







K-means聚类算法简介

举个栗子
图一有ABCDE这五个点。
我们先随机选择两个点作为我们的初始聚类中心(簇中心点),标记为红点和黄点。
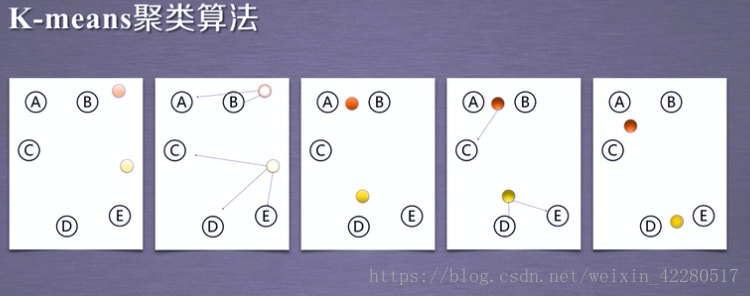
开始第一次聚类。对于所有点分别计算其到红点和黄点的距离,我们发现AB点到红点距离更近,而CDE三个点到黄点的距离更近。于是,AB为一簇,CDE为一簇。然后对于这两簇,分别计算簇内各点的均值,标记为新的红点和黄点(图三)。
开始第二次聚类。我们发现ABC点到红点距离更近,而DE点到黄点的距离更近。于是,ABC为一簇,DE为一簇。对于这两簇,分别计算簇内各点的均值,标记为新的红点和黄点(图五)。
开始第三次聚类。我们发现仍然是ABC为一簇,DE为一簇。计算新的簇中心点,发现与第二次聚类中心点一致。
结束。
sklean.cluster.KMeans方法
form sklearn.cluster import KMeans
import numpy as np
km = KMeans(n_clusters=3) # 分成三类
label = km.fit_predict(cityData) # cityData由31个城市的8个数据组成的list
expenses = np.sum(km.cluster_center_, axis=1) # 聚类中心点的数值(每一簇点各个属性的均值)加和
KMeans方法参数

Python 实现
'''
算法过程如下:
1)从N个数据随机选取K个数据作为质心
2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类
3)重新计算已经得到的各个类的质心
4)迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束
'''
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
import random
import numpy as np
data = [[1.0, 2.0], [3.0, 8.0], [2.0, 2.0], [1.0, 1.0], [5.0, 3.0],
[4.0, 8.0], [6.0, 3.0], [5.0, 4.0], [6.0, 4.0], [7.0, 5.0]]
def findCentroids(dataset, k):
return random.sample(dataset,k)
def calculateDis(dataset, centroids):
values = [[],[],[],[]]
distances = [ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









