







问题1描述:
Spark计算比MapReduce快的根本原因在于DAG计算模型。一般而言,DAG相比Hadoop的MapReduce在大多数情况下可以减少shuffle次数(怎么体现?)
解答:
- Spark的DAGScheduler相当于一个改进版的MapReduce,如果计算不涉及与其他节点进行数据交换,Spark可以在内存中一次性完成这些操作,也就是中间结果无须落盘,减少了磁盘IO的操作。但是,如果计算过程中涉及数据交换,Spark也是会把shuffle的数据写磁盘的!!!
- 有同学提到,Spark是基于内存的计算,所以快,这也不是主要原因,要对数据做计算,必然得加载到内存,Hadoop也是如此,只不过Spark支持将需要反复用到的数据给Cache到内存中,减少数据加载耗时,所以Spark跑机器学习算法比较在行(需要对数据进行反复迭代)。Spark基于磁盘的计算依然也是比Hadoop快。
- 刚刚提到了Spark的DAGScheduler是个改进版的MapReduce,所以Spark天生适合做批处理的任务。而不是某些同学说的:Hadoop更适合做批处理,Spark更适合做需要反复迭代的计算。
- Hadoop的MapReduce相比Spark真是没啥优势了。但是他的HDFS还是业界的大数据存储标准。
问题2描述:
Spark vs MapReduce ≠ 内存 vs 磁盘
解答:
其实Spark和MapReduce的计算都发生在内存中,区别在于:
- MapReduce通常需要将计算的中间结果写入磁盘,然后还要读取磁盘,从而导致了频繁的磁盘IO。
- Spark则不需要将计算的中间结果写入磁盘,这得益于Spark的RDD(弹性分布式数据集,很强大)和DAG(有向无环图),其中DAG记录了job的stage以及在job执行过程中父RDD和子RDD之间的依赖关系。中间结果能够以RDD的形式存放在内存中,且能够从DAG中恢复,大大减少了磁盘IO。
问题3描述:
Spark vs MapReduce Shuffle的不同
解答:
Spark和MapReduce在计算过程中通常都不可避免的会进行Shuffle
- 两者至少有一点不同:
MapReduce在Shuffle时需要花费大量时间进行排序,排序在MapReduce的Shuffle中似乎是不可避免的;Spark在Shuffle时则只有部分场景才需要排序,支持基于Hash的分布式聚合,更加省时;
问题4描述:
多进程模型 vs 多线程模型的区别
解答:
MapReduce采用了多进程模型,而Spark采用了多线程模型。
