






本讲会从以下三部分内容进行介绍:预处理和隐私求交,决策树模型和线性回归模型,神经网络算法。
一、预处理和隐私求交
1、预处理:DataFrame 和 FedNdarray
1)DataFrame
DataFrame跟Pandas的DataFrame API类似,是一个联邦表格数据的封装,由多参与方的数据块构成,支持多种切分模式,即数据水平切分(HDataFrame,每一方特征一致,但是有各自的样本)、垂直切分(VDataFrame,每一方有各自的特征,但是它们的样本是对齐的,一般是先经过PSI对齐后得到的一组数据)和混合切分(MixDataFrame,既有水平切分又有垂直切分)。
2)FedNdarray
是联邦ndarray的封装,由多参与方的数据块构成,每一方的数据是用Numpy的ndarray来表示,支持水平切分和垂直切分,但不支持混合切分。对应统一的API是:FedNdarray。
预处理组件以上述两个API为基础,进行预处理。DataFrame 和 FedNdarray各自提供了一些读写API供直接使用,首先加载到内存,之后既可以用DataFrame的API处理数据,也可以用sf.preprocessing包做各种预处理,如下图所示的例子,第一个是缺失值填充,通过df.fillna方法,将NAN值填充为10,第二个例子是标准化,使用了MinMaxScaler组件,把某一列的值变成0~1之间,跟sklearn用法一样,先进行初始化,然后调用transform把dataframe的列传入,这样转换完成之后,最小值变为0.0,最大值变为1.0。类似的preprocessing组件还有很多,具体可以参考文档中的数据加载教程和数据预处理教程。
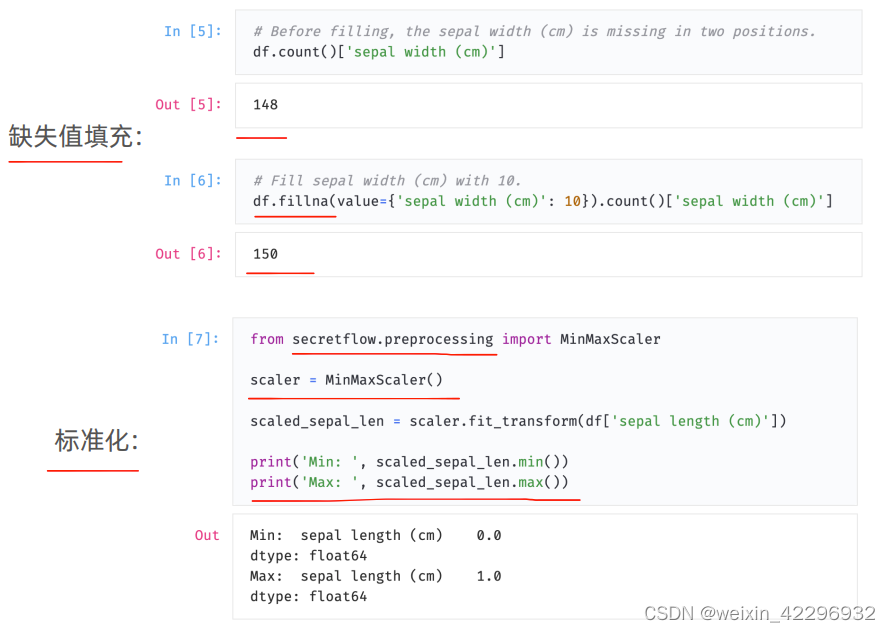
另外,一些预处理算子会计算并公开用于辅助计算的统计值,或者一些统计接口本身就会计算和公开统计值,请在使用前仔细评估这些统计值是否包含隐私信息。例如上图minmax调用,本身就会公开这列的最大值和最小值,需要评估是否有风险。另外对于MinMaxScaler,如果要做标准化转换,需要把最大值/最小值计算出来,之后用于辅助计算。Scaler中本身就会包含最大值/最小值,无论是否进行最大/最小值的计算,最大/最小值被隐式的透露出来了,所以在使用Scaler之前,需要先确认是否可以公开最大/最小值。
2、隐私求交:PSI
所谓求交,即获取两份数据内容交集的算法,而隐私求交,是使用密码学方法,在求交过程中不泄露任务交集以外的任何信息。
在VDataFrame,即垂直拆分场景中,隐私求交常用于第一步的数据对齐,然后进一步做数据分析或者机器学习建模。
隐语PSI有两种使用方式,一是spu.psi等相关接口,二是vdataframe的读取接口,这两种使用方式调用的是相同的psi kernel,完全等价。
隐语支持多种 PSI 算法,可根据参与方数量、带宽、算力、数据不平衡度等不同场景合理选择,具体可以参考官方文档。
二、决策树模型和线性回归模型
1、决策树模型
隐语支持多种决策树算法(XGB),同时支持回归和二分类训练,可根据使用场景和安全性需求选用。
隐语支持两大类使用场景,一是垂直切分场景(所有数据方样本对齐(一致),但是各自有各自的特征,拥有样本的不同特征),该场景下有两种算法,分别是SS-XGB和SecureBoost,前者是基于可证安全的MPC协议来实现的,安全性更高,但是通信成本也更高,一般会更慢,后者是联邦算法,计算量更大,但是通信量小很多,通常更快一些。二是水平切分场景,该场景下使用水平联邦XGBoost,它不是可证安全的,而是一个联邦算法,中间有部份的信息泄漏,具体可以参考官网。
2、线性回归模型
隐语支持多种线性回归模型,满足不同的使用场景,并有一些针对性的优化。具体如下图所示:

三、神经网络算法
根据使用场景不同,隐语提供了两种神经网络算法,即水平联邦学习,垂直拆分学习,并分别提供FLModel和SLModel两套API。两者都属于非可证安全算法,都是属于联邦学习类型的算法,在训练过程中,会泄漏部份中间信息,其安全性需要根据场景具体分析,并可以通过一些安全加固组件,例如安全聚合、差分隐私、稀疏化等,进行安全性的加强。
1、水平联邦学习
隐语提供的水平联邦学习FLModel是一个通用的范式,而不是一个具体的模型或算法,可以自由的定义模型和训练参数。目前FLModel支持TensorFlow和PyTorch两种后端,可以使用 tf 或 torch 原生的方式编写模型代码,然后使用FLModel 训练。也可以直接使用各种封装好的模型库,比如:torchvision 和 tf.keras.applications。
FLModel是SecretFlow提供的联邦学习的逻辑抽象,也是面向用户的统一接口。FLModel封装了联邦学习框架下需要的各种能力,包括数据处理,训练策略,聚合逻辑等,用户可以通过FLModel接口方便快速的将已有的明文计算模型,通过简单的迁移,快速形成联邦学习能力,低学习成本的联合多方建立联合模型。
2、垂直拆分学习
隐语提供的垂直拆分学习 SLModel 同样是一个通用的范式,可以自由的定义模型和训练参数,SLModel 同样支持 TensorFlow 和 PyTorch 两种后端,可以使用 tf 或 torch 原生的方式编写模型代码,然后使用 SLModel 训练。与水平联邦相比,垂直拆分学习的架构略有不同,其模型被拆分成 2 份、3 份或者更多,分别分布在不同的参与方。建模时需要针对拆分学习架构重新设计模型结构。
SLModel专注面向垂直场景的联邦学习建模,在SLModel中我们提供了多种后端的统一抽象,提供了面向隐私保护的聚合层,使用MPC技术来加固联邦学习,还提供了DP模块用于数据扰动。我们提供了用于提升效率的异构拆分算法,流水线训练策略,还提供了数据稀疏化和量化策略。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









