






整个JVM内存可分为2个部分,总共5个区域:
线程独占区
1. 程序计数器
程序计数器是一块内存较小的区域,作用是指示当前线程执行的字节码行号。字节码解释器工作时是通过改变这个计数器的值选取下一条要执行的字节码指令。这块区域内存较小,是唯一一块没有OutOfMemoryError的区域。
为什么需要程序计数器?
cpu执行多线程时,cpu会不断的切换正在执行的任务,在某一个确定的时刻,只会执行某一个线程的指令。在线程不断切换时,为了让线程能准确的记录当前正在执行的当前字节码指令的地址,就给每个线程都分配了一个程序计数器。
2. 虚拟机栈
虚拟机栈是由栈帧构成的,每个方法被执行时都会创建一个栈帧,这里的栈跟数据结构的栈是一个意思,当 Jvm 执行 a 方法时,会将 a 方法入栈,如果 a 调用了 b 方法,那么也将 b 方法入栈,由于栈是先进先出的,所以会先执行完 b 方法,再执行 a 方法。
栈帧又分为4个区域:
2.1 局部变量表
局部变量表存放的是在方法内部创建的局部变量和方法参数。对于基本数据类型,可以直接传值;对于引用类型的变量,存放的是对象的引用地址。因此,局部变量表的大小在编译期间是可以完全确定的。
2.2 操作数栈
用于保存计算过程中的计算结果,同时作为计算过程中变量临时的存储空间。
2.3 动态链接
每一个栈帧内部都包含一个指向运行时常量池中该栈帧所属方法的引用,目的是为了支持当前方法的代码能够实现动态链接。
这块区域的作用是什么?
一个类的所有方法,都会记录在方法区的方法表,举个例子:当 a 方法调用 b 方法时,会通过 b 这个符号引用转换到具体方法表的位置,变成直接引用。所以,动态链接的作用就是将符号引用转换为直接引用。直接引用的地址就存放在动态链接里面。
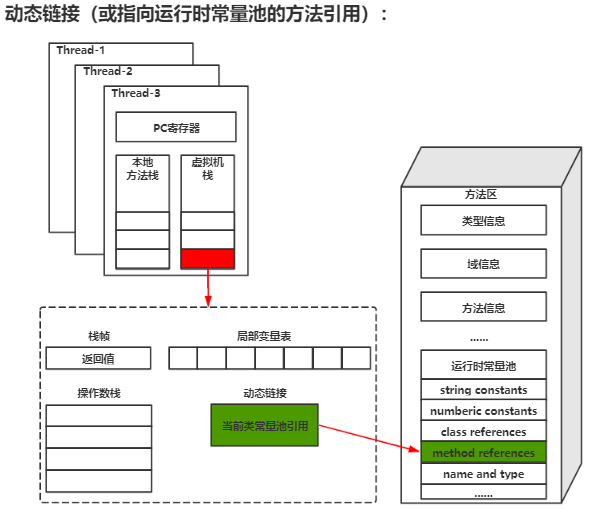
2.4 方法出口
当一个方法结束时,需要返回它之前被调用的地方,所以需要一块区域保存方法返回地址。
3. 本地方法栈
与虚拟机栈类似,只不过这块区域是为了本地方法服务的,也就是带有native标志的方法。
线程共有区
1. 堆
堆是JVM管理的内存中最大的一块,几乎所有的对象实例和数组都会存储在堆中。
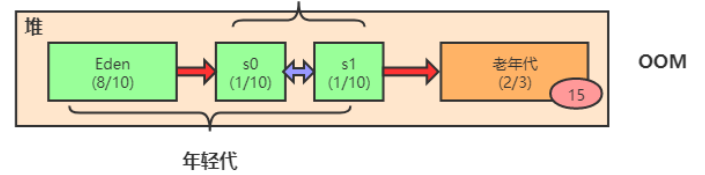
从内存回收的角度看,堆还可以分为 老年代(Old)、年轻代(Young)。年轻代还可以细分为 Eden、From Survior、To Survior。
默认情况下,老年代:年轻代 = 2 :1,Eden:Survivor0:Survivor1 = 8:1:1。
堆的最小值和最大值可以通过 -Xms(最小值) 和 -Xmx(最大值)指定。默认的最小值是操作系统物理内存的1/64,最大值是物理内存的 1/4。
2. 方法区
《深入理解JVM》写的是:方法区主要存储的是被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
即可以理解为以下几个部分:
2.1 类型信息
包含类的全限定名、父类的全限定名、类的修饰符等。
2.2 类型的常量池
