







《2019/04/18》再看索引
@date 2019/04/18
主要是参考:
Lucene简介和索引原理
全文检索的基本原理
Lucene的索引文件格式
检索系统大体分两个过程,索引创建(Indexing)和搜索索引(Search)。
- 索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
- 搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
索引创建过程
全文检索的索引创建过程一般有以下几步:
第一步:一些要索引的原文档(Document)。
为了方便说明索引创建过程,这里特意用两个文件为例:
文件一:Students should be allowed to go out with their friends, but not allowed to drink beer.
文件二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
第二步:文档分析。
文档被发送并加入倒排索引之前,Elasticsearch在其主体上的操作称为分析(analysis)。
而analysis的实现可以是Elasticsearch内置分词器(analyzer)或者是自定义分词器。
Analyzer的由如下三部分组成:

1. character filters 字符过滤
字符过滤器将原始文本作为字符流接收,并可以通过添加,删除或更改字符来转换字符流。
字符过滤分类如下:
(1)HTML Strip Character Filter
用途:删除HTML元素,如<b>,并解码HTML实体,如&amp 。
(2)Mapping Character Filter
用途:替换指定的字符。
(3)Pattern Replace Character Filter
用途:基于正则表达式替换指定的字符。
2. tokenizers 文本切分为分词
接收字符流(如果包含了1.字符过滤,则接收过滤后的字符流;否则,接收原始字符流),将其分词。
同时记录分词后的顺序或位置(position),以及开始值(start_offset)和偏移值(end_offset-start_offset)。
这一步骤一般做以下几件事情:
(1)将文档分成一个一个单独的单词。
(2)去除标点符号。
(3)去除停词(Stop word) 。
所谓停词(Stop word)就是一种语言中最普通的一些单词,由于没有特别的意义,因而大多数情况下不能成为搜索的关键词,因而创建索引时,这种词会被去掉而减少索引的大小。
英语中停词(Stop word)如:“the”,“a”,“this”等。
3.token filters分词后再过滤
将步骤2得到的词元(Token)传给语言处理组件(Linguistic Processor)再处理。
语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些同语言相关的处理。
对于英语,语言处理组件(Linguistic Processor) 一般做以下几点:
(1)变为小写(Lowercase)。
(2)将单词缩减为词根形式,如“cars ”到“car ”等。这种操作称为:stemming 。
(3)将单词转变为词根形式,如“drove ”到“drive ”等。这种操作称为:lemmatization 。
// TODO 这部分有点没搞非常清楚
(1)不知道是在步骤2中转为小写,还是在步骤3中
(2)不知道是在步骤3中添加同义词,还是在步骤2中。
不知道同义词的处理机制是什么?对于单向和双向同义词分别怎么处理
(3)不知道是在步骤2中去除停词,还是在步骤3中。
语言处理组件(linguistic processor)的结果称为词(Term) 。
在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”
第三步:将得到的词(Term)传给索引组件(Indexer)
索引 组件(Indexer)主要做以下几件事情:
(1)利用得到的词(Term)创建一个字典。
在我们的例子中字典如下:
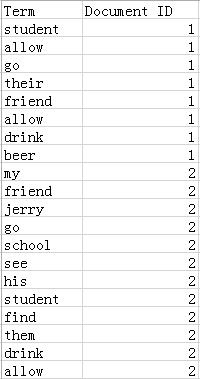
(2)对字典按字母顺序进行排序(这一点很重要)。
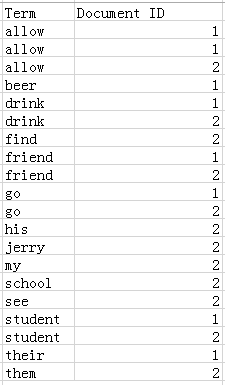
(3)合并相同的词(Term) 成为文档倒排(Posting List) 链表。
Lucence索引文件格式
基本copy https://blog.csdn.net/njpjsoftdev/article/details/54015485 。仅供学习
Lucene经多年演进优化,现在的一个索引文件结构如图所示,基本可以分为三个部分:词典、倒排表、正向文件、列式存储DocValues。

