







跟着问题学1——传统神经网络-线性回归及代码详解-CSDN博客
跟着问题学4——深度学习网络训练中的参数初始化和批正则化等技巧-CSDN博客
跟着问题学7——AlexNet网络详解及代码实战-CSDN博客
跟着问题学9——GoogLeNet网络详解及代码实战-CSDN博客
ResNet解决什么问题?
自从深度神经网络AlexNet在ImageNet取得优异效果之后,深度神经网络就朝着网络层数越来越深的方向发展。增加网络深度,网络可以提取更加复杂的特征,直觉上应该可以取得更好的结果。
但事实并非如此,人们发现随着网络深度的增加,模型精度并不总是提升,并且这个问题显然不是由过拟合(overfitting)造成的,如果是过拟合,训练误差会不断变低,但测试误差会很高,目前的情况明显不是。因为网络加深后不仅测试误差变高了,它的训练误差也变高了。如图所示,比较56层和20层的网络训练结果,发现56层的训练误差和测试误差都高于20层。
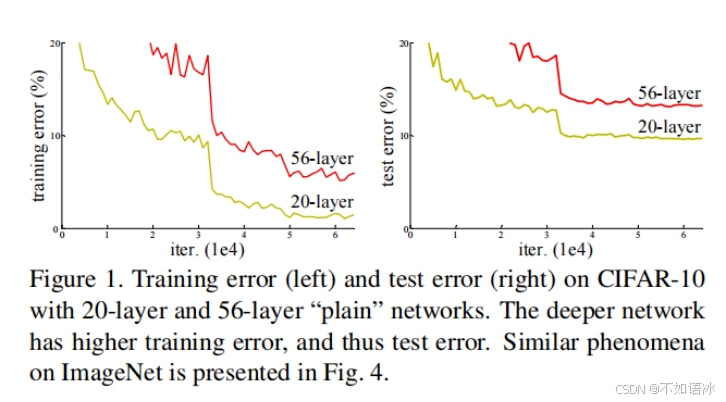
作者提出,这可能是因为更深的网络会伴随梯度消失/爆炸问题,从而阻碍网络的收敛,并将这种加深网络深度但网络性能却下降的现象称为退化问题(degradation problem),
ResNet网络框架结构
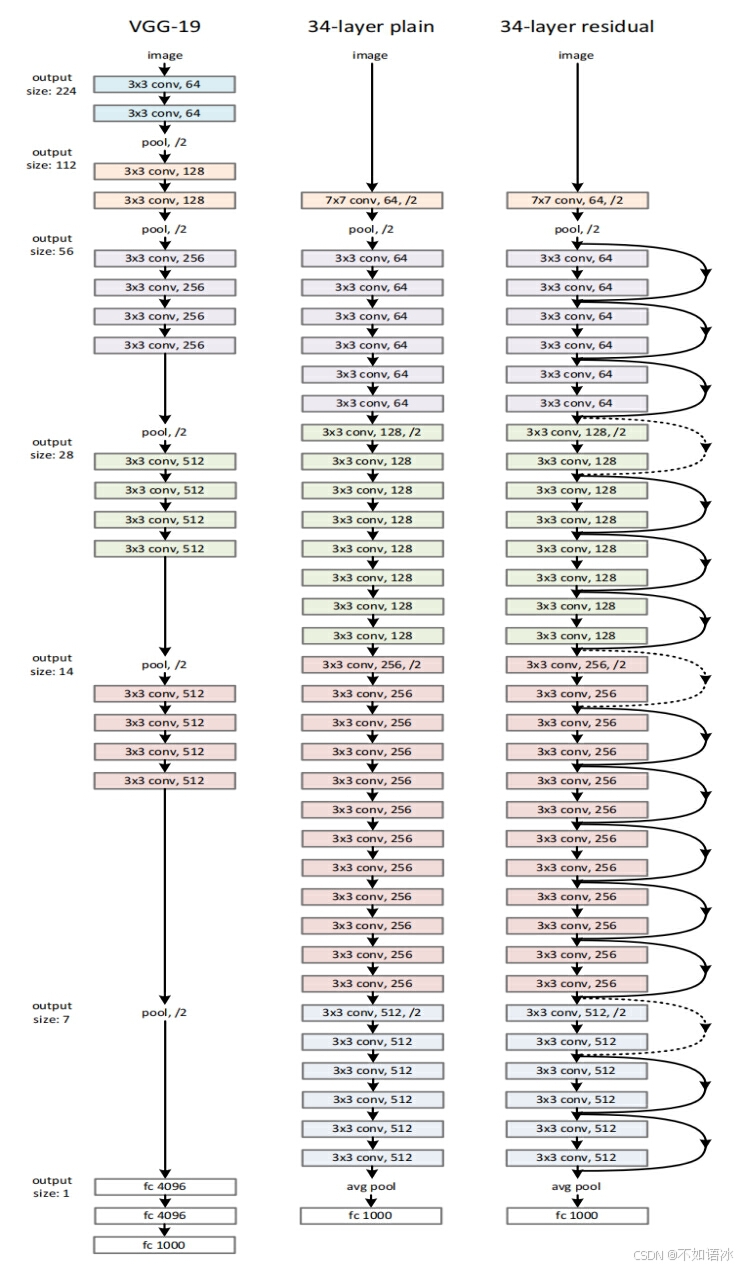
图1
ResNet网络的主要框架是基于VGG网络搭建而成的,分为两步,第一步是搭建的plain网络结构,这一步相比于VGG网络只是优化了深度和网络层的通道数,以及最后取代了2个全连接层;第二步是提出了论文的核心创新点,在plain网络的结构基础上进行了残差连接,将普通网络层模块变成了残差模块。
ResNet的骨架网络与VGG网络的对比
论文的骨架plain网络结构(图1,中)基于VGG网络 (图1,左)改编搭建的,
(1)网络最开始先用一个大的7*7卷积核搭配一个池化层降低特征图尺寸;
(2)卷积层主要为3*3的卷积核,输出特征图尺寸相同的层含有相同数量的卷积核(主要保证通道数一致);
(3)不同于VGG每个小模块最后使用最大池化层下采样降低特征图尺寸,ResNet直接通过stride 为2的卷积层(不填充)下采样。注意特征图尺寸减半,则卷积核的组数(通道数)增加一倍来保证每层的时间复杂度相同。