在加载后的class文件中,维护者一个常量池(不同于方法区的运行时常量池)。这个常量池里存放在编译时生成的字面量和符号引用。
字面量: String类型的字符串值或者定义为final类型的常量的值。
符号引用: 类或者接口的全限定名,变量或者方法的名称等。
这部分内容在类加载时会被复制放到方法区的运行时常量池。
2.3 域信息
类型所有域相关的信息,域名、域类型、域的修饰符(public,private,protected,static,final,volatile,transiend的某个子集)和域的声明顺序。
2.4 方法信息
保存了所有方法的相关信息,修饰符、返回值类型、名称、参数列表、返回的异常信息、操作数栈、局部变量表大小以及声明顺序等。
2.5 类变量(静态变量)
JVM使用一个类之前,必须为每个非final类型的变量分配空间。如果是引用类型的变量,存放的是引用地址,具体的对象还是存放在堆中的。
这里只会存放非final类型的变量,因为final类型在编译期间就可以确定了,所以存在类的常量池中,在加载类的时候,会被复制到运行时常量池中。
对象内存分配机制
对象分配流程图:
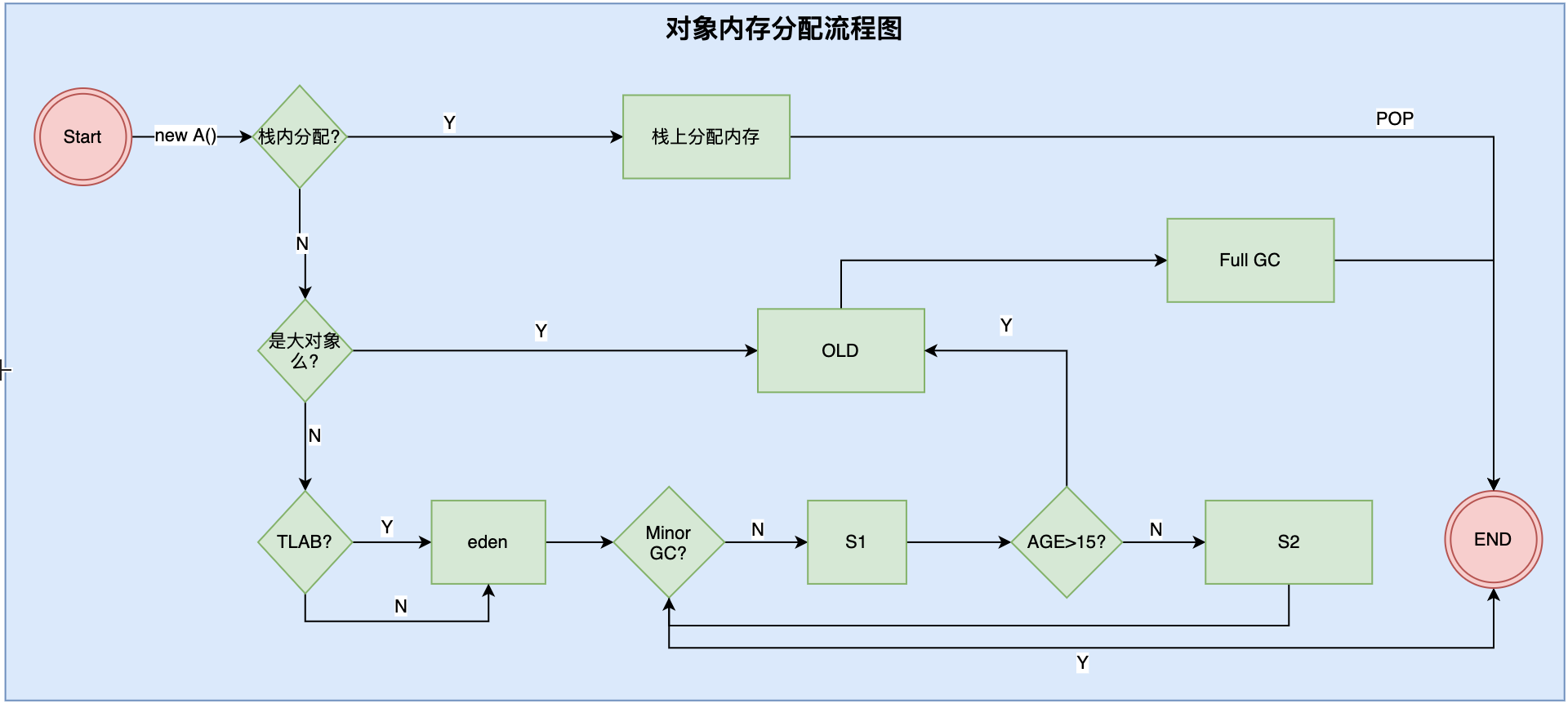
对象栈上分配
我们知道对象都是在堆上分配空间的,在堆上分配空间的对象有一个特点,如果想要让对象被回收,只能依靠GC通过分析出这个对象没有引用了然后进行回收。如果对象数量较多,会给GC造成压力,从而使应用性能降低。
为了减少临时对象在堆中分配的数量,JVM 可以通过逃逸分析确定该对象会不会被外部访问。如果不会,可以直接在栈上给对象分配内存,这块内存可以随着栈帧出栈而被回收,就可以减少GC的压力。
逃逸分析: 顾名思义,指对在方法内部定义的对象进行分析,分析是否会被外部方法引用。
public User test1() {
User user1 = new User();
user1.setId(1);
user1.setName("zhuge");
return user1;
}
public void test2() {
User user2 = new User();
user2.setId(1);
user2.setName("zhuge");
}
很显然 user1 这个对象存在被外部方法引用的可能性,不可以栈上分配内存,而 user2 就可以了。
JDK7之后逃逸分析(-XX:+DoEscapeAnalysis)是默认开启的,关闭的要使用(-XX:-DoEscapeAnalysis);
当对象确定可以在栈上分配后,那么就需要进行标量替换。
标量替换: 通过逃逸分析确定该对象不会被外部访问,并且可以被进一步分解时,JVM 不会创建该对象,而是将该对象的成员变量分解成被这个方法使用的成员变量替代。开启标量替换参数(-XX:+EliminateAllocations)。
标量: 指不可被进一步分解的变量,Java的基本数据类型就是变量。
综上所述,栈上分配是依赖 逃逸分析(-XX:+DoEscapeAnalysis) 和 标量替换(-XX:+EliminateAllocations)的。
对象在Eden分配
