









voice_activity_detection
Audio Split 基于双门限法的语音端点检测及语音分割
代码在我的github上voice_activity_detection
如果您觉得有一点点用,请隔空比个心(或者,去我的github上点一下 “Star” 也可以~)
根据短时能量和过零率, 基于双门限法的语音端点检测及语音分割
直接运行audio_split.py,会对./raw_audio文件夹下的所有音频文件进行分割:
- 首先对原音频转成16kHz,16bit,PCM格式,单通道的.wav文件,保存在./convert2wav文件夹下;
- 再对转换后的文件进行第一次分割,保存在./detected_split1文件夹下;
- 再次对分割后的文件分割,保存在./detected_split2文件夹下;
- 最后根据时长限制,加速音频,保存在./duration_limit文件夹下。
以上各步骤可选,参数均可自由设置,程序里有详细注释。
另外,对于acoustic_feature.py,请看我另一个仓库:声学特征提取
关于./raw_audio文件夹下的两个示例文件,运行程序会有两张plot输出:
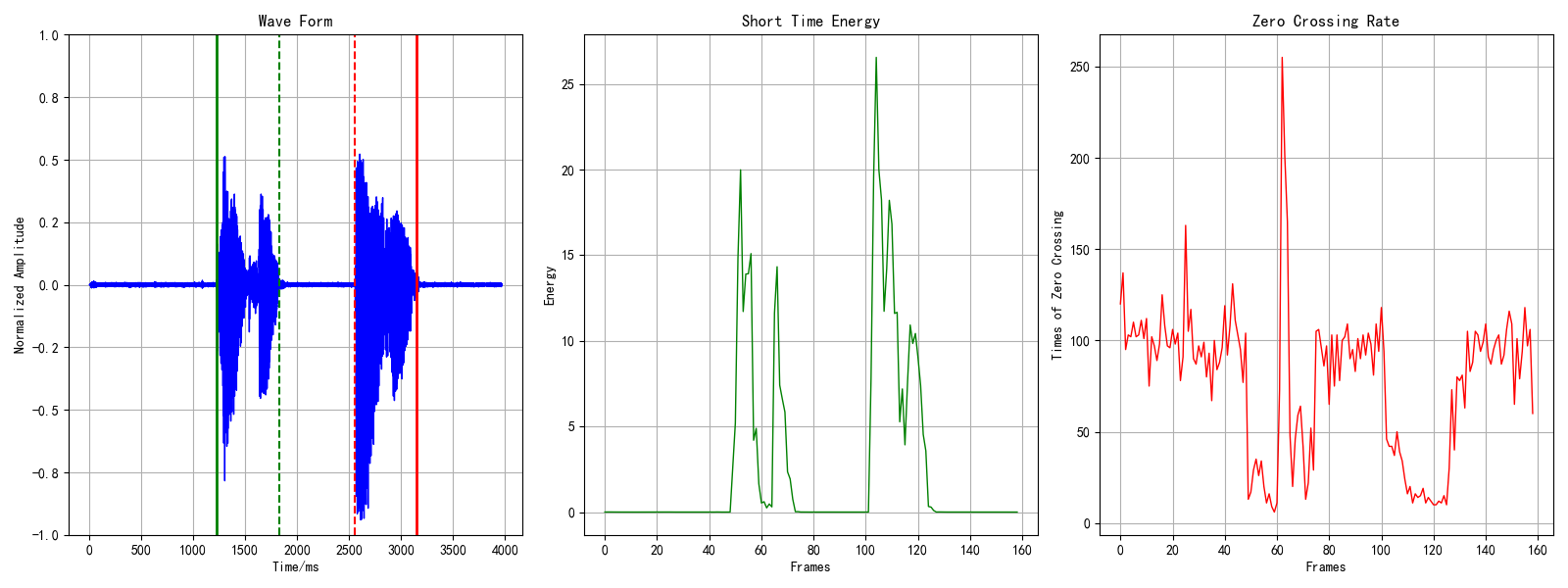
图1 汉语:“蓝天 白云”的语音端点检测
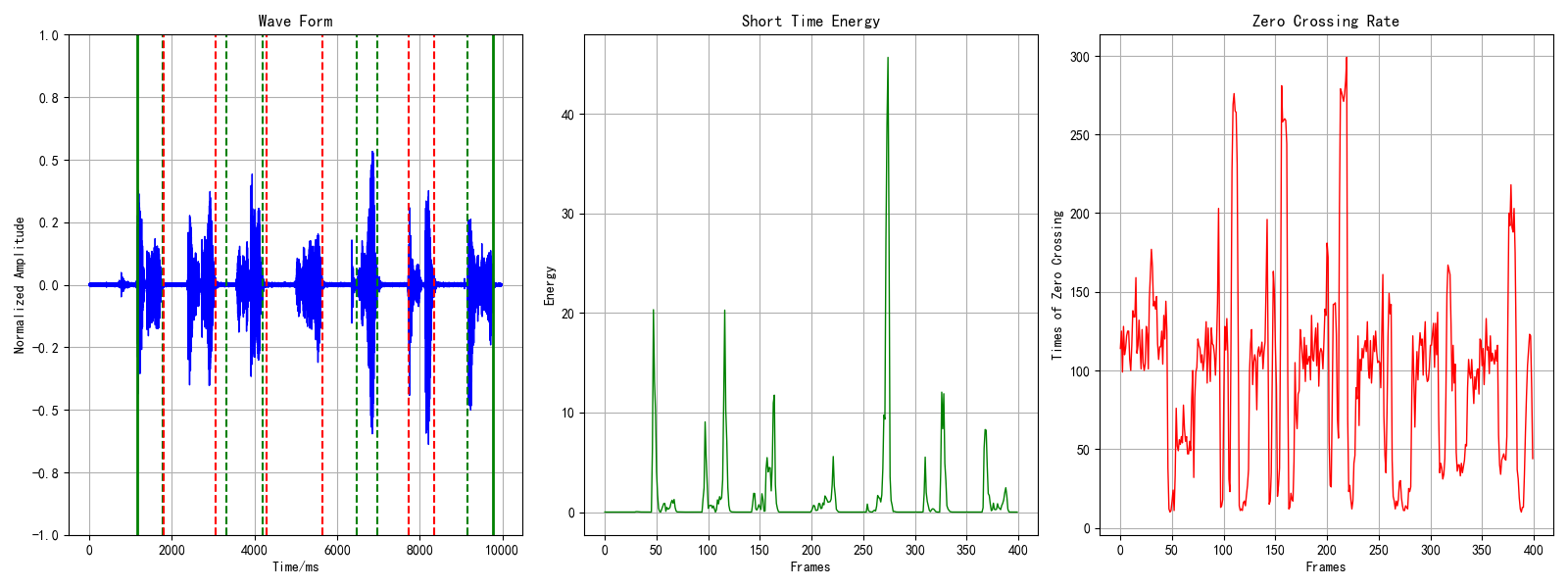
图2 一些汉语数字的语音端点检测
Python Import
关于本程序的依赖库(其中Librosa最好和我使用的版本一致,其他版本都没测试过):
- Librosa-0.7.2
- Numpy-1.18.1
- matplotlib-3.1.3
- Scipy-1.4.1
- Soundfile-0.9.0
License 开源许可协议
赞助
如果你喜欢本程序,并且它对你有些许帮助,欢迎给我打赏一杯奶茶哈~
微信:

支付宝:
















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









