






支付宝内搜索 9155838 即可领现金红包 每天都能领哦
10:19:17
朋友有个站的文章内容有时候会显示乱码,让我给看看。
拿到服务器权限后,我上去一看,php都几百个,觉得有点头大,感觉无从查起,并且我也不想在本地重新布置环境,要下载代码和数据库好麻烦。
就只能在线调试了,改了点东西就可能500了,坑爹的是在php.ini里面打开报错,重启后仍然看不到错误信息,在nginx日志和php日志里面也看不到错误信息,不知服务器配置是怎么设置的,但也不想去研究配置了 -_-||
凭着我三脚猫的功夫经过大半天的排查修改,将近凌晨的时候终于在几十个模块中将问题定位到str_replace函数上面了:
问题出在有一行str_replace是将全角空格替换为半角空格的代码(即下图第9行),将其注释即搞定。
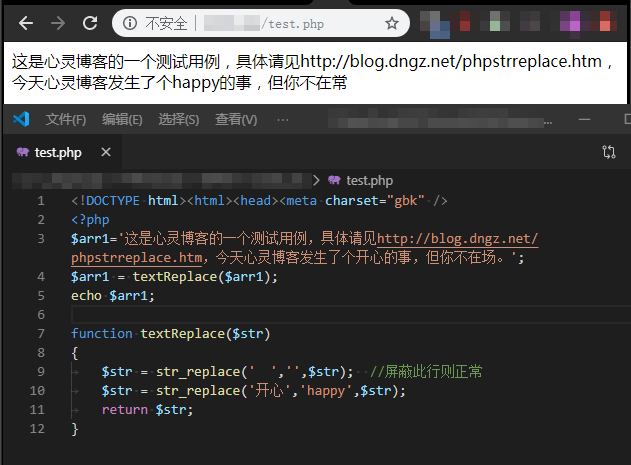
现在将问题现象重新整理重现一下,将无关代码全部剔除,只提取最关键代码,又发现一个新的现象:原文本里面的“场。”经过替换后会变成“常”,这真是有点奇怪,如图:
这时,没出现乱码的原因是我将mb_substr函数删掉了,因为这个时候乱码的问题已经不重要了,一个字变成另一个没替换过的字的问题才更诡异。
经测试任何版本的php都有此奇异现象
简要代码如下(php文件编码为gb2312):
header("Content-type:text/html; charset=gbk");
$arr1='这是心灵博客的一个测试用例,具体请见http://blog.dngz.net/phpstrreplace.htm,今天心灵博客发生了个开心的事,但你不在场。';
$arr1 = textReplace($arr1);
echo $arr1;
function textReplace($str)
{
$str = str_replace(' ','',$str); //屏蔽此行则正常
$str = str_replace('开心','happy',$str);
return $str;
}
php技术大佬帮我看看吧,但愿不是什么php对中文支持不够友好的说法……
2019-11-22 23:00:38 补充:
产生这个问题的原因:
将这几个字的编码转换一下:
场。 常
编码转码后:
%b3%a1 %a1%a3 %a1%a1 %b3%a3
“场”的后半部分和句号的前半部分正好组成全角的%a1%a1被替换为空,然后剩余部分正好组成%b3%a3,正好是“常”的编码。
感谢php大神自由勇给出的解决方法:我有时连续几个月每天PHP编程10小时,很多时候都在处理这类问题。
这个问题PHP短期内无法处理,因为它是属于全角字符的编码的原因。以前写过7年的ASP程序,ASP、JavaScript就不存在这个问题,它们都是把全角字符认为是一个字符。而PHP在GBK/GB2312下,把全角字符拆分成2个字符,UTF-8编码下,拆分成3个字符。
如果要专项替换这个全角空格,还有一个办法,不使用str_replace,稍微有点复杂,但是这个方法(公式)在项目中会特别常用。
以GB2312编码为例,让循环程序检索整个字符串,进行累加。例如:
$a1是字符串:
$a1='这是心灵博客的一个测试用 例';
$j=strlen($a1)-1;$c1='';
for ($i=0;$i<=$j;$i++){$a=$a1[$i];if (ord($a)>126){$a=$a.$a1[$i+1];$i++;}
if ($a==' ') $a='';
$c1.=$a;
}
echo $c1;?>
运行结果:这是心灵博客的一个测试用例
完美替换掉了全角空格。
当出现全角字符时,ord的值会大于126时,说明此字符一定是全角汉字,此时$i++会向下跳过一个半角字符。
同理,如果是UTF-8编码,则改为:
if (ord($a)>126){$a=$a.$a1[$i+1].$a1[$i+2];$i+=2;}
更新于:2019-11-22 23:05:04 栏目:网站周边/代码 关键词:php,php代码,str_replace
本站使用「署名 4.0 国际」创作共享协议,可转载、引用,但需署名作者且注明文章出处
推荐文章















 376
376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









