







今天一起来学习把网页版文章下载到本地电脑上。
前面讲过,请求网页的流程是浏览器先向服务器请求html,服务器返回html,浏览器分析这个html,发现html中还需要一堆的js,css,图片,然后浏览器再去下载这些文件,最终组装成一个完整的html页面。
所以,第一步,要把这个html下载下来。
是时候请出大家期待已久的python了,我在讲解的过程中只列出核心代码,完整代码会列在文章最后,所以强烈建议先把整篇文章看完了再动手自己敲代码。其他文章也是相同的逻辑,以后不再重复。
需要用到一个鼎鼎大名的第三方库 requests ,用它来模拟浏览器给微信服务器发送请求和接收请求。
那么发送的请求中都要包含什么内容呢?
上文介绍chrome开发者工具时提过这个问题,奥秘在Headers这个标签中,见下图,理论上来讲chrome浏览器发送了什么我们的最好就原样照着用python发送什么,即把下图所示的General 和 Request Headers 块中的参数全都发送出去。但多数时候并不需要这样,特别是对于get请求,一般只需要少数几个参数即可,但是请注意User-Agent这一项一定要改得跟chrome一样。其他细节不再多述,过后您操作的多了自然会明白。
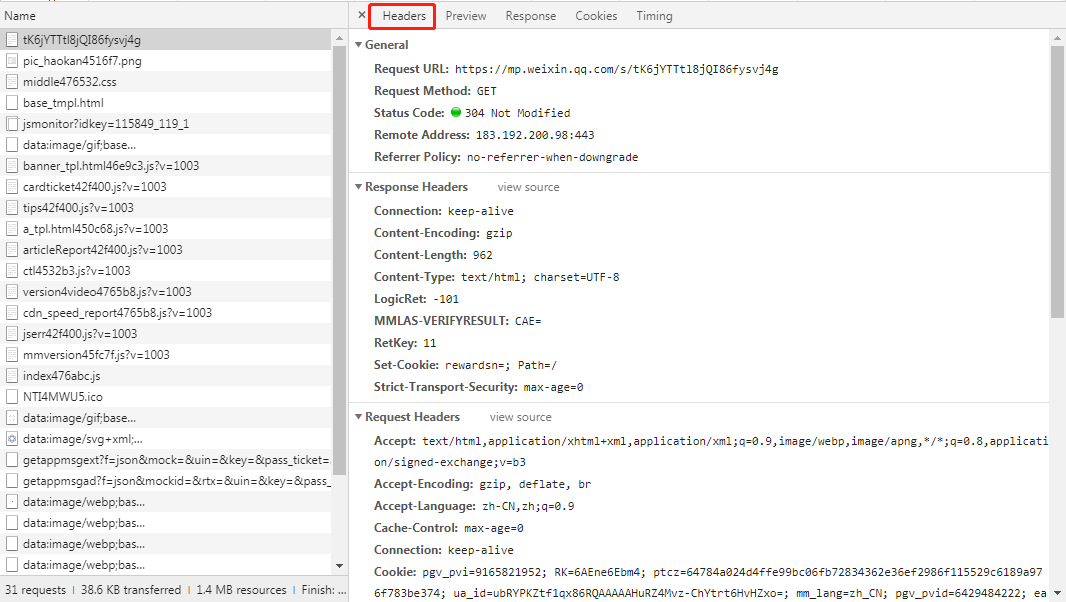
简单的注释会直接在代码中列出,复杂的会在代码后面用文字再解释,另外本文是一份原稿发布在多个平台,可能有的平台显示代码会有缩进错乱的问题,当你发现运行代码出错时请秉持“尽信书不如无书”的批判态度。
#下面这一行一定别忘了import requests#定义一个保存文件的函数def SaveFile(fpath,fileContent): with open(fpath, 'w', encoding='utf-8') as f: f.write(fileContent)#定义一个下载url网页并保存的方法def DownLoadHtml(url): #构造请求头 headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36', 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Connection':'keep-alive', 'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3' } #模拟浏览器发送请求 response = requ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3413
3413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









