







一、Runtime架构图
(1)从Spark Runtime的角度讲,包括五大核心对象:Master、Worker、Executor、Driver、CoarseGrainedExecutorBackend。
(2)Spark在做分布式集群系统设计的时候:最大化功能独立、模块化封装具体独立的对象、强内聚松耦合。Spark运行架构图如下图所示。
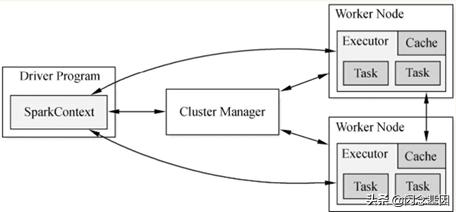
(3)当Driver中的SparkContext初始化时会提交程序给Master,Master如果接受该程序在Spark中运行,就会为当前的程序分配AppID,同时会分配具体的计算资源。
需要特别注意的是,Master是根据当前提交程序的配置信息来给集群中的Worker发指令分配具体的计算资源,但是,Master发出指令后并不关心具体的资源是否已经分配,换言之,Master是发指令后就记录了分配的资源,以后客户端再次提交其他的程序,就不能使用该资源了。
其弊端是可能会导致其他要提交的程序无法分配到本来应该可以分配到的计算资源;最终的优势是Spark分布式系统功能在耦合的基础上最快的运行系统(否则如果Master要等到资源最终分配成功后才通知Driver,就会造成Driver阻塞,不能够最大化并行计算资源的使用率)。
需要补充说明的是:Spark在默认情况下由于集群中一般都只有一个Application在运行,所有Master分配资源策略的弊端就没有那么明显了
二、生命周期
我们从Spark Runtime全局的角度看Spark具体是怎么工作的,从一个具体的job的视角通过Driver、Master、Worker、Executor等角色来具体看看Spark的Runtime生命周期
这里我们编写WordCountJobRuntime.scala代码,观察日志,源数据如下
代码如下:
import org.apache.log4j.{Level, Logger}import org.apache.spark.{SparkConf, SparkContext} object WordCountJobRuntime { def main(args: Array[String]){ Logger.getLogger("org").setLevel(Level.ALL) // 第1步:创建Spark的配置对象SparkConf val conf = new SparkConf() //创建SparkConf对象 conf.setAppName("Wow,WordCountJobRuntime!") //设置应用程序的名称,在程序运行的监控界面可以看到名称 conf.setMaster("local") //此时,程序在本地运行,不需要安装Spark集群 //第2步:创建SparkContext对象 val sc = new SparkContext(conf) // 第 3 步:根据具体的数据来源(如 HDFS、HBase、Local FS、DB、S3等)通过 SparkContext创建RDD val lines = sc.textFile("WordCountJobRuntime.txt") // 第4步:对初始的RDD进行Transformation级别 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8047
8047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