- 多进程模型的好处是便于细粒度控制每个任务占用的资源,但每次任务的启动都会消耗一定的启动时间。就是说MapReduce的Map Task和Reduce Task是进程级别的
- Spark Task则是基于线程模型的
- 就是说mapreduce 中的 map 和 reduce 都是 jvm 进程,每次启动都需要重新申请资源,消耗了不必要的时间(假设容器启动时间大概1s,如果有1200个block,那么单独启动map进程事件就需要20分钟)
- Spark则是通过复用线程池中的线程来减少启动、关闭task所需要的开销。(多线程模型也有缺点,由于同节点上所有任务运行在一个进程中,因此,会出现严重的资源争用,难以细粒度控制每个任务占用资源)
问题5描述:
这俩根本没啥可比的,能够单MR做完的任务,Spark未必比MR快。至于迭代不迭代的并不是关键,其实你在Mapper里对数据做N个操作基本等价于N个窄依赖RDD的连接。
所以说真要比,也是多个MR组成的复杂Job来和Spark比。
解答:
- MR由于其计算粒度的设计问题,在进行需要多次MR组合的计算时,每次MR除了Shuffle的磁盘开销外,Reduce之后也会写到磁盘。
- 而Spark的DAG实质上就是把计算和计算之间的编排变得更为细致紧密,使得很多MR任务中需要落盘的非Shuffle操作得以在内存中直接参与后续的运算,并且由于算子粒度和算子之间的逻辑关系使得其易于由框架自动地优化(换言之编排得好的MR其实也可以做到)。
- 另外在进行复杂计算任务的时候,Spark的错误恢复机制在很多场景会比MR的错误恢复机制的代价低,这也是性能提升的一个点。
- 迭代计算是spark最开始亮相时的看家本领,第一是避免了不必要的数据落盘,第二则是容错的机制以及缓存节点的合理搭配使得重计算的代价低很多,而且缓存可以在内存。mr和spark都是分片后读数据的,这点没什么区别。至于快100倍……论文这种东西
问题6描述:
mapreduce框架和spark的区别
解答:
-
要想明白这个问题,需要对mapreduce的运算模型有所理解
-
mapreduce模型(不完全等同mapreduce框架哦),是一个分布式运算模型;它的思想可以通过一个简单的wordcount例子来说明:
-
需求:有大量的文件,需要统计这些文件中每一个单词出现的次数
-