Eden与 Survivor的比例默认是 8:1:1。
**Minor Gc / Young Gc:**指年轻代的垃圾收集,频率高,耗时短;
Major Gc / Full Gc: 指年轻代、老年代、方法区的垃圾收集,速度慢。
对象大部分情况下是在Eden区分配的,当Eden区满了之后会触发一次Minor Gc,剩余存活的对象会被挪到空的Survivor区;下一次Minor Gc 时,回收Eden区和不为空的Survivor区的对象,剩余存活的对象挪到另外一块空的Survivor区。因为新生代的对象存活时间很短,大部分是朝生夕死的,所以 8:1:1的比例很合适。
Jvm默认会开启 -XX:+UseAdaptiveSizePolicy,会导致这个比例会自动变化。
大对象直接进入老年代
大对象: 指的是需要一大块连续空间的对象,如字符串、数组等。可以通过JVM 参数 -XX:PretenureSizeThreshold 设置大对象的大小。如果超过这个值,直接将这个对象放入Old区。
-XX:PretenureSizeThreshold 默认值是0,意思是无论对象有多大,除非在Eden区没有足够内存分配,都会现在Eden区创建。
为什么需要这个机制?
为了避免大对象内存的复制操作而降低Gc效率。
长期存活的对象进入老年代
前面提到,当一个对象经过第一轮Minor Gc,会这个对象设置对象年龄。当每经过一轮Minor Gc,从其中一块Survivor区挪到另外一块Survivor区时,虚拟机会给这个对象的对象年龄+1,当超过一定的年龄值(可通过-XX:MaxTenuringThreshold设置,默认是15),就会被挪到老年区。
对象动态年龄判断
如果在当前存放对象的Survivor区里,有一批对象的总大小大于这个 Survivor 区的50%(-XX:TargetSurvivorRatio 可以指定),那么会将在这块Survivor的年龄大于等于这批对象的最大年龄的存活对象直接转移至老年代中。这条规则是希望有可能长期存货的对象,尽早挪入老年代中。触发时机一般是在Minor Gc后。
例如,当有一批 年龄1 + 年龄2 + … + 年龄n 的对象超过了Survivor 区的50%,那么直接将对象年龄大于等于 n 的对象挪入老年代中。
老年代空间分配担保机制
年轻代每次Minor Gc 之前都会计算老年代的可用剩余空间。
如果年轻代的**所有对象(包括垃圾对象)**大小之和大于老年代的可用剩余空间,就会获取 “-XX:-HandlePromotionFailure” (1.8默认开启)这个参数是否开启。
如果这个参数开启了就会计算老年代的可用剩余空间是否大于之前每次 Minor Gc 后进入老年代的对象的平均大小。
如果参数没有开启或者计算后的结果是小于,那么就会触发一次 Full Gc,对年轻代和老年代垃圾回收,如果 Full Gc 后还是没有空间存放新的对象就会抛出 “OutOfMemoryEroor”。














 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