某一索引的单个shard上文件结构如下:

索引结构
Lucene现在采用的数据结构为FST (工具演示:http://examples.mikemccandless.com/fst.py?terms=&cmd=Build+it! ),它的特点就是:
1、词查找复杂度为O(len(str))
2、共享前缀、节省空间
3、内存存放前缀索引、磁盘存放后缀词块
这跟我们前面说到的词典结构三要素是一致的:1. 查询速度。2. 内存占用。3. 内存+磁盘结合。我们往索引库里插入四个单词abd、abe、acf、acg,看看它的索引文件内容。

tip部分,每列一个FST索引,所以会有多个FST,每个FST存放前缀和后缀块指针,这里前缀就为a、ab、ac。tim里面存放后缀块和词的其他信息如倒排表指针、TFDF等,doc文件里就为每个单词的倒排表。
所以它的检索过程分为三个步骤:
1. 内存加载tip文件,通过FST匹配前缀找到后缀词块位置。
2. 根据词块位置,读取磁盘中tim文件中后缀块并找到后缀和相应的倒排表位置信息。
3. 根据倒排表位置去doc文件中加载倒排表。
这里就会有两个问题,第一就是前缀如何计算,第二就是后缀如何写磁盘并通过FST定位,下面将描述下Lucene构建FST过程:
已知FST要求输入有序,所以Lucene会将解析出来的文档单词预先排序,然后构建FST,我们假设输入为abd,abd,acf,acg,那么整个构建过程如下:

- 插入abd时,没有输出。
- 插入abe时,计算出前缀ab,但此时不知道后续还不会有其他以ab为前缀的词,所以此时无输出。
- 插入acf时,因为是有序的,知道不会再有ab前缀的词了,这时就可以写tip和tim了,tim中写入后缀词块d、e和它们的倒排表位置ip_d,ip_e,tip中写入a,b和以ab为前缀的后缀词块位置(真实情况下会写入更多信息如词频等)。
- 插入acg时,计算出和acf共享前缀ac,这时输入已经结束,所有数据写入磁盘。tim中写入后缀词块f、g和相对应的倒排表位置,tip中写入c和以ac为前缀的后缀词块位置。
以上是一个简化过程,Lucene的FST实现的主要优化策略有:
- 最小后缀数。Lucene对写入tip的前缀有个最小后缀数要求,默认25,这时为了进一步减少内存使用。如果按照25的后缀数,那么就不存在ab、ac前缀,将只有一个跟节点,abd、abe、acf、acg将都作为后缀存在tim文件中。我们的10g的一个索引库,索引内存消耗只占20M左右。
- 前缀计算基于byte,而不是char,这样可以减少后缀数,防止后缀数太多,影响性能。如对宇(e9 b8 a2)、守(e9 b8 a3)、安(e9 b8
a4)这三个汉字,FST构建出来,不是只有根节点,三个汉字为后缀,而是从unicode码出发,以e9、b8为前缀,a2、a3、a4为后缀,如下图:

正向文件
正向文件指的就是原始文档,Lucene对原始文档也提供了存储功能,它存储特点就是分块+压缩,fdt文件就是存放原始文档的文件,它占了索引库90%的磁盘空间,fdx文件为索引文件,通过文档号(自增数字)快速得到文档位置,它们的文件结构如下:

