







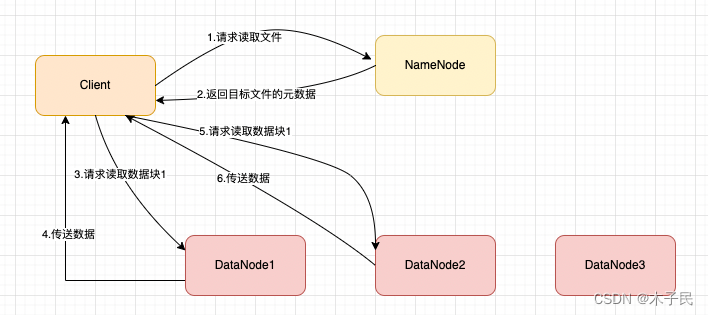
HDFS的读流程
1.HDFS采用的是“一次写入多次读取”的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。
2. client让NameNode获取该文件信息:所有的数据块,以及数据块对应的DataNode位置
3. client先从最近的DataNode获取数据块,然后将重复执行,获取到所有的数据块
4. 数据存储已经按照客户端与DataNode节点之间的距离进行了排序,距客户端越近的DataNode节点被放在最前面,客户端会优先从本地读取该数据块。
HDFS的写流程
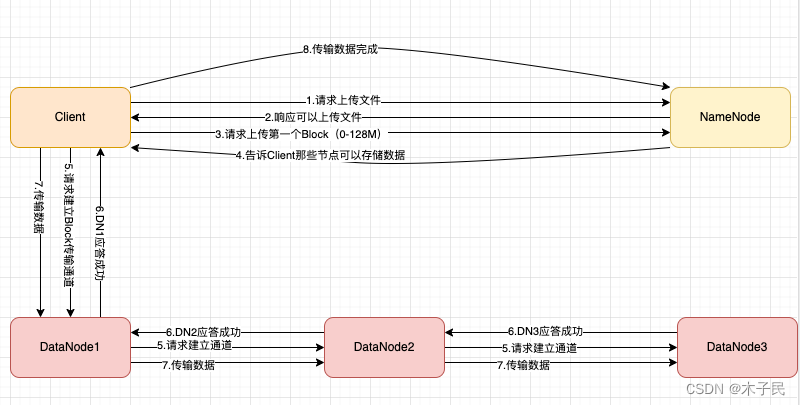
- HDFS中的存储单元是block。文件通常被分成64或128M(默认是128M)一块的数据块进行存储。与普通文件系统不同的是,在HDFS中,如果一个文件大小小于一个数据块的大小,它是不需要占用整个数据块的存储空间的。每一个block会在DataNode中有多个副本,一般分为三份
- NameNode根据存储数据块的地址进行排序,将数据推送给DataNode,直到将三份数据发送到DataNode中
- 当DataNode完成之后会向NameNode发送通知
- 所有文件块写入完成,NameNode收到通知发送到client端,让客户端关闭文件
- 客户端进行文件的分割,NameNode进行数据块分配DataNode地址,DataNode对数据进行存储















 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