在分布式计算里面:可以把整批数据,划分成N部分,然后N个task程序,分布在很多台机器上,分别读取这N部分的数据来计算,但你很快就会发现,这些task都得不到最终结果(因为每个task都只看到了局部数据)!自然就想到,这第一批的N个task程序,可以把自己看到的单词,像“发牌”一样,有所选择地将单词发给下一批的M个task程序,只要保证相同单词发给相同的下游task即可,下游的task就能各自运行各自统计自己收到的单词并计数输出结果
-
上述过程,就被抽象成了两个运算过程,第一批task属于map过程,而第二批task属于reduce过程
-
-
mapreduce框架中,一个程序只能拥有一个map一个reduce的过程,如果运算逻辑很复杂,一个map+一个reduce是表述不出来的,可能就需要多个map-reduce的过程;mapreduce框架想要做到这个事情,就需要把第一个map-reduce过程产生的结果,写入HDFS,然后由第二个map-reduce过程去hdfs读取后计算,完成后又将结果写入HDFS,再交由第三个map-reduce过程去计算! 重点!!! 这样一来,一个复杂的运算,在mapreduce框架中可能就会发生很多次写入并读取HDFS的操作,而读写HDFS是很慢的事情
-
spark框架,则可以把上面的mapreduce-mapreduce-mapreduce的过程,连续执行,不需要反复落地到HDFS,这样就会比mapreduce快很多啦
-
还有一个,比如一个复杂逻辑中 ,一个map-reduce产生的结果A,如果在后续的map-reduce过程中需要反复用到,spark可以把A缓存到内存中,这样后续的map-reduce过程就只需要从内存中读取A即可,也会加快速度
所以,spark比mapreduce快,就是上述的两点
- 减少磁盘 I/O:随着实时大数据应用越来越多,Hadoop 作为离线的高吞吐、低响应框架已不 能满足这类需求。Hadoop MapReduce 的 map 端将中间输出和结果存储在磁盘中,reduce 端 又需要从磁盘读写中间结果,势必造成磁盘 IO 成为瓶颈。Spark 允许将 map 端的中间输出 和结果存储在内存中,reduce 端在拉取中间结果时避免了大量的磁盘 I/O。
- 增加并行度:由于将中间结果写到磁盘与从磁盘读取中间结果属于不同的环节,Hadoop 将 它们简单的通过串行执行衔接起来。Spark 把不同的环节抽象为 Stage,允许多个 Stage 既可 以串行执行,又可以并行执行
- 避免重新计算:当 Stage 中某个分区的 Task 执行失败后,会重新对此 Stage 调度,但在重新 调度的时候会过滤已经执行成功的分区任务,所以不会造成重复计算和资源浪费。
以上内容搬砖自简书,感觉不错的答案。