fnm中为元信息存放了各列类型、列名、存储方式等信息。
fdt为文档值,里面一个chunk就是一个块,Lucene索引文档时,先缓存文档,缓存大于16KB时,就会把文档压缩存储。一个chunk包含了该chunk起始文档、多少个文档、压缩后的文档内容。
fdx为文档号索引,倒排表存放的时文档号,通过fdx才能快速定位到文档位置即chunk位置,它的索引结构比较简单,就是跳跃表结构,首先它会把1024个chunk归为一个block,每个block记载了起始文档值,block就相当于一级跳表。
所以查找文档,就分为三步:
第一步二分查找block,定位属于哪个block。
第二步就是根据从block里根据每个chunk的起始文档号,找到属于哪个chunk和chunk位置。
第三步就是去加载fdt的chunk,找到文档。这里还有一个细节就是存放chunk起始文档值和chunk位置不是简单的数组,而是采用了平均值压缩法。所以第N个chunk的起始文档值由 DocBase + AvgChunkDocs * n + DocBaseDeltas[n]恢复而来,而第N个chunk再fdt中的位置由 StartPointerBase + AvgChunkSize * n + StartPointerDeltas[n]恢复而来。
从上面分析可以看出,lucene对原始文件的存放是行是存储,并且为了提高空间利用率,是多文档一起压缩,因此取文档时需要读入和解压额外文档,因此取文档过程非常依赖随机IO,以及lucene虽然提供了取特定列,但从存储结构可以看出,并不会减少取文档时间。
列式存储DocValues
我们知道倒排索引能够解决从词到文档的快速映射,但当我们需要对检索结果进行分类、排序、数学计算等聚合操作时需要文档号到值的快速映射,而原先不管是倒排索引还是行式存储的文档都无法满足要求。
原先4.0版本之前,Lucene实现这种需求是通过FieldCache,它的原理是通过按列逆转倒排表将(field value ->doc)映射变成(doc -> field value)映射,但这种实现方法有着两大显著问题:
1. 构建时间长。
2. 内存占用大,易OutOfMemory,且影响垃圾回收。
因此4.0版本后Lucene推出了DocValues来解决这一问题,它和FieldCache一样,都为列式存储,但它有如下优点:
1. 预先构建,写入文件。
2. 基于映射文件来做,脱离JVM堆内存,系统调度缺页。
DocValues这种实现方法只比内存FieldCache慢大概10~25%,但稳定性却得到了极大提升。
Lucene目前有五种类型的DocValues:NUMERIC、BINARY、SORTED、SORTED_SET、SORTED_NUMERIC,针对每种类型Lucene都有特定的压缩方法。
如对NUMERIC类型即数字类型,数字类型压缩方法很多,如:增量、表压缩、最大公约数,根据数据特征选取不同压缩方法。
SORTED类型即字符串类型,压缩方法就是表压缩:预先对字符串字典排序分配数字ID,存储时只需存储字符串映射表,和数字数组即可,而这数字数组又可以采用NUMERIC压缩方法再压缩,图示如下:

这样就将原先的字符串数组变成数字数组,一是减少了空间,文件映射更有效率,二是原先变成访问方式变成固长访问。
对DocValues的应用,ElasticSearch功能实现地更系统、更完整,即ElasticSearch的Aggregations——聚合功能,它的聚合功能分为三类:
1. Metric -> 统计
典型功能:sum、min、max、avg、cardinality、percent等
2. Bucket ->分组
典型功能:日期直方图,分组,地理位置分区
3. Pipline -> 基于聚合再聚合
典型功能:基于各分组的平均值求最大值。
基于这些聚合功能,ElasticSearch不再局限与检索,而能够回答如下SQL的问题
select gender,count(*),avg(age) from employee where dept='sales' group by gender
销售部门男女人数、平均年龄是多少

- 从倒排索引中找出销售部门的倒排表。
- 根据倒排表去性别的DocValues里取出每个人对应的性别,并分组到Female和Male里。
- 根据分组情况和年龄DocValues,计算各分组人数和平均年龄
- 因为ElasticSearch是分区的,所以对每个分区的返回结果进行合并就是最终的结果。
上面就是ElasticSearch进行聚合的整体流程,也可以看出ElasticSearch做聚合的一个瓶颈就是最后一步的聚合只能单机聚合,也因此一些统计会有误差,比如count(*) group by producet limit 5,最终总数不是精确的。因为单点内存聚合,所以每个分区不可能返回所有分组统计信息,只能返回部分,汇总时就会导致最终结果不正确。















 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