(4)全局平均池化层:网络的最后阶段不再是连续的三个全连接层,而是使用一个全局的平均pooling层和一个1000 类的包含softmax的全连接层。全局平均池化是在NIN网络中提出来的,简单来说就是最后卷积层输出的特征图尺寸是[Batch,Channel,Height,Width],经过全局平均池化后,尺寸将变为[Batch,Channel,1,1],也就是说,全局平均池化其实就是对每一个通道特征图所有像素(特征)值求平均值,得到一个1*1的特征图。在代码里使用
self.avgpool=nn.AdaptiveAvgPool2d((1,1))初始化
(5)ResNet模型比VGG网络有更少的卷积核和更低的计算复杂度。可以看到全局平均池化层取代了全连接层,而全连接层是参数量最大的部分。
残差网络
如果仅是上述网络结构的优化,ResNet网络不会这么经典且效果显著,ResNet网络的核心是在以上plain网络的基础上,插入shortcut连接(图1,右),将网络变成了对应的残差版本。接下来详细介绍一下。
残差基本单元
前面讲到ResNet网络主要是为了解决网络退化问题的,实际上,在此之前研究人员通过提出包括Batch normalization在内的方法,已经一定程度上缓解了这个问题,但依然不足以满足需求。
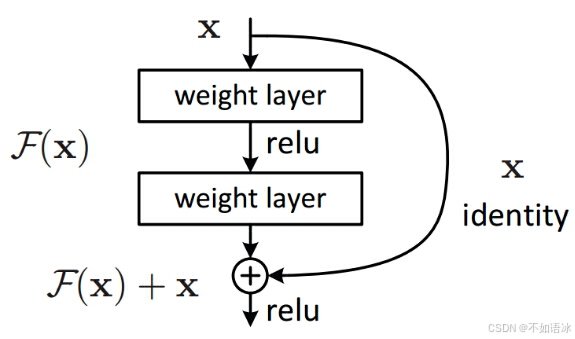
作者想到了构建恒等映射(Identity mapping),即通过在网络层之间加一个shortcut短接,可以在实际训练中将两个连接层之间的网络层忽略。举个例子来说,对于56层的网络,因为比20层网络更深,在不加任何处理的情况下,因为梯度消失/爆炸等问题导致网络难以训练,训练误差反而降低。那么我们就在最后36层网络全部短接,也就意味着最后36层事实上是不工作的,输入是什么,输出还是什么,就等效成20层网络了。在实际应用中当然不是这么简单粗暴的把最后36层全部短接,而是在整个网络结构中设置一个个小的残差模块,在训练中决定哪些是短接的。
问题解决的标志是:增加网络层数,但训练误差不增加。
残差模块:残差模块的输入为x,输出为H(x),若使用以前网络拟合的方法,直接训练网络拟合H(x);但残差模块将输出H(x)分解为两部分,一部分是原始输入特征x,另一部分是“残差”F(x),即H(x)=F(x)+x。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









