数的最大值 就是求 -log P(y|x)的最小值 所以:

损失函数就是这个 转换成求损失函数的最小值
上面是单个样本的情况,多个样本就进行求和:

然后对其求导,进行梯度计算。
从函数上看
当 y = 1 时


横坐标是预测输出,纵坐标是交叉熵损失函数 L。预测输出越接近真实样本标签 1,损失函数 L 越小。
从别人那里学到的,另一种形式标签为 +1 和 -1。sigmoid函数有个特性

所以 当y=1时

y=-1时

整合到一起,很神奇!!!!!

也是两面都用log:

同样 想让他最大 让其负数最小:

将sigmoid带入

这个就是损失函数。
如果样本为N则:

原文 交叉熵损失函数详解_youhuakongzhi的博客-CSDN博客_交叉熵损失函数公式















 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