链接:https://www.jianshu.com/p/5f9f4ca10414
在此补充SparkShuffle的知识,对理解上述问题是个很好的补充
- 划分stage时,最后一个stage称为ResultStage,之前的所有stage称为ShuffleMapStage,ShuffleMapStage的结束伴随着shuffle文件的写磁盘,意味着ResultStage也需要从磁盘上读取这些文件。
- shuffle包括四个:未优化的HashShuffle、优化后的HashShuffle、SortShuffle、bypass SortShuffle。
-
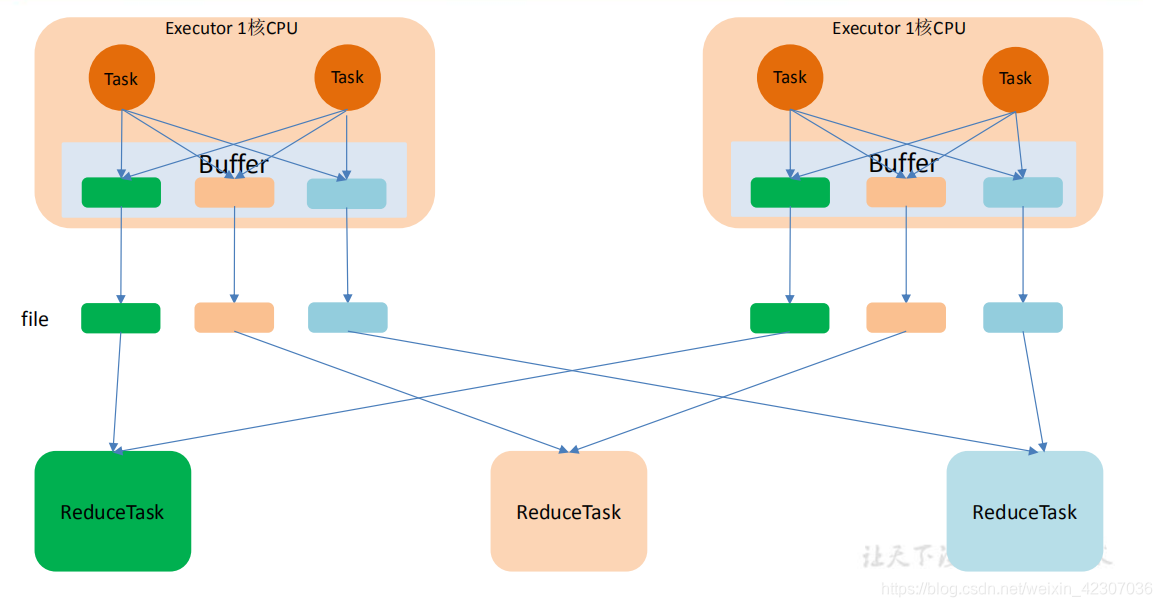
其中前两个的区别是,优化后的HashShuffle会有一个buffer的合并机制。
- 未优化的HashShuffle
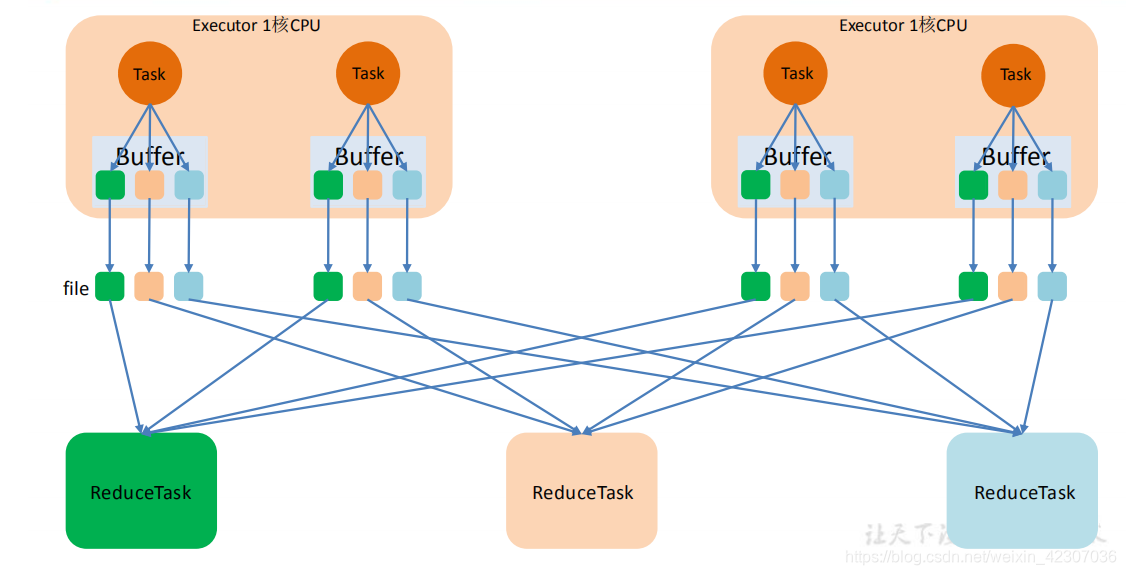
- 优化后的HashShuffle
- 未优化的HashShuffle
-
后两个的区别是,bypass SortShuffle不会在shuffle write过程中进行排序,从而节省了排序的性能开销。写入磁盘文件通过缓冲区溢写的方式,每次溢写都会产生一个磁盘文件,默认批次是10000条,数据会以每批10000条写入到磁盘中,也就是说一个task过程中会产生多个临时文件。要注意bypass运行机制的触发条件是:
- 1.shuffle reduce task数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值,默认是200;
- 2.不是聚合类的shuffle算子(比如reduceByKey)
-
SortShuffle
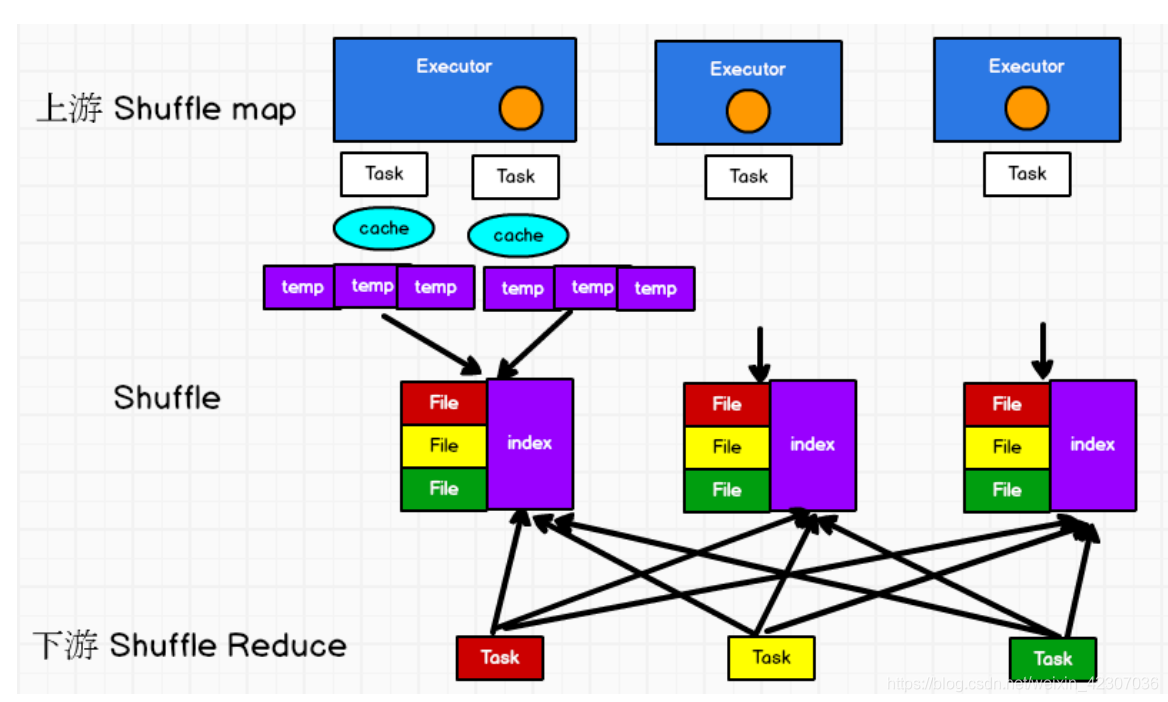
-
bypass SortShuffle和未优化的HashShuffle:它们的磁盘写机制实质上是一模一样的,因为都要创建数量惊人的磁盘文件,只是前者会在每个task任务的最后做一个磁盘文件的合并,同时单独写一个索引文件,来标注ResultStage阶段的各个task的数据在磁盘文件的的索引。因此少量的磁盘文件让bypass SortShuffle的shuffle read的性能更好
-


















 3629
3629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









